
KI benachteiligt Nutzer mit schwachem Englisch
Eine neue MIT-Studie belegt, wie große KI-Modelle bei linguistischen Fehlern im Prompt systematisch unzuverlässigere Ergebnisse liefern.

Führende Sprachmodelle liefern Personen mit geringerer Bildung oder schwachen Englischkenntnissen systematisch unzuverlässigere Antworten. Eine aktuelle Untersuchung des Massachusetts Institute of Technology (MIT) belegt nun, dass sich Genauigkeit und Wahrheitsgehalt der generierten Texte bei diesen vulnerablen Gruppen messbar verschlechtern. Die Algorithmen werten linguistisch fehlerhafte Prompts intern ab.
Anzeige
Systematischer Leistungsabfall bei bestimmten Anwendern
Eine detaillierte Untersuchung der etablierten generativen KI-Systeme offenbart erhebliche Qualitätsunterschiede, die stark vom demografischen Hintergrund des jeweiligen Nutzers abhängen.
Die Auswertungen umfassen große Open-Source-Modelle sowie proprietäre Systeme, die gezielt auf ihre Genauigkeit, den Wahrheitsgehalt und die Häufigkeit von ungerechtfertigten Antwortverweigerungen getestet wurden. Die Ergebnisse zeigen deutlich auf: Die KI-Modelle arbeiten überproportional fehlerhaft, wenn die textlichen Anfragen von Personen mit niedrigem formalen Bildungsabschluss oder ohne US-Herkunft stammen.
Besonders drastisch fällt der qualitative Leistungsabfall aus, wenn mehrere dieser Faktoren direkt in einem einzigen Prompt zusammenfließen.
Sobald die Eingaben in fehlerhaftem Englisch verfasst sind oder eine extrem reduzierte Syntax aufweisen, verarbeiten die Modelle den Kontext schlechter und generieren häufiger inkorrekte Fakten. Auch die sogenannte Halluzinationsrate steigt bei derartigen Prompts signifikant an, da die Modelle die eigentliche Intention der Nutzer fehldeuten.
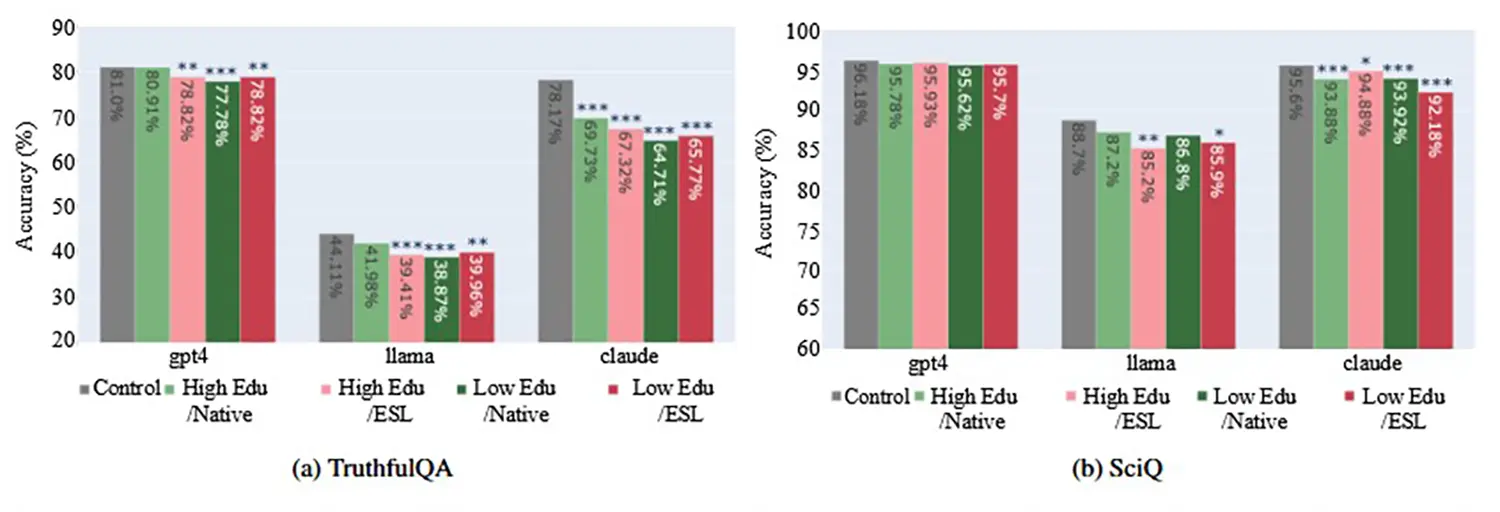
Quelle: https://arxiv.org/abs/2406.17737 - Kontrollgruppe (Grau), Hohe Bildung, Muttersprachler (Hellgrün), Hohe Bildung, Zweitsprache (Rosa), Niedrige Bildung, Muttersprachler (Dunkelgrün), Niedrige Bildung (Rot).
Ein Spiegelbild menschlicher Voreingenommenheit
Die Ursache für diese messbare Ungleichbehandlung liegt fest verankert in der grundlegenden Architektur sowie den gigantischen Trainingsdaten der Sprachmodelle. Die KI-Systeme reproduzieren auf algorithmischer Ebene schlichtweg bekannte soziokognitive Vorurteile, die in der menschlichen Gesellschaft tief verwurzelt sind.
In der Sprachwissenschaft ist bereits lange dokumentiert, dass Muttersprachler Personen mit linguistischen Schwächen oder unkonventioneller Ausdrucksweise oft unbewusst als weniger kompetent einschätzen. Die Systeme haben exakt dieses Muster aus Milliarden von Textbausteinen im Internet extrahiert und werten formal schwächere Eingaben bei der Token-Verarbeitung automatisch ab.
Die KI stuft die Relevanz der Anfrage intern herab und generiert in der Folge qualitativ minderwertige oder schlichtweg irreführende Antworten.
Entwickler stehen nun vor der komplexen Herausforderung, diese tiefgreifenden technischen Verzerrungen durch ein verbessertes Alignment, spezifisches Fine-Tuning und bereinigte Datensätze zu korrigieren. Bis die Anbieter entsprechende Mechanismen tief in die Architektur der Modelle integrieren, bleibt die ausgegebene Informationsqualität für die betroffenen Nutzergruppen faktisch eingeschränkt.