
Gemini's 3 Deep Think Funktion wird deutlich stärker
Google verbessert die Denkfähigkeit seiner KI für Wissenschaft und Programmierung durch längere Rechenzeit.

Google DeepMind spendiert Gemini 3 Deep Think ein starkes Update, welches spezifisch auf wissenschaftliche und mathematische Problemlösungen ausgelegt ist. Der Fokus liegt auf verstärkten Reasoning-Fähigkeiten für Forschung und Engineering, statt auf schneller Chat-Interaktion.
Fokus auf langsames "Denken" statt schneller Antworten
Google positioniert das Update weniger als generellen Modellwechsel, sondern als gezielte Weiterentwicklung der "Deep Think"-Funktionalität innerhalb der Gemini-3-Familie. Technisch basiert dies auf einer intensivierten Nutzung von "Inference-Time-Compute". Das System investiert mehr Rechenleistung in die Phase der Antwortgenerierung, um Lösungswege intern zu simulieren, zu verwerfen und neu zu bewerten, bevor eine Ausgabe erfolgt.
Dieser Ansatz soll vor allem in Disziplinen greifen, die keine Fehler tolerieren. Während klassische Sprachmodelle oft statistisch wahrscheinliche Antworten bevorzugen, erzwingt der aktualisierte Denkmodus eine logische Validierung. Für Nutzer bedeutet dies längere Wartezeiten, die jedoch in Szenarien wie der theoretischen Physik oder der Entwicklung komplexer Algorithmen durch eine höhere Verlässlichkeit gerechtfertigt sein sollen.
