
NVIDIA Dynamo 1.0: 7-facher Durchsatz für KI-Modelle
Die neue Open-Source-Software optimiert Rechenzentren erheblich und beschleunigt komplexe Sprachmodelle auf der aktuellen Blackwell-Hardware.

NVIDIA veröffentlicht die finale Version 1.0 seiner Inferenz-Software Dynamo. Das Open-Source-Framework steigert den Durchsatz großer KI-Modelle wie DeepSeek R1 enorm, wenn es auf der aktuellen Blackwell-Hardware läuft. Dadurch sinken die Betriebskosten für Anbieter deutlich.
Software bändigt große Sprachmodelle
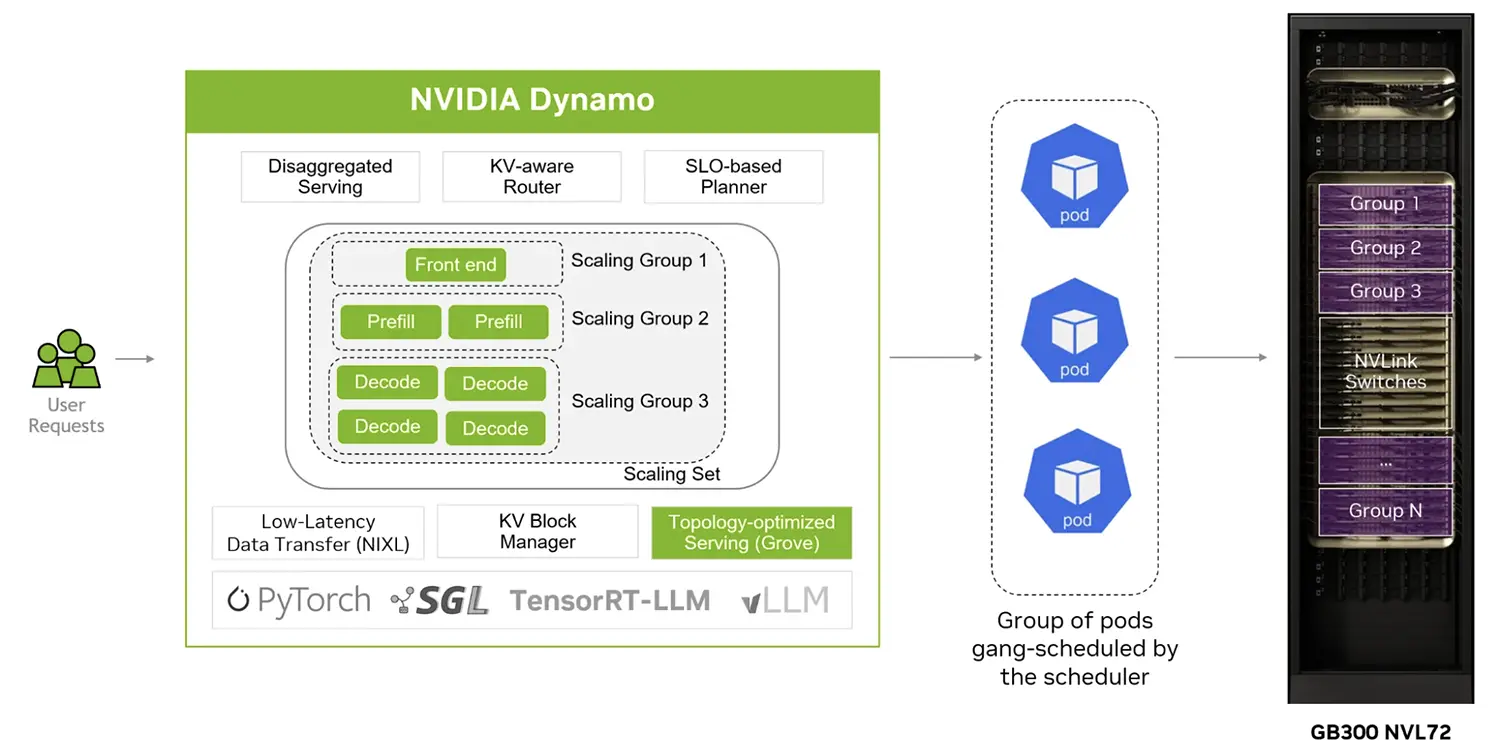
Dynamo 1.0 optimiert die Arbeitsteilung zwischen hunderten Grafikprozessoren bei der Textgenerierung. Moderne KI-Modelle berechnen Aufgaben in zwei Schritten, weshalb die Software das anfängliche Erfassen des Prompts strikt von der eigentlichen Ausgabe der Token trennt.
Anschließend verteilt das System diese Rechenschritte auf exakt die Server, die gerade freie Kapazitäten haben.
Dieses Open-Source-Framework entfaltet seine volle Leistung im Zusammenspiel mit spezialisierter Hardware. NVIDIA setzt dafür das GB200 NVL72 System ein, welches 72 Blackwell-Chips über extrem schnelle Verbindungen zusammenschließt.
Die Anlage teilt die Berechnungen für sogenannte Mixture-of-Experts-Modelle effizient auf. Bei dieser Architektur aktivieren Modelle für jede Anfrage nur bestimmte Teilbereiche ihres neuronalen Netzes.
Quelle: Nvidia
Deutlicher Leistungssprung in der Praxis
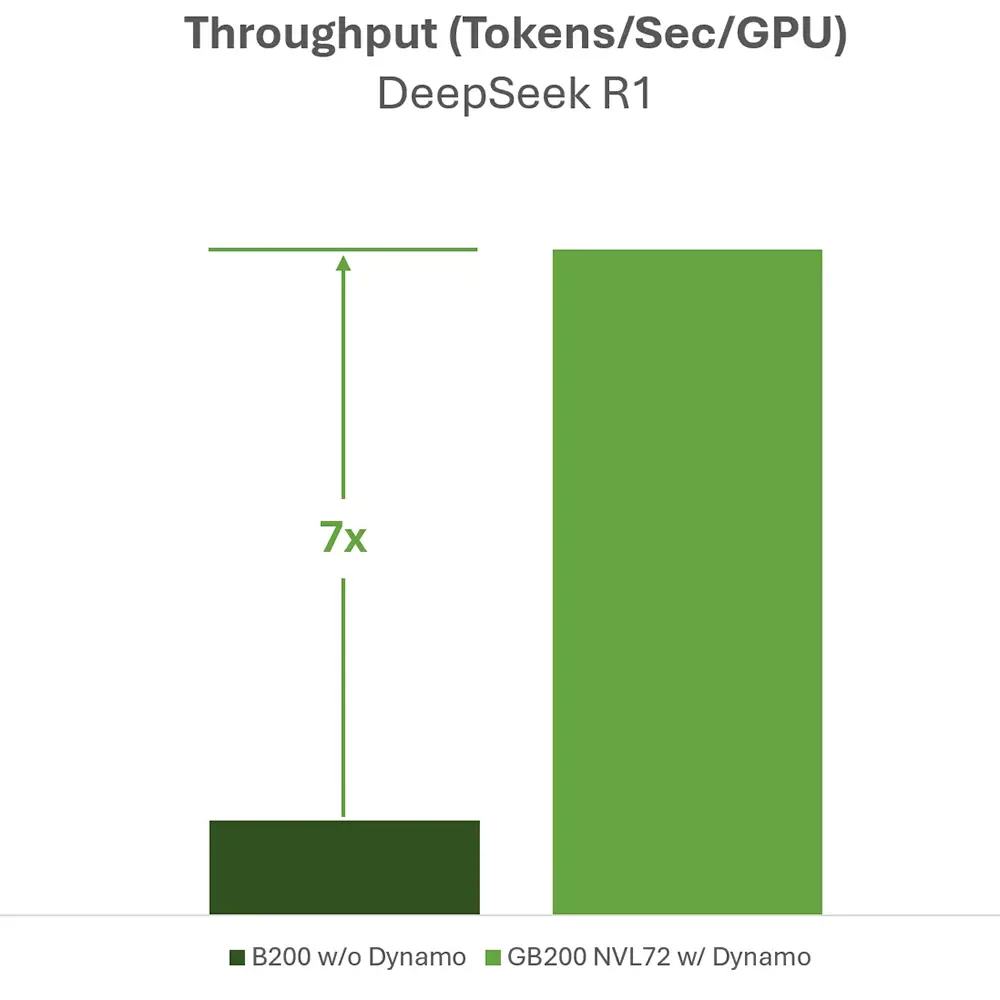
Ein Benchmark des Herstellers zeigt die genauen Auswirkungen dieser Kombination. Das populäre Modell DeepSeek R1 erreicht mit Dynamo auf dem GB200 NVL72 einen siebenmal höheren Durchsatz. Der Vergleichswert bezieht sich dabei auf ein herkömmliches B200-System ohne die neue Management-Software.
Quelle: Nvidia
Die Metrik erfasst den Durchsatz in Token pro Sekunde pro Grafikkarte. Solche Sprünge verändern die Kalkulation von Rechenzentren spürbar.
Wenn eine Anlage die siebenfache Menge an Textbestandteilen in der gleichen Zeit generiert, sinkt der Preis für jeden einzelnen Token. Anbieter betreiben komplexe Sprachmodelle dadurch wesentlich rentabler.
Anzeige
Schnellerer Start und flexibler Speicher
Zusätzlich beschleunigt das Update alltägliche Wartungsprozesse im Rechenzentrum. Betreiber müssen ihre Kapazitäten je nach aktuellem Datenverkehr kontinuierlich hoch- und runterfahren.
Die Software lädt die enormen Datenmengen der Sprachmodelle nun bis zu siebenmal schneller in den Arbeitsspeicher der Chips. Das reduziert Wartezeiten bei plötzlichen Lastspitzen erheblich.
Das Framework unterstützt ab sofort auch die direkte Anbindung an externe Speicherlösungen von Drittanbietern. Das System lagert Daten einfach aus, sobald der interne Speicher der Grafikkarten vollläuft. Dadurch verarbeiten die KI-Modelle längere Kontexte in einem Durchgang, ohne abzustürzen.
Die Software fängt zudem Hardwareausfälle sicher ab. Sie überträgt fehlerhafte Anfragen sofort auf funktionierende Server, was Ausfallzeiten für die Endnutzer auf ein Minimum reduziert.