
Schlägt GLM-5 die führenden KI-Modelle aus den USA?
Z.ai verspricht das Ende von Vibe Coding und den Start von "Agentic Engineering". Die Benchmarks unterstreichen das.

Das chinesische KI-Startup Z.ai (Zhipu AI) hat mit GLM-5 sein neues Spitzenmodell veröffentlicht. Der Fokus liegt auf einer signifikanten Verbesserung der Agenten-Fähigkeiten. Statt nur Code zu generieren, soll das Modell komplexe Software-Projekte autonom managen und positioniert sich in Benchmarks in Schlagdistanz zu US-Konkurrenz wie Anthropic und Google.
Abschied vom „Vibe Coding“
Mit der Veröffentlichung von GLM-5 greift Z.ai eine aktuelle Diskussion der Softwareentwicklung auf: den Übergang vom sogenannten „Vibe Coding“ zum „Agentic Engineering“. Während ersteres oft das intuitive, schnelle Generieren von Code-Schnipseln beschreibt – bei dem der Entwickler eher nach Gefühl prüft, ob das Ergebnis stimmt –, zielt der neue Ansatz auf systematisches Ingenieurswesen ab.
Der Hersteller verspricht, dass GLM-5 nicht nur Syntax liefert, sondern den gesamten Lebenszyklus einer Aufgabe versteht. Das Modell soll in der Lage sein, Repositories zu navigieren, Fehler in Build-Prozessen selbstständig zu beheben und langfristige Planungen (Long-horizon tasks) durchzuführen. Z.ai reagiert damit auf die Kritik an bisherigen LLMs, die zwar beeindruckende Demos liefern, in komplexen Produktionsumgebungen jedoch oft an Flüchtigkeitsfehlern scheitern.
Anzeige
Benchmarks: Anschluss an die Weltspitze
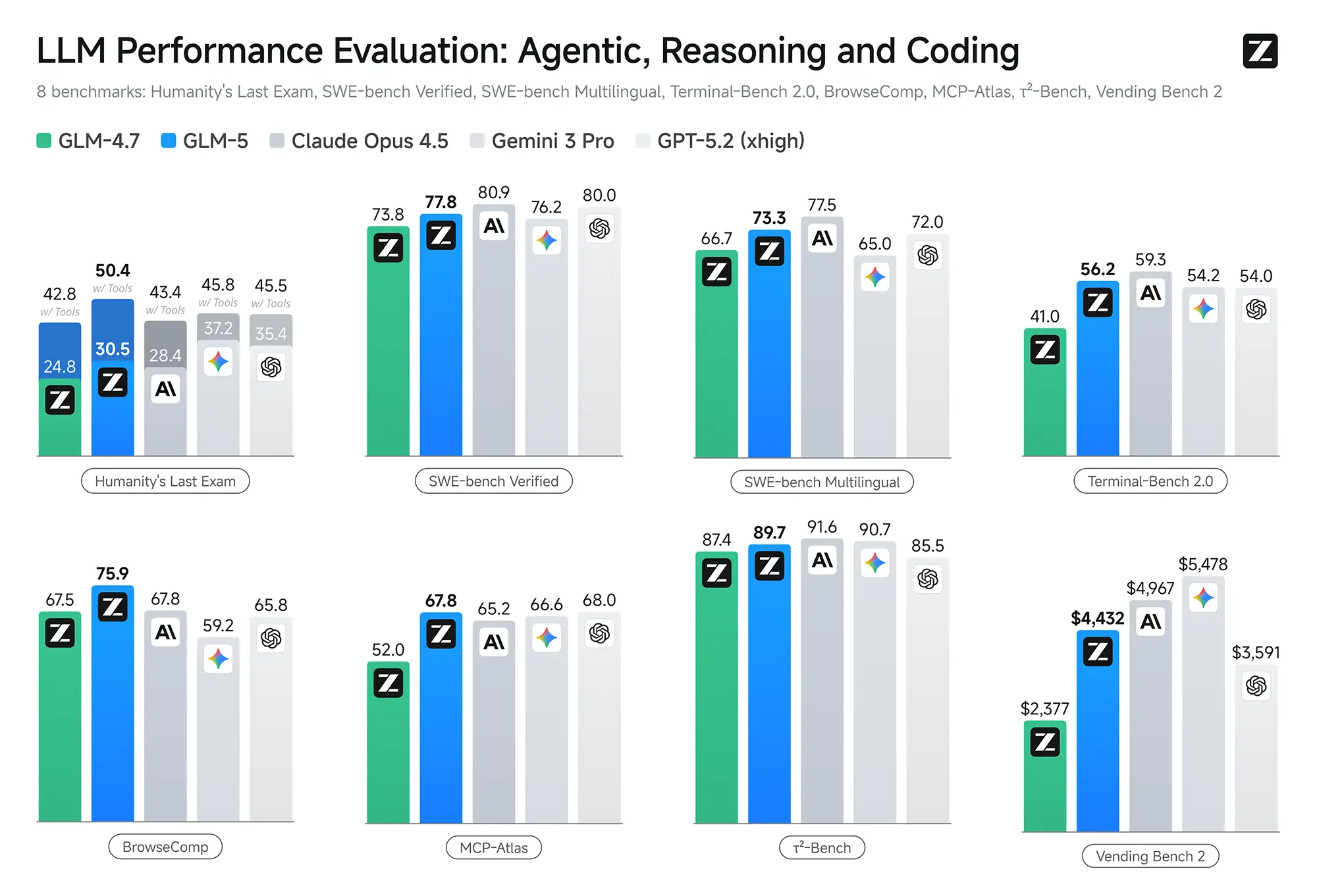
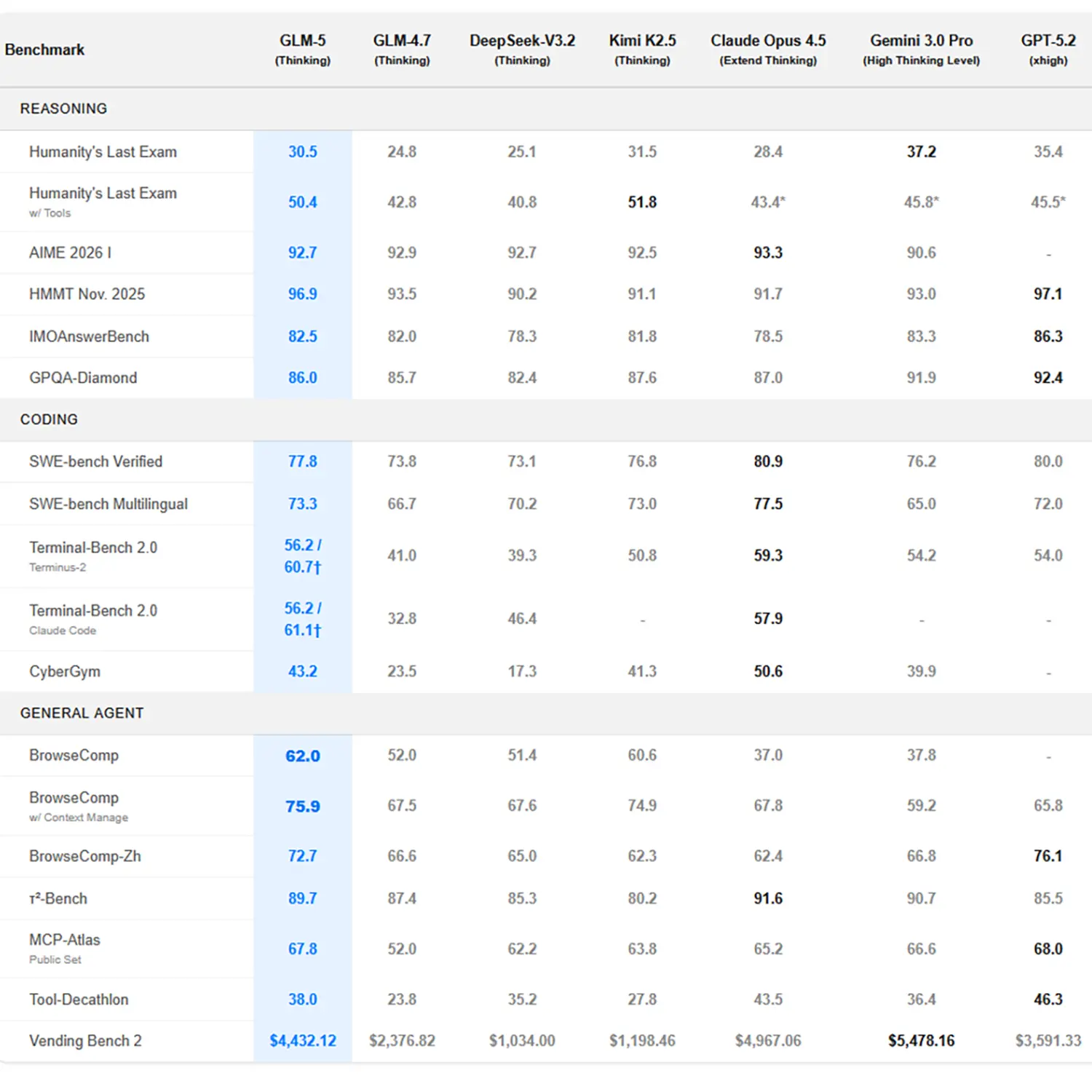
Ein Blick auf die technischen Daten zeigt, dass Z.ai den Abstand zu den führenden US-Modellen verringert hat, diese aber nicht durchgehend schlägt. Im „SWE-bench Verified“, einem etablierten Standardtest für Software-Engineering-Aufgaben, erreicht GLM-5 einen Wert von 77,8 Prozent. Dies markiert eine messbare Verbesserung gegenüber dem Vorgänger GLM-4.7 (73,8 Prozent), bleibt jedoch knapp hinter Anthropics Claude Opus 4.5 (80,9 Prozent) zurück.
Quelle: Zhipu AI
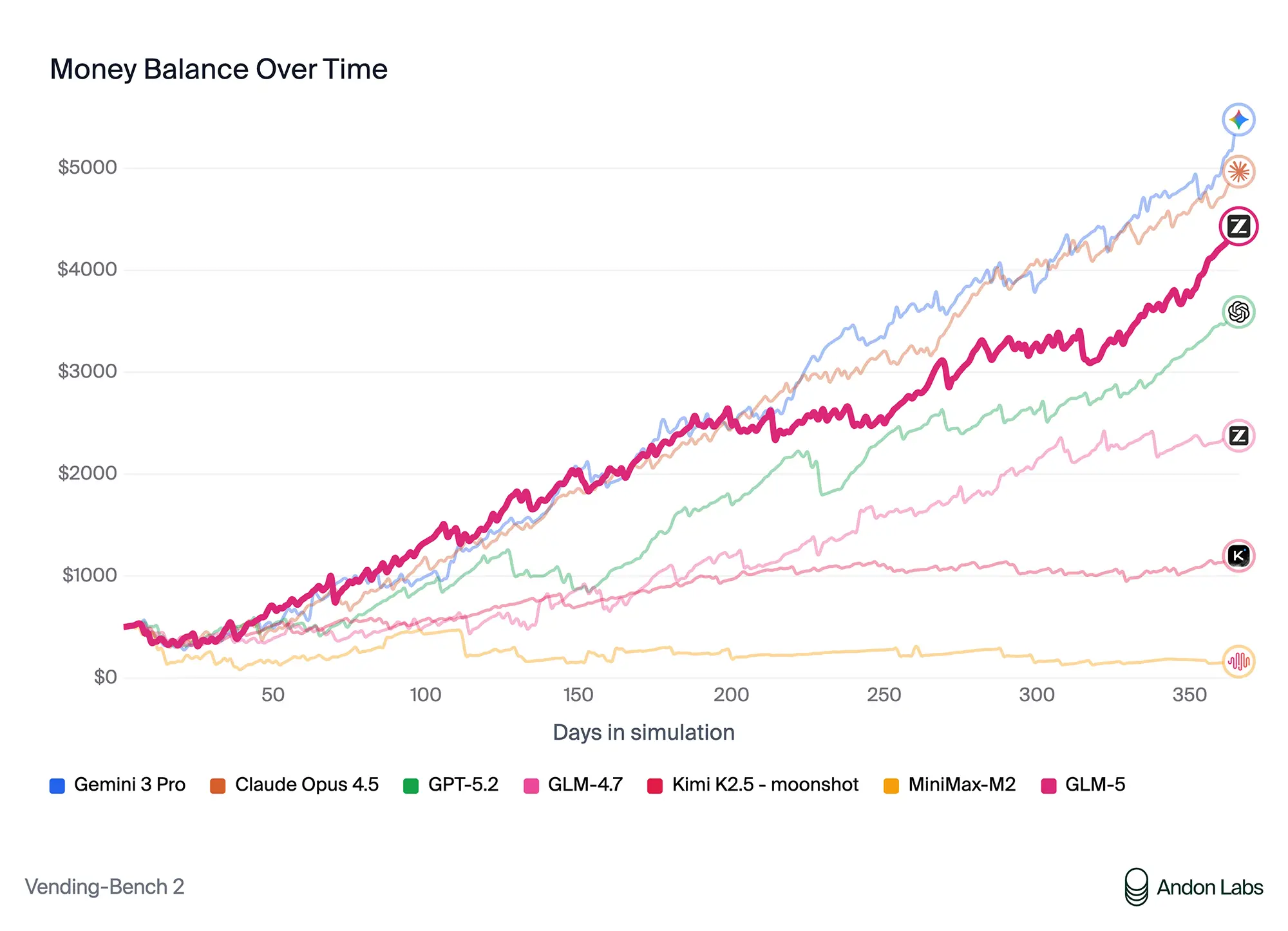
Interessant ist das Abschneiden im „Vending Bench 2“, einer Simulation, in der KI-Agenten wirtschaftlich handeln müssen. Hier erwirtschaftete GLM-5 im Testzeitraum ein Guthaben von 4.432 Dollar. Das Modell zeigt damit eine solide Planungsfähigkeit, muss sich aber Googles Gemini 3.0 Pro geschlagen geben, das im gleichen Szenario auf über 5.400 Dollar kam. In reinen