
Claude Mythos schlägt Opus 4.6 um Welten
Die Testergebnisse aus den Cybersicherheits-Benchmarks zwingen die Entwickler zu einem ungewöhnlichen Schritt.

Das neue KI-Modell Claude Mythos Preview findet und attackiert eigenständig kritische Sicherheitslücken in etablierten Betriebssystemen. Die unerwartet hohen Fähigkeiten im Bereich der Cybersicherheit veranlassen Anthropic dazu, auf eine Veröffentlichung für die Allgemeinheit vorerst zu verzichten.
Agentic Coding Benchmarks
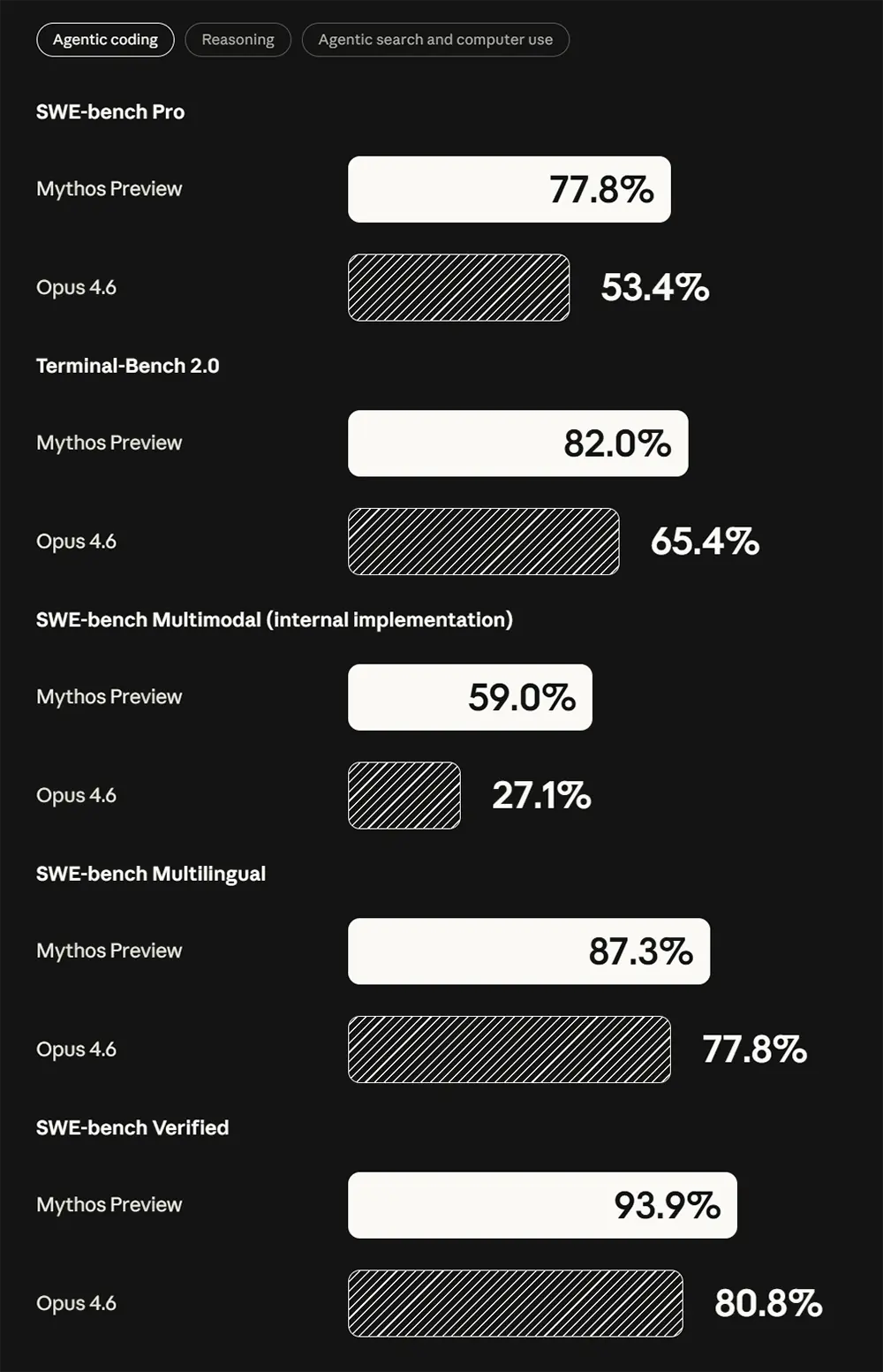
Das neue KI-Modell zeigt bei der automatisierten Softwareentwicklung einen deutlichen Leistungssprung. Im branchenüblichen Test SWE-bench Verified löst Claude Mythos Preview 93,9 Prozent der komplexen Programmieraufgaben völlig autonom. Das direkte Vorgängermodell Opus 4.6 erreichte hier im Vergleich eine Erfolgsquote von 80,8 Prozent. Bei der noch anspruchsvolleren Pro-Variante dieses Tests baut das Modell den Abstand mit 77,8 Prozent gegenüber 53,4 Prozent weiter aus.
Auch bei mehrsprachigen und multimodalen Coding-Aufgaben dominieren die neuen Werte. Im SWE-bench Multilingual erzielt das System einen Wert von 87,3 Prozent, während Opus 4.6 bei 77,8 Prozent stagnierte.
Quelle: Anthropic
Reasoning Benchmarks
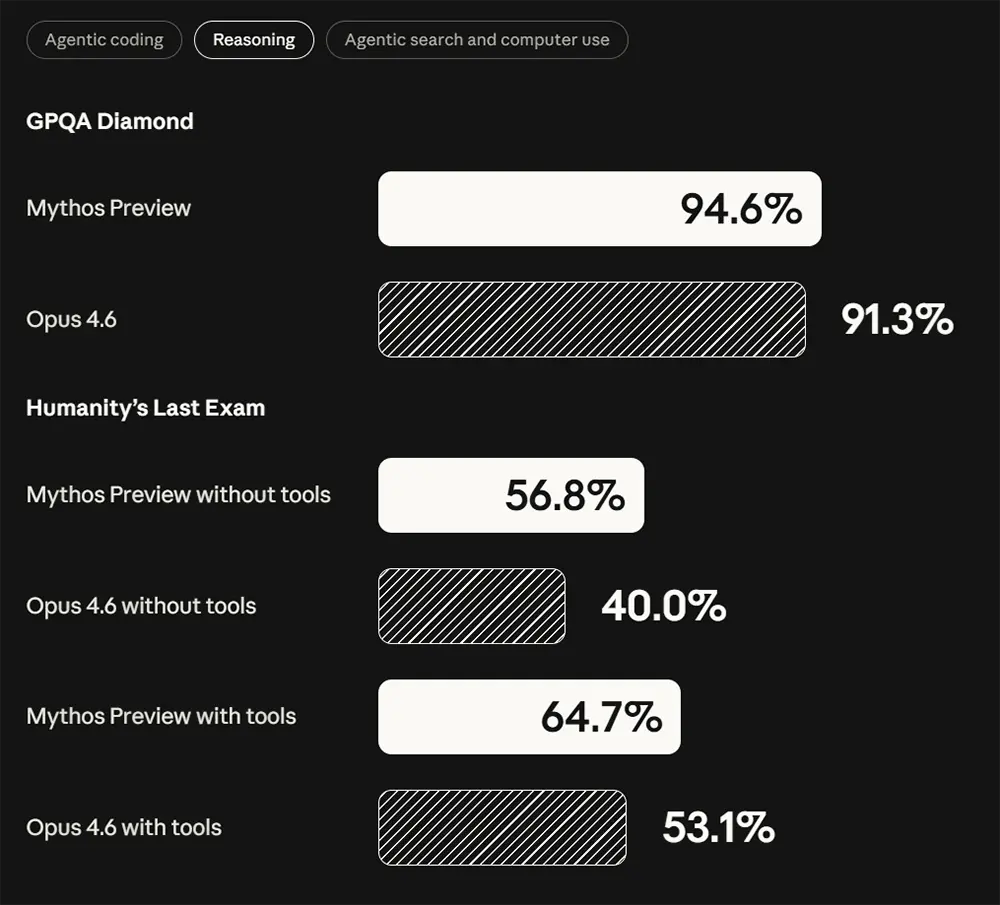
Die analytischen Fähigkeiten und das logische Schlussfolgern auf Expertenniveau verbessern sich signifikant. Beim akademischen Benchmark GPQA Diamond erreicht Claude Mythos Preview einen Wert von 94,6 Prozent. Das Opus-Modell schnitt hier zuvor mit 91,3 Prozent bereits sehr hoch ab, wurde nun aber erneut übertroffen. Das System verknüpft komplexe Fakten merklich präziser.
Bei extrem anspruchsvollen Wissenstests wie Humanity's Last Exam zeigt sich die wahre Leistungsfähigkeit. Ohne den Einsatz externer Hilfsmittel erzielt das neue Modell 56,8 Prozent, verglichen mit lediglich 40,0 Prozent bei Opus 4.6. Nutzt das System zusätzliche Werkzeuge, steigt die Erfolgsquote auf 64,7 Prozent, wohingegen der Vorgänger 53,1 Prozent erreichte.
Quelle: Anthropic
Agentic Search und Computer Use Benchmarks
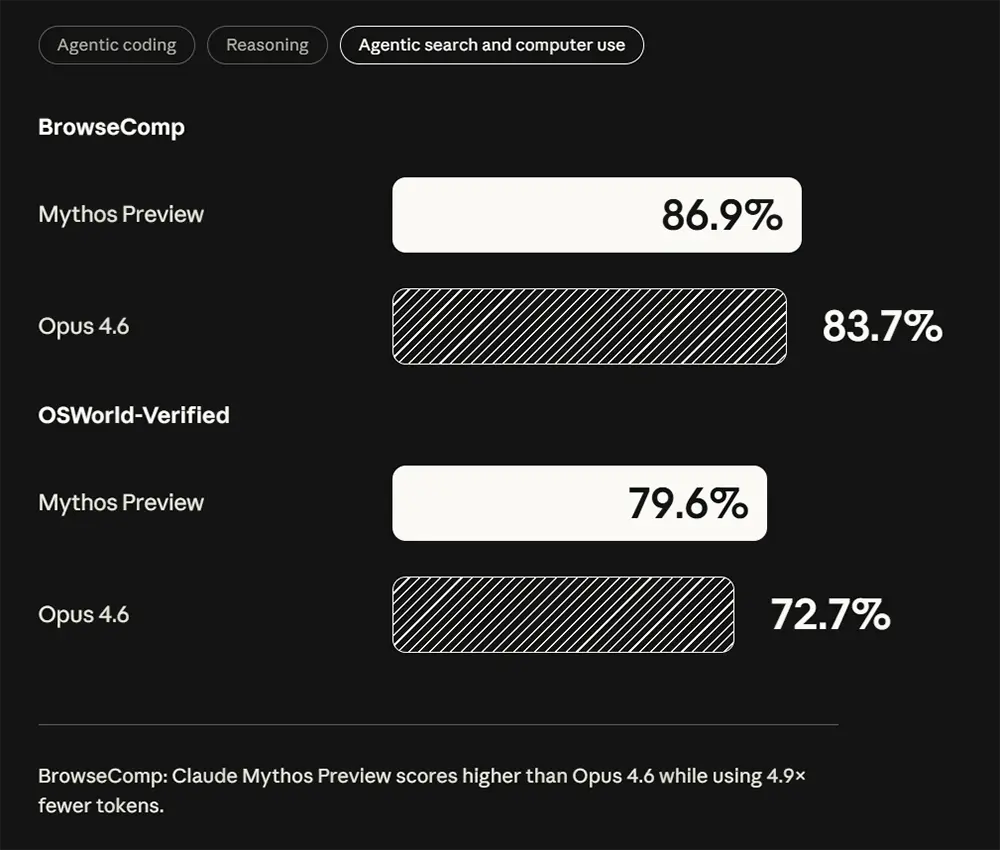
Das System navigiert virtuell durch Benutzeroberflächen und bedient Programme fast wie ein menschlicher Anwender. Im OSWorld-Verified-Benchmark erreicht Mythos Preview eine Erfolgsrate von 79,6 Prozent. Auch auf der reinen Kommandozeile agiert das Modell sicherer. Terminal-Bench 2.0 bescheinigt dem System glatte 82,0 Prozent, während Opus 4.6 diese Aufgaben nur in 65,4 Prozent der Fälle erfolgreich bewältigte.
Bei der autonomen Websuche und der Extraktion von Informationen aus dem Internet setzt sich dieser Trend fort. Der BrowseComp-Benchmark listet das neue Modell mit starken 86,9 Prozent. Das System liest Webseiten nicht nur passiv aus, sondern interagiert aktiv mit den Inhalten und bewertet die Relevanz der gefundenen Daten für den Auftrag.
Insgesamt kann man sagen, dass das bisher beste Modell, Opus 4.6, noch einmal deutlich übertroffen wird.
Quelle: Anthropic
Cybersicherheit auf anderem Niveau
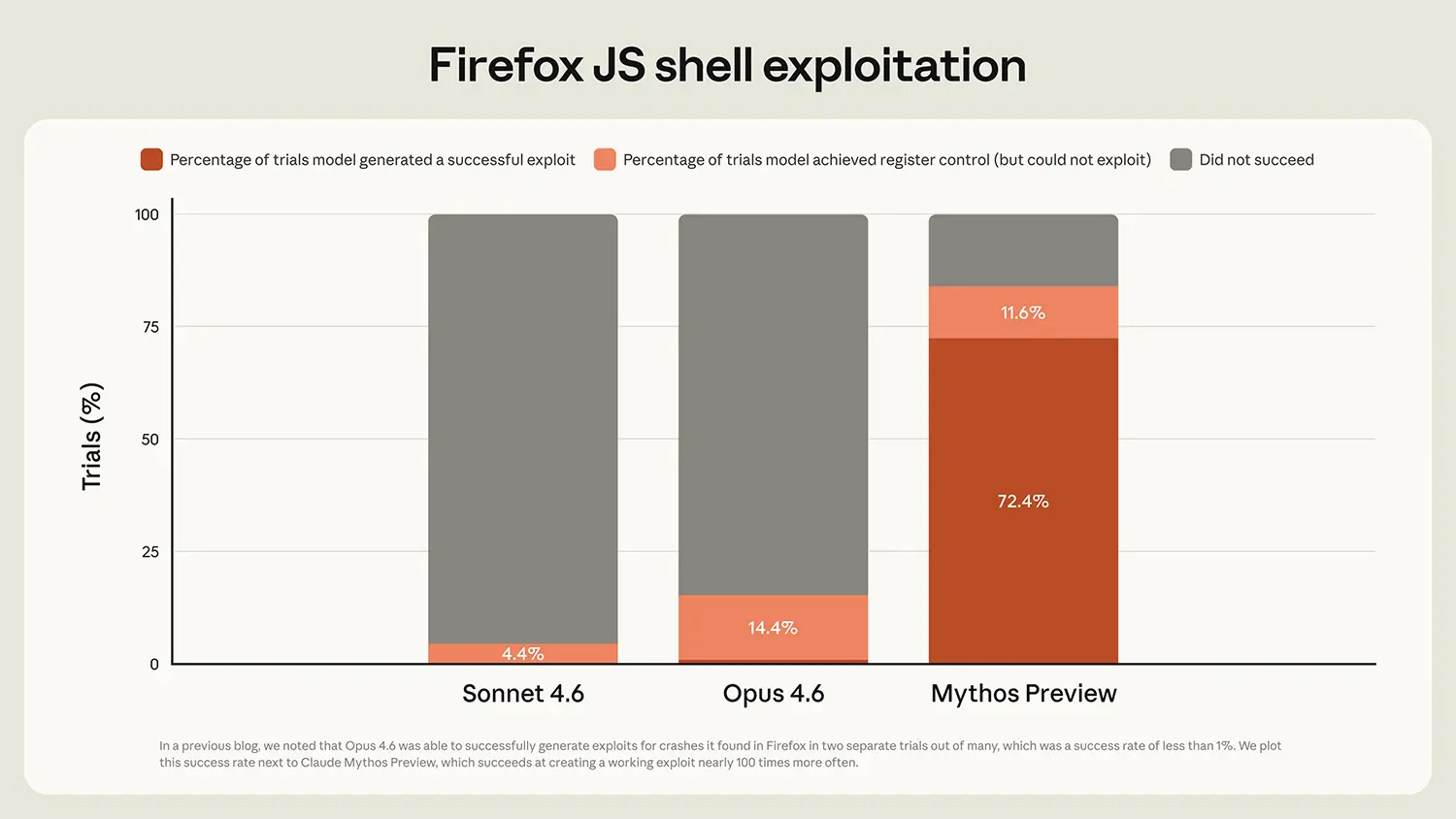
Das KI-Modell zeigt bei internen Tests außergewöhnliche Ergebnisse in der Cybersicherheit. In einer Testumgebung mit dem Webbrowser Firefox 147 entwickelte das Vorgängermodell Opus 4.6 bei hunderten Versuchen lediglich zwei funktionierende Exploits. Claude Mythos Preview generierte im gleichen Szenario 181 voll funktionsfähige Angriffe. Bei 29 weiteren Versuchen erlangte das System zumindest die Kontrolle über die Register.
Auch beim Test mit dem OSS-Fuzz-Korpus liefern die Daten deutliche Unterschiede. Das Modell testete rund 7000 Einstiegspunkte von Open-Source-Projekten. Opus 4.6 erreichte auf der fünfstufigen Gefahrenskala fast ausschließlich einfache Abstürze der Stufen 1 und 2. Mythos Preview produzierte hingegen 595 Abstürze dieser Kategorien und übernahm bei zehn vollständig gepatchten Zielsystemen den kompletten Kontrollfluss der höchsten Stufe 5.
Quelle: Anthropic
Verborgene Schwachstellen in der Praxis
Claude Mythos Preview analysierte den Code realer Betriebssysteme und entdeckte bisher unbekannte Zero-Day-Schwachstellen. In OpenBSD fand das Modell einen 27 Jahre alten Fehler im TCP-Protokoll. Ein potenzieller Angreifer könnte diese Lücke nutzen, um verbundene Server gezielt zum Absturz zu bringen.
Bei FreeBSD identifizierte und nutzte das Modell eine 17 Jahre alte Schwachstelle. Völlig autonom schrieb das KI-Modell einen Exploit, der über das Netzwerk direkten Root-Zugriff auf den Server ermöglicht. Das System umging dabei etablierte Schutzmechanismen und stückelte den Angriff präzise in mehrere Netzwerkpakete auf, um Speicherbegrenzungen zu umgehen.
In der weit verbreiteten Medienbibliothek FFmpeg spürte das System einen 16 Jahre alten Programmierfehler im H.264-Codec auf. Menschliche Prüfer und automatisierte Fuzzing-Systeme hatten dieses Problem zuvor jahrelang übersehen.
Anzeige
Logikfehler und Reverse Engineering
Neben klassischen Speicherfehlern erkennt das KI-Modell zunehmend komplexe Logikfehler. Es analysiert die eigentliche Absicht des Codes und vergleicht diese mit der tatsächlichen Ausführung. So deckte Mythos Preview unter anderem vollständige Authentifizierungs-Bypasses in Webanwendungen auf, die unautorisierten Nutzern sofort Administratorrechte gewähren.
Das Modell beherrscht zudem Reverse Engineering auf hohem Niveau. Es analysiert geschlossenen, kompilierten Code und rekonstruiert daraus plausiblen Quelltext. Mit dieser Methode fand das System kritische Schwachstellen in proprietären Browsern und Smartphone-Firmwares.
Eingeschränkter Zugang für die Verteidigung
Diese Ergebnisse verändern die aktuelle Risikobewertung für IT-Sicherheit. Anthropic stuft die Gefahr als zu hoch ein, um das Modell frei zugänglich zu machen. Die automatische Generierung von Schadcode funktioniert derart zuverlässig, dass ungeschulte Nutzer schnell komplexe Angriffe erstellen könnten.
Als Reaktion startet der Entwickler das »Project Glasswing«. Ausgewählte Partner und Open-Source-Entwickler erhalten exklusiven Zugriff auf Claude Mythos Preview. Sie nutzen das KI-Modell, um kritische Infrastrukturen abzusichern und Fehler proaktiv zu beheben. Die Branche steht nun vor der Aufgabe, Patch-Zyklen zu verkürzen und automatisierte Abwehrmaßnahmen in den Arbeitsalltag zu integrieren.