Anzeige
Benchmarks zeigen deutlichen Sprung bei Logik-Aufgaben
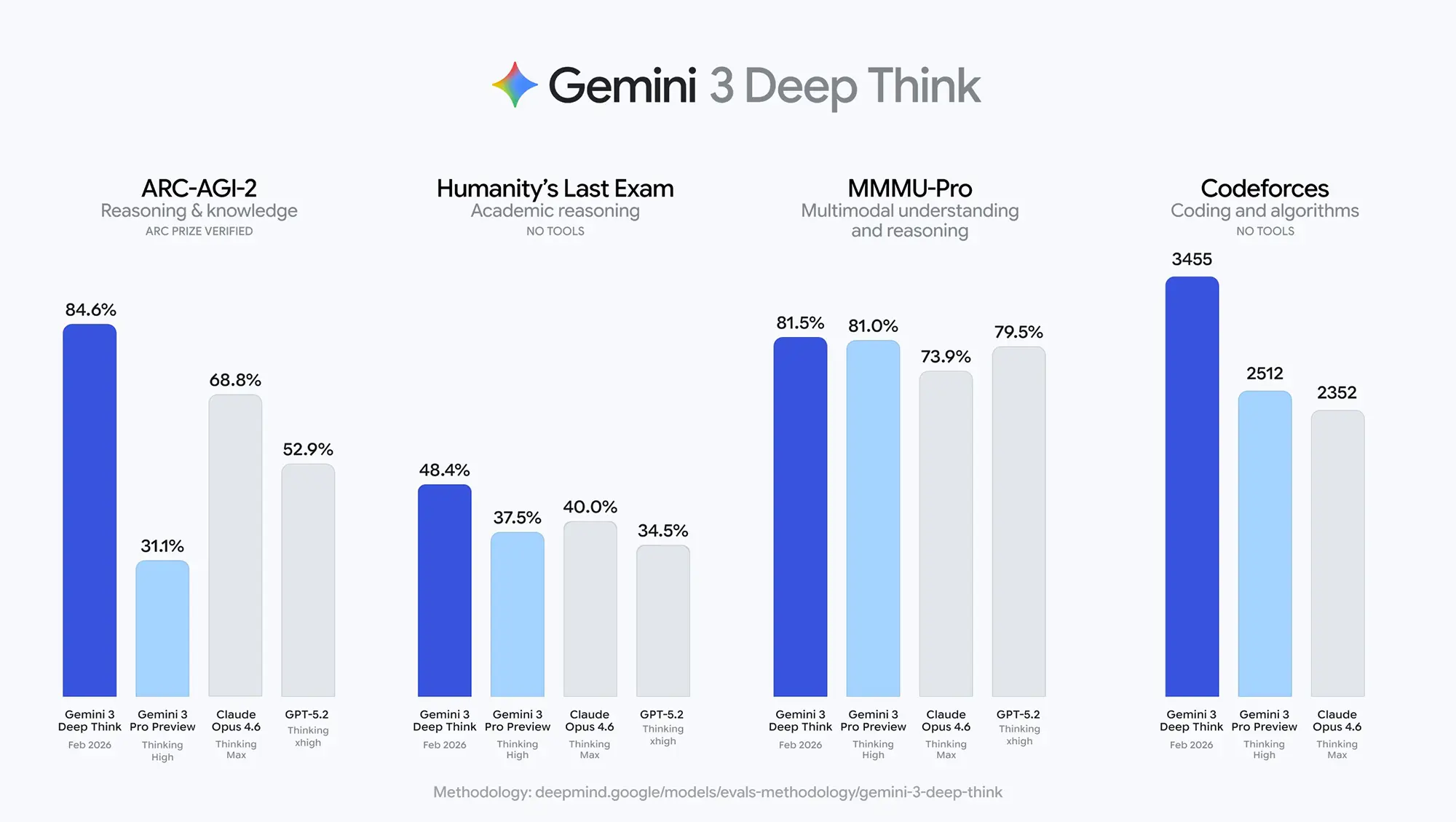
Die von Google veröffentlichten Leistungsdaten zeigen im direkten Vergleich mit den Konkurrenzmodellen Claude Opus 4.6 und GPT-5.2 teils massive Abstände in spezialisierten Testverfahren. Besonders im Bereich des abstrakten Schlussfolgerns sticht das Modell hervor.
Im ARC-AGI-2 Benchmark, der die Fähigkeit zur Lösung neuartiger visueller Rätsel ohne vorheriges Training misst, erreicht Gemini 3 Deep Think einen Wert von 84,6 Prozent. Zum Vergleich: Das Vorgängermodell Gemini 3 Pro Preview lag hier bei lediglich 31,1 Prozent, während der stärkste Mitbewerber Claude Opus 4.6 auf 68,8 Prozent kommt. GPT-5.2 liegt mit 52,9 Prozent deutlich dahinter.
Quelle: Google
Auch in der algorithmischen Programmierung setzt Google neue Marken. Auf der Plattform Codeforces erreicht das Modell ein Elo-Rating von 3455. Damit bewegt sich die KI in Sphären, die normalerweise den weltweit besten menschlichen Wettkampf-Programmierern vorbehalten sind. Die Konkurrenz von OpenAI und Anthropic ordnet sich hier im Bereich zwischen 2350 und 2500 Elo-Punkten ein.
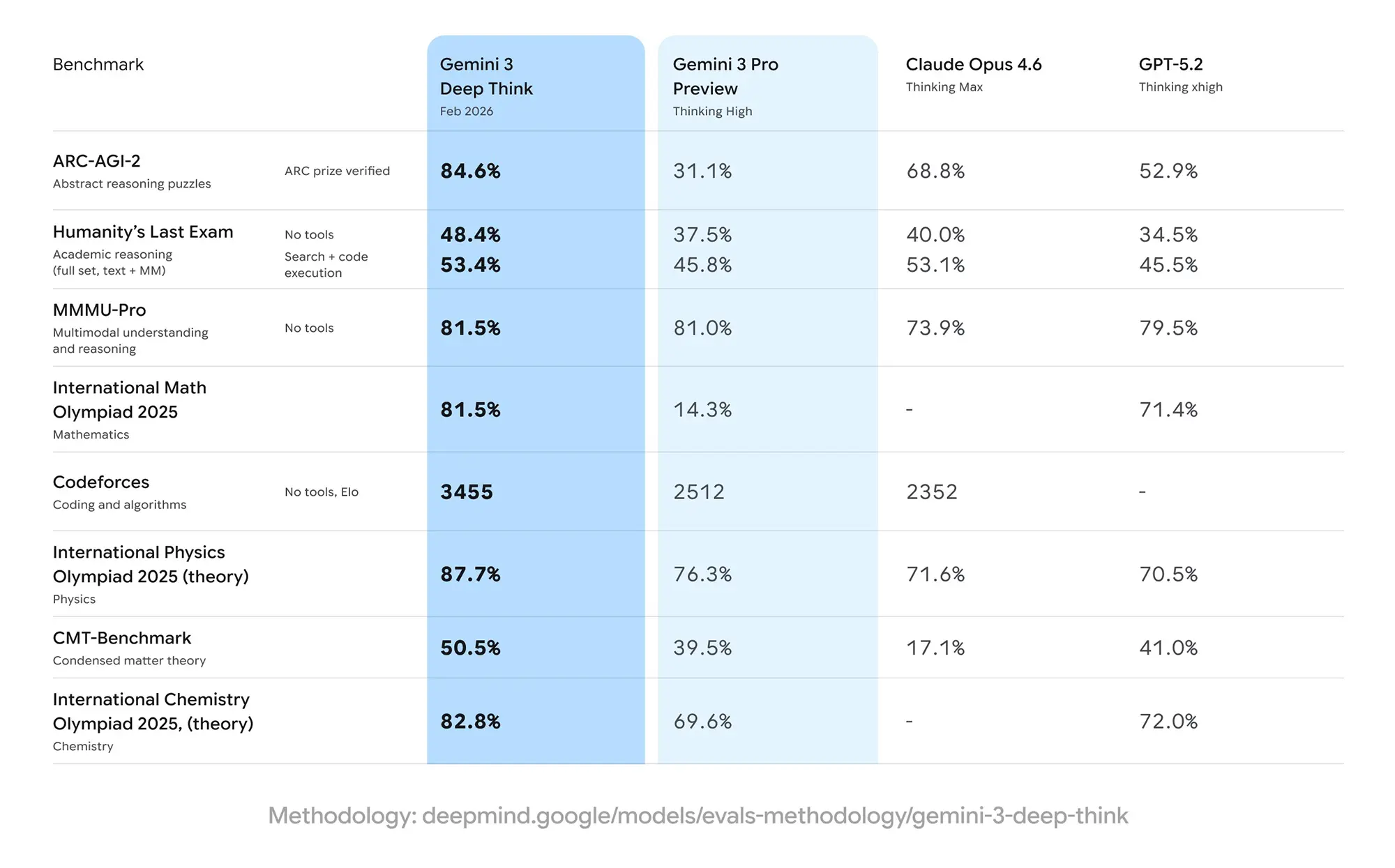
Bei klassischen akademischen Tests wie der Internationalen Mathematik-Olympiade 2025 bestätigt sich der Trend: Mit einer Lösungsquote von 81,5 Prozent übertrifft Deep Think die Preview-Version (14,3 Prozent) um ein Vielfaches und schlägt auch GPT-5.2 (71,4 Prozent).
Quelle: Google
Grenzen der Machbarkeit
Trotz der hohen Werte in isolierten Testszenarien bleibt die Anwendung in der offenen Welt eine Hürde. Der Benchmark "Humanity’s Last Exam", der akademisches Reasoning auf Text- und Multimodal-Ebene prüft, zeigt die aktuellen Limits auf. Selbst mit Zugriff auf Tools (Code Execution, Suche) erreicht Gemini 3 Deep Think hier nur 53,4 Prozent.
Zwar liegt dieser Wert über dem der Konkurrenz, verdeutlicht aber, dass fast die Hälfte der komplexen Aufgabenstellungen weiterhin ungelöst bleibt. In der Praxis müssen Anwender daher verifizieren, ob die verlängerte Rechenzeit ("Thinking Mode") bei spezifischen Problemen tatsächlich einen qualitativen Mehrwert liefert oder nur die Antwortzeit erhöht.