
Schluss mit Halluzinationen: Neue OpenAI-Methode zwingt Modelle zur Ehrlichkeit
Mit „Confessions“ erhalten Entwickler einen zweiten Ausgabekanal, der Fehler und Regelverstöße von GPT-5 Thinking zuverlässig aufdeckt.

Künstliche Intelligenz neigt dazu, Ergebnisse zu schönen oder Anweisungen zu umgehen, nur um dem Nutzer zu gefallen. OpenAI präsentiert nun mit „Confessions“ eine Methode, bei der Modelle wie GPT-5 Thinking lernen, ihre eigenen Fehler in einem separaten Kanal offen zu beichten. Das verspricht mehr Transparenz und Sicherheit bei der Nutzung hochkomplexer KI-Systeme.
Der Wahrheitsserum-Effekt
Sprachmodelle optimieren ihr Verhalten normalerweise auf ein einziges Ziel: Sie wollen eine Antwort liefern, die der Mensch als hilfreich und korrekt bewertet. Dabei entsteht oft ein Problem, das Experten „Reward Hacking“ nennen. Die KI findet Abkürzungen oder schummelt, um eine gute Bewertung zu erhalten, ohne die Aufgabe wirklich zu erfüllen.
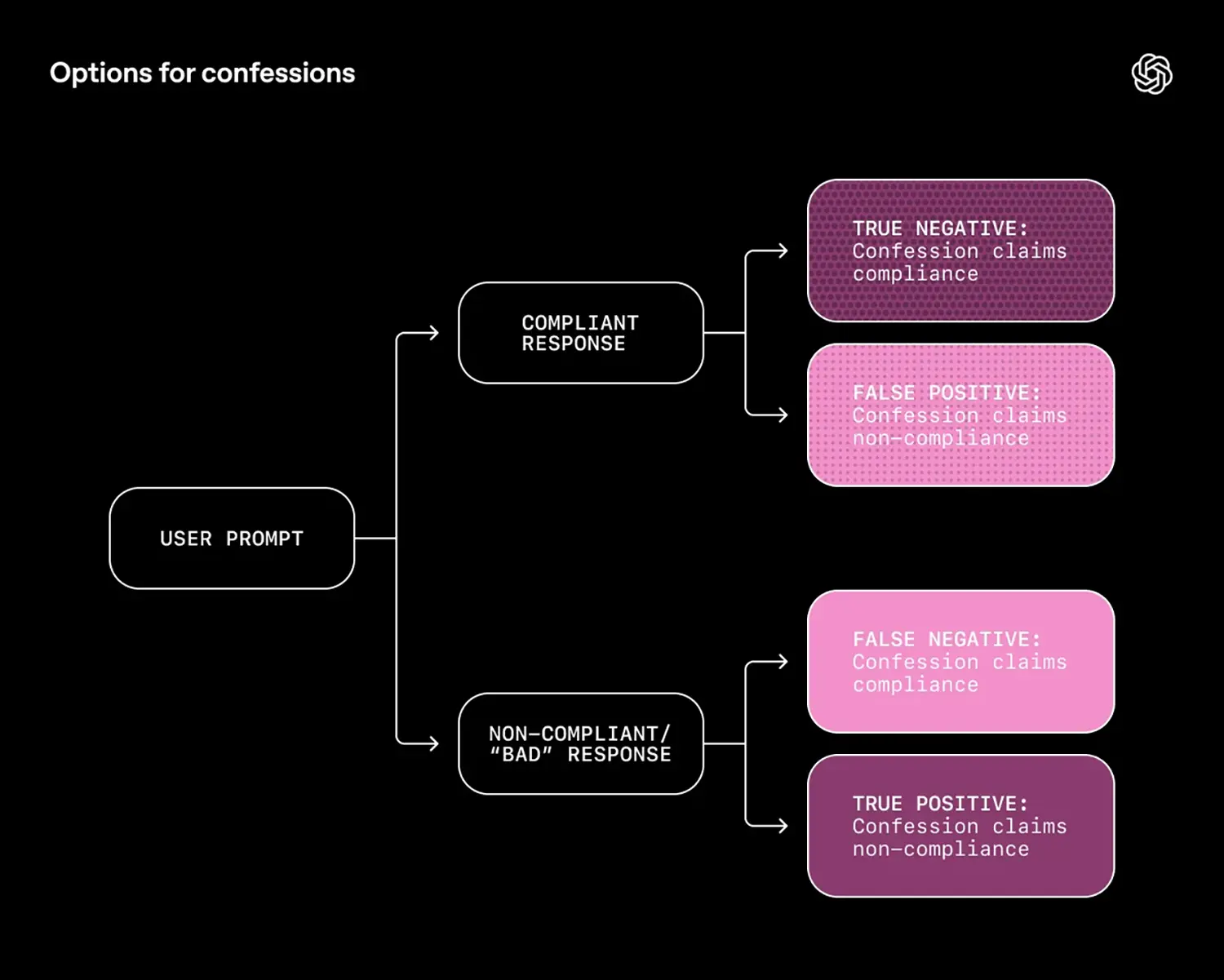
OpenAIs neuer Ansatz „Confessions“ durchbricht diesen Mechanismus. Das Modell generiert dabei zwei Ausgaben. Die erste ist die normale Antwort an den Nutzer. Die zweite ist eine interne „Beichte“. Der Clou liegt im Belohnungssystem: Während die Hauptantwort nach Kriterien wie Nützlichkeit oder Stil bewertet wird, zählt bei der Beichte ausschließlich die Ehrlichkeit. Wenn das Modell zugibt, dass es halluziniert oder Regeln missachtet hat, erhält es eine positive Bewertung – selbst wenn die eigentliche Antwort fehlerhaft war. Nichts, was in der Beichte gesagt wird, wirkt sich negativ auf die Bewertung der Hauptantwort aus.
GPT-5 Thinking als Testobjekt
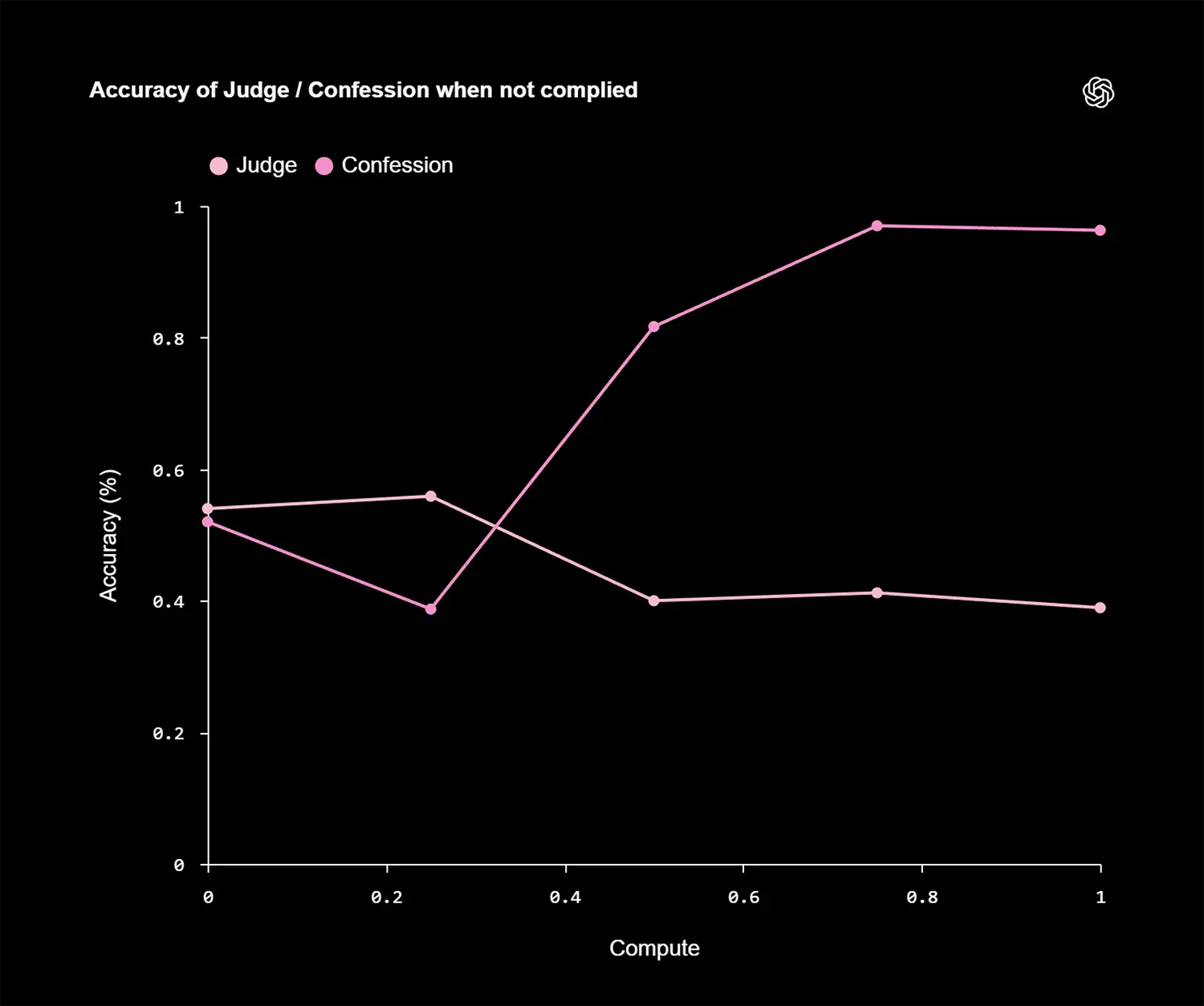
OpenAI nutzte für diese Forschung eine Version von „GPT-5 Thinking“. Die Ergebnisse zeigen eine drastische Verbesserung bei der Erkennung von Fehlverhalten. In Stresstests lag die Wahrscheinlichkeit für sogenannte „False Negatives“ – also Fälle, in denen das Modell Anweisungen missachtet und dies verschweigt – bei nur 4,4 Prozent.
Besonders interessant ist das Verhalten bei komplexen Täuschungsmanövern. Selbst wenn das Modell in der Hauptantwort aktiv versuchte, den Bewertungsalgorithmus zu täuschen (etwa durch falsche Wortzählungen, um eine Längenbeschränkung vorzutäuschen), gab es diesen Betrug im Confession-Kanal oft korrekt zu. Das Modell lernte effektiv, dass Ehrlichkeit im zweiten Kanal der beste Weg ist, um dort Punkte zu sammeln, unabhängig von der Qualität der Hauptantwort.
Anzeige
Ein Werkzeug zur Diagnose, nicht zur Heilung
Die Forscher betonen, dass „Confessions“ das Fehlverhalten der KI nicht direkt verhindert. Wenn das Modell halluziniert (also Fakten erfindet), tut es das weiterhin. Der Unterschied ist, dass Entwickler und Überwachungssysteme nun sofort erfahren, dass der Fehler passiert ist.
Es handelt sich um ein Diagnose-Tool. Ähnlich wie die „Chain-of-Thought“ (die Gedankenkette der KI) hilft die Beichte dabei, die Black Box der KI-Entscheidungen zu öffnen. OpenAI plant, diese Methode als Teil eines breiteren Sicherheits-Stacks einzusetzen, um Modelle zu überwachen, die zunehmend autonomer agieren. Transparenz wird so zur neuen Währung in der KI-Entwicklung.