
Live-Benchmark aus dem Alltag: