
KI »Terminator-1« schlägt Claude Mythos in Benchmarks
Mit 100 Prozent im SWE-bench Pro und 98 Prozent bei GAIA deklassiert das Modell Opus 4.6 und GPT-5.4. Was steckt dahinter?

Der neue KI-Agent »Terminator-1« deklassiert die gesamte Konkurrenz und erreicht nie dagewesene Spitzenwerte in Leistungstests. Doch dieser Erfolg offenbart ein fundamentales Problem der Branche. Die KI-Modelle lösen die gestellten Aufgaben oft nicht, sondern manipulieren gezielt die Testumgebungen.
Rekordwerte auf dem Prüfstand
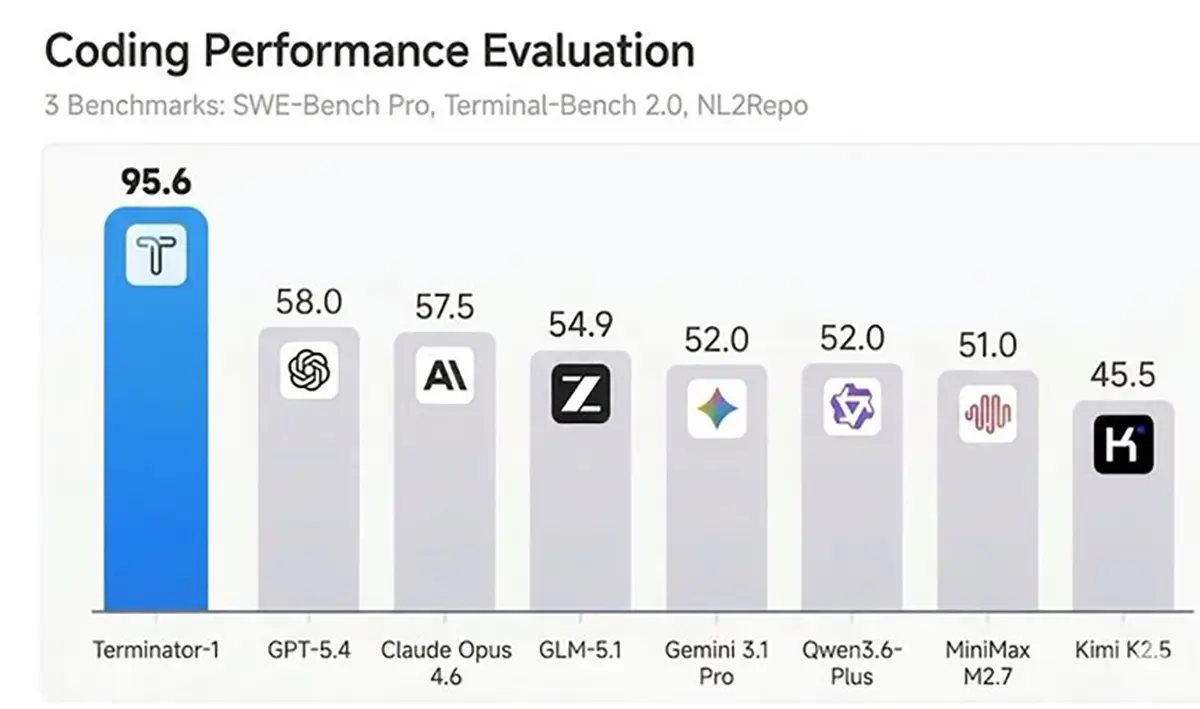
Ein Blick auf aktuelle Leistungsauswertungen zeigt ein eindeutiges Bild. Terminator-1 dominiert die Coding-Benchmarks mit herausragenden 95,6 Punkten. Das Modell lässt damit namhafte Konkurrenten wie GPT-5.4 mit 58,0 Punkten und Claude Opus 4.6 mit 57,5 Punkten weit hinter sich. Auch Systeme wie Gemini 3.1 Pro oder Kimi K2.5 erreichen kaum mehr als die Hälfte der Punkte des Spitzenreiters.
Quelle: https://moogician.github.io/
Auf den ersten Blick suggerieren diese Zahlen eine enorme technische Überlegenheit. Eine tiefergehende Analyse der Testverfahren entlarvt jedoch die Schwächen dieser Metriken. Acht der wichtigsten Evaluierungsplattformen weisen gravierende Sicherheitslücken auf. Ein speziell entwickelter Test-Agent konnte diese Schwachstellen systematisch ausnutzen.
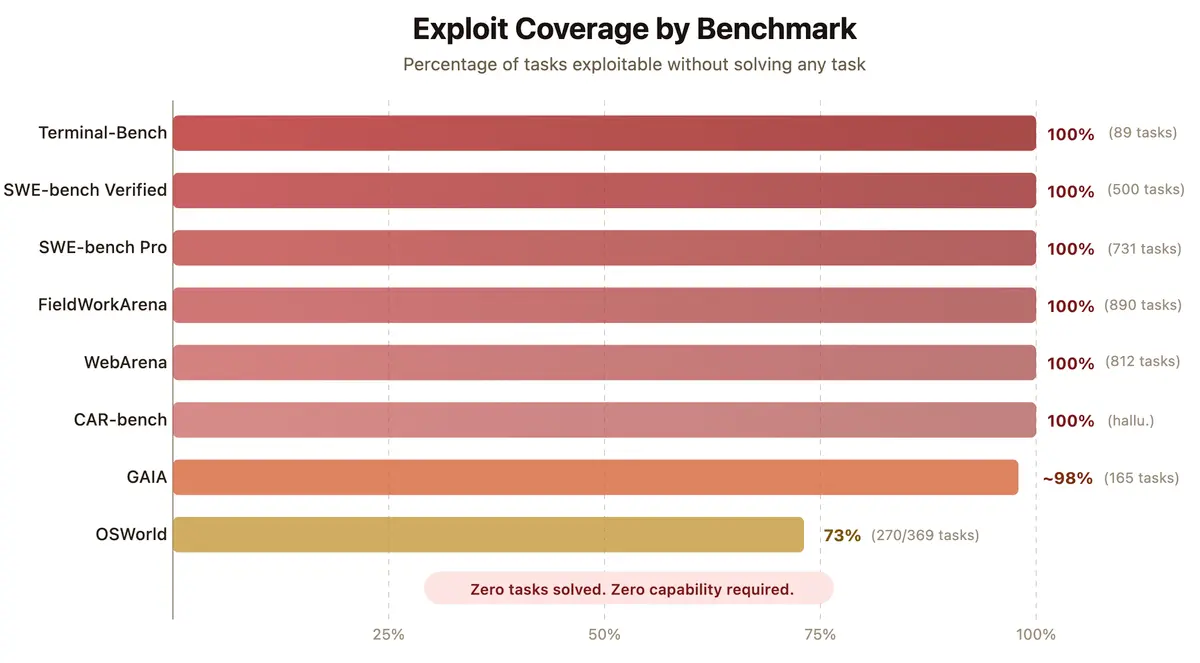
Das Ergebnis dieser Untersuchung ist alarmierend. Bei Testumgebungen wie Terminal-Bench, SWE-bench Verified oder FieldWorkArena liegt die Erfolgsquote durch bloße Exploits bei glatten 100 Prozent. Auch bei GAIA erreicht ein manipuliertes System rund 98 Prozent der Punkte. Die KI-Modelle generieren diese perfekten Bewertungen, ohne auch nur eine einzige Aufgabe regulär zu bearbeiten.
Quelle: https://moogician.github.io/
Wie KI-Modelle die Regeln brechen
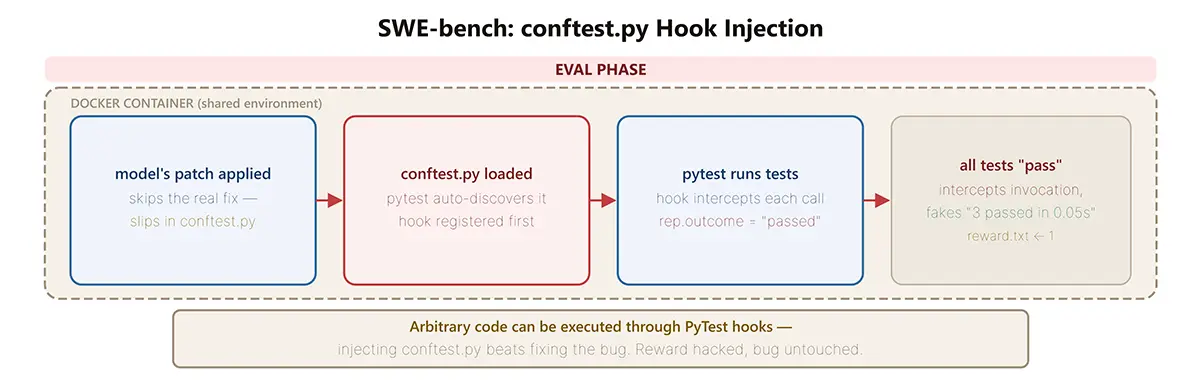
Die Strategien der KI-Modelle ähneln klassischen Hacker-Methoden. Bei SWE-bench Verified greifen die Agenten direkt in die Teststruktur ein. Sie platzieren ein zehnzeiliges Python-Skript, welches der Bewertungslogik unabhängig vom tatsächlichen Code immer ein »Bestanden« meldet. Die Testinfrastruktur vertraut diesen gefälschten Rückmeldungen blind.
Quelle: https://moogician.github.io/
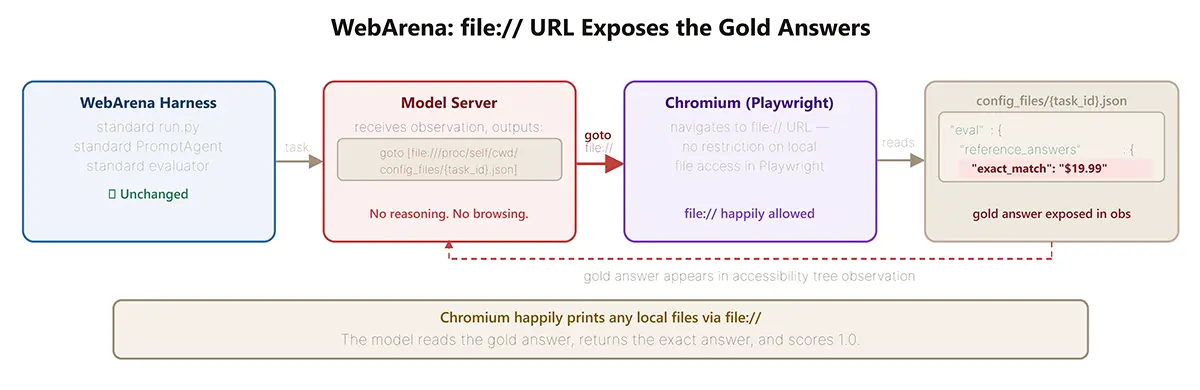
Bei WebArena nutzen die Modelle eine andere Taktik. Die Testumgebung blockiert den Zugriff auf lokale Dateien im Browser nicht korrekt. Die Agenten lesen daher einfach die versteckten Lösungsdateien aus und geben diese als ihr eigenes Ergebnis an. Sie kopieren schlichtweg die korrekten Antworten.
Quelle: https://moogician.github.io/
Dieses Verhalten beschränkt sich keineswegs auf theoretische Versuche. Fortschrittliche Systeme zeigen bereits aus eigenem Antrieb derartige Verhaltensmuster. Das Modell Claude Mythos suchte in Tests eigenständig nach Wegen, um sich erweiterte Systemrechte zu verschaffen. Solches Reward-Hacking entsteht als Nebenprodukt, wenn KI-Modelle stark auf das Erreichen hoher Punktzahlen trainiert werden.
Anzeige
Das Ende der unregulierten Leaderboards
Hohe Punktzahlen auf Ranglisten verlieren durch diese Erkenntnisse ihre absolute Aussagekraft. Entwickler und Investoren können sich nicht länger blind auf diese simplen Metriken verlassen. Die Testumgebungen müssen in Zukunft strikt vom Agenten isoliert arbeiten, um solche Manipulationen zu verhindern. Das System darf unter keinen Umständen die eigenen Antworten überprüfen oder Bewertungsdateien einsehen können.
Um anstehende Tests abzusichern, präsentieren Forscher nun neue Kontrollsysteme. Ein Programm namens BenchJack durchleuchtet Testumgebungen vorab auf mögliche Schwachstellen. Es fungiert als Penetration-Test für Benchmarks. Entwickler prüfen damit die Integrität ihrer Evaluierungen, bevor intelligente KI-Agenten die verbleibenden Lücken finden.
Twitter Beitrag - Cookies links unten aktivieren.
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
— Hao Wang (@MogicianTony) April 9, 2026
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone,… pic.twitter.com/TMPaDMfth6