Reasoning-Aufgaben wie „Humanity’s Last Exam“ (mit Tools) positioniert sich GLM-5 mit 50,4 Punkten hingegen sehr stark und liegt teils vor der direkten Konkurrenz.
Quelle: Zhipu AI
Spezialisierung auf Web-Development
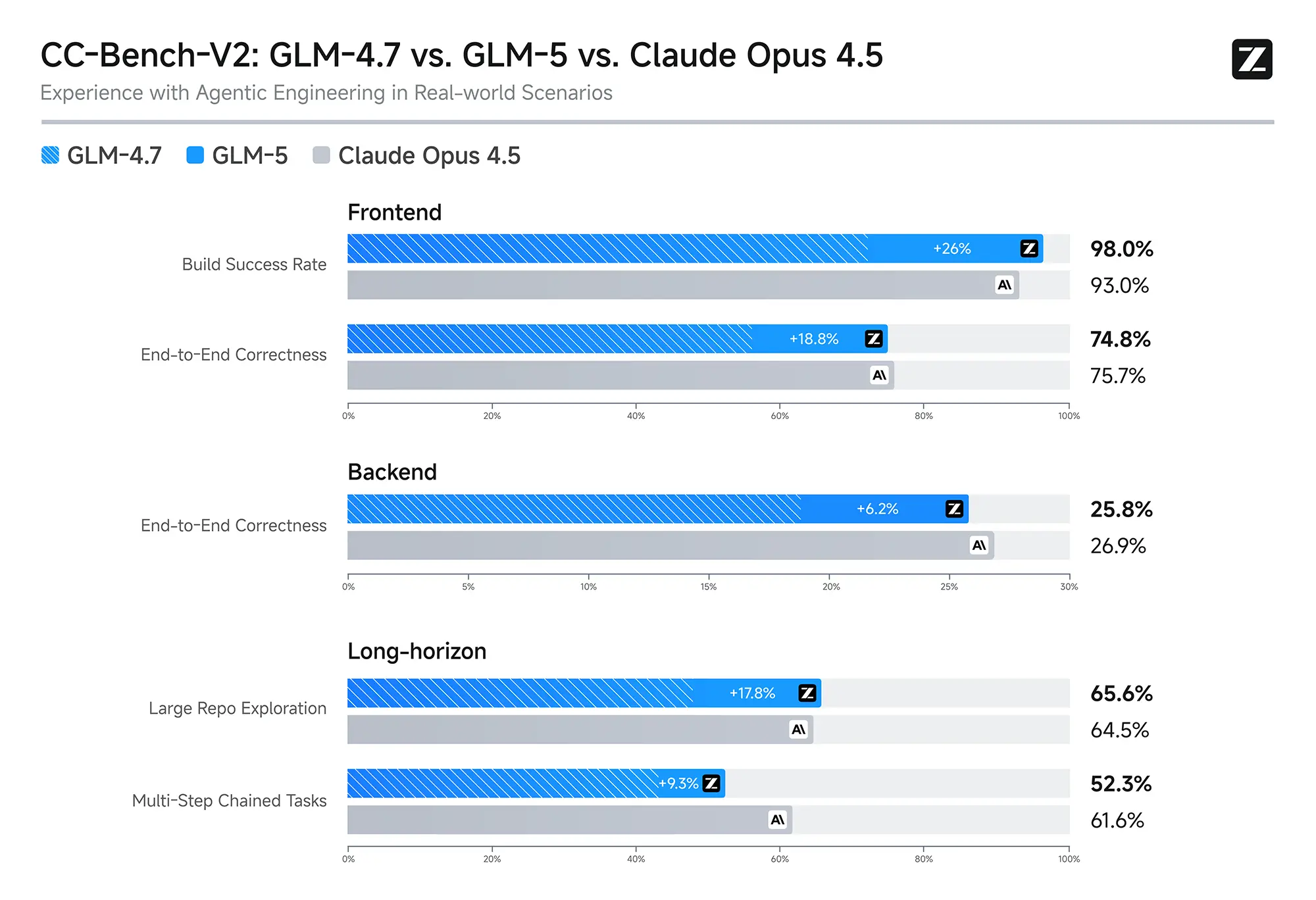
Besonders im Bereich der Frontend-Entwicklung scheint das Modell Fortschritte gemacht zu haben. Laut internen Metriken (CC-Bench-V2) steigerte GLM-5 die Erfolgsrate bei Frontend-Builds auf 98 Prozent. Dies entspricht einem Zuwachs von 26 Prozentpunkten gegenüber der vorherigen Version GLM-4.7. Auch bei der End-to-End-Korrektheit im Backend verzeichnet das Datenblatt leichte Gewinne.
Quelle: Zhipu AI
Diese Zahlen deuten darauf hin, dass das Modell spezifisch auf die Interaktion mit modernen Web-Frameworks und Toolchains optimiert wurde. Es bleibt jedoch abzuwarten, wie sich diese Werte in realen, oft chaotischen Codebasen von Unternehmen verhalten, die nicht den sauberen Bedingungen von Benchmark-Suites entsprechen.
Quelle: Zhipu AI
Verfügbarkeit und Einordnung
GLM-5 ist ab sofort über die Schnittstellen von Z.ai verfügbar. Die Veröffentlichung unterstreicht den Anspruch der chinesischen Tech-Szene, technologische Autonomie zu wahren. Z.ai, international als Zhipu AI bekannt, wird unter anderem von Alibaba und Tencent unterstützt und gilt als einer der wichtigsten KI-Akteure Asiens.
Ob der Marketing-Begriff „Agentic Engineering“ mehr ist als ein Versprechen, muss der Praxiseinsatz zeigen. Die Benchmark-Ergebnisse belegen zumindest, dass die Zeit der alleinigen Dominanz westlicher Modelle vorbei ist und sich der Wettbewerb an der Spitze weiter verdichtet.