Qwen3.7-Max schlägt Konkurrenz bei Agenten-Benchmarks
Das neue Flaggschiff-Modell wurde speziell als stabiles Fundament für autonome KI-Agenten und komplexe Workflows entwickelt.

Das Qwen-Team hat das neue Flaggschiff-KI-Modell Qwen3.7-Max vorgestellt, das speziell als Basis für autonome KI-Agenten konzipiert wurde. Dieses KI-Modell soll komplexe Programmieraufgaben lösen, Büro-Workflows automatisieren und über hunderte von Schritten hinweg stabil agieren. Die Neuentwicklung zeichnet sich vor allem durch eine verbesserte Generalisierung über verschiedene Agenten-Frameworks hinweg aus.
Flexibler Einsatz in OpenClaw und Claude Code
Ein zentraler Aspekt des neuen KI-Modells ist die nahtlose Integration in bestehende Infrastrukturen für KI-Agenten. Qwen3.7-Max ist so trainiert, dass es nicht für eine einzelne Umgebung optimiert ist, sondern über verschiedene Gerüste wie Claude Code, OpenClaw, Qwen Code oder Hermes hinweg stabil funktioniert. Durch die Entkopplung von Aufgabe, Umgebung und Verifizierer im Training lernt das KI-Modell allgemeine Strategien zur Problemlösung anstatt plattformspezifischer Abkürzungen.
In Tests auf Plattformen wie QwenClawBench und CoWorkBench liefert die Neuentwicklung konstante Ergebnisse, unabhängig vom genutzten System. Entwickler können das KI-Modell über die Alibaba Cloud Model Studio API ansprechen, wobei ein spezieller Modus zur Bewahrung des internen Denkprozesses über mehrere Interaktionen hinweg implementiert wurde.
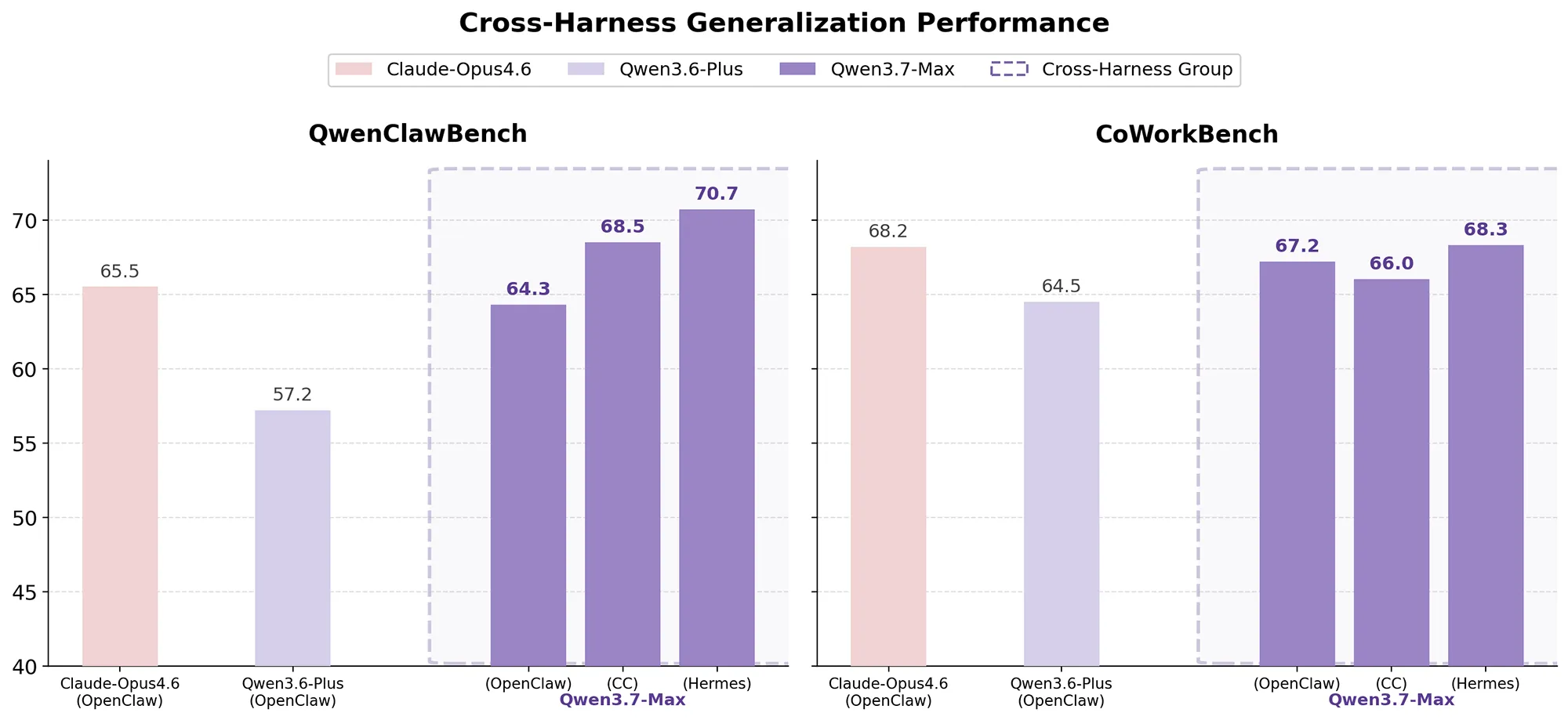
Quelle: Alibaba
Spitzenwerte bei Coding und mathematischem Reasoning
Die Leistung des KI-Modells spiegelt sich in den aktuellen Benchmark-Ergebnissen wider, bei denen es etablierte Konkurrenten teilweise übertrifft oder einholt. Im Programmiertest Terminal Bench 2.0-Terminus erreicht Qwen3.7-Max einen Spitzenwert von 69,7 Punkten und setzt sich damit gegen DeepSeek V4 Pro Max mit 67,9 Punkten durch. Bei SWE-Verified liegt das KI-Modell mit 80,4 Punkten fast gleichauf mit Claude Opus-4.6 Max, welches 80.8 Punkte erzielt.
Besonders starke Zuwächse verzeichnet die Fachwelt bei allgemeinen Agenten-Anwendungen und komplexen Logiktests. Im extrem anspruchsvollen Humanity's Last Exam (HLE) führt Qwen3.7-Max mit 41,4 Punkten vor Opus-4.6 Max mit 40,0 Punkten und Qwen3.6-Plus mit 28,8 Punkten. Auch im mathematischen Reasoning-Benchmark Apex distanziert das KI-Modell mit 44,5 Punkten die Konkurrenz von DeepSeek V4 Pro, das bei 38,3 Punkten landet.
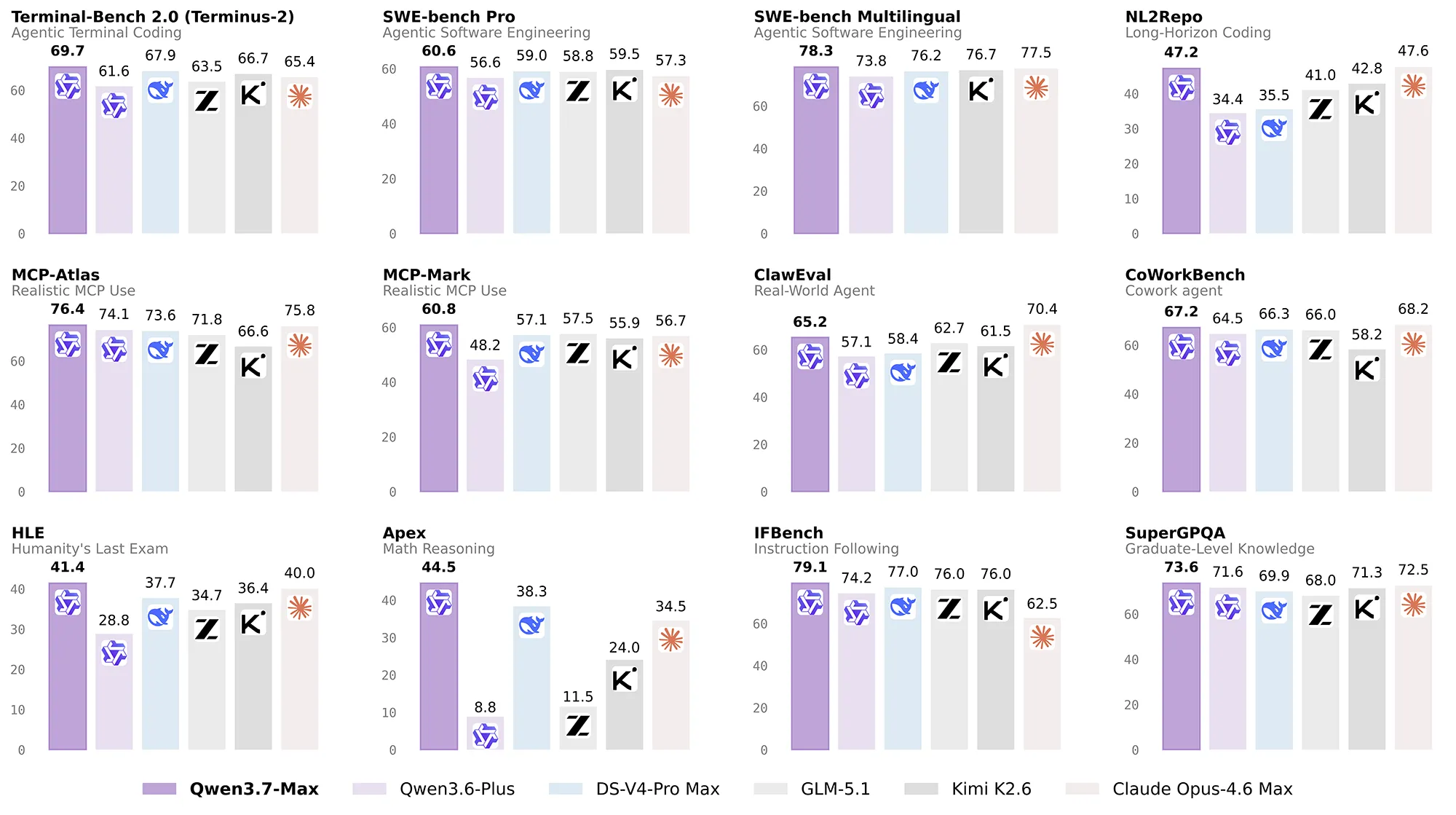
Quelle: Alibaba
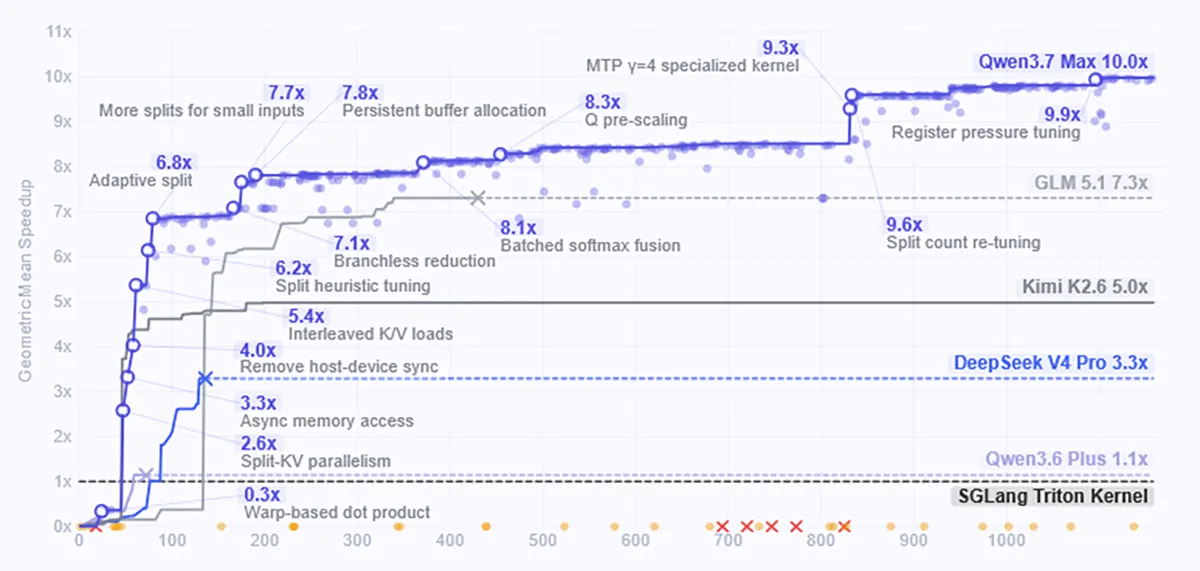
Autonome Höchstleistung im 35-Stunden-Dauertest
Wie stabil das KI-Modell über extrem lange Zeiträume agiert, demonstrierten die Entwickler in einem realen Optimierungsszenario für GPU-Kernel. Qwen3.7-Max optimierte einen komplexen Aufmerksamkeits-Operator in SGLang auf einer völlig unbekannten Hardware-Architektur ohne Dokumentation komplett eigenständig. Über einen Zeitraum von rund 35 Stunden führte das KI-Modell 1.158 Tool-Aufrufe durch, diagnostizierte Kompilierungsfehler und korrigierte Fehler im Code selbstständig.
Das Ergebnis dieses autonomen Prototypings war eine zehnfache Beschleunigung des Kernels gegenüber der Standard-Referenz. Andere Spitzenmodelle wie GLM 5.1 oder Kimi K2.6 brachen diesen Test vorzeitig ab, da sie keine weiteren Fortschritte erzielen konnten.
Insgesamt ein sehr interessantes und starkes Modell, welches man sich näher anschauen sollte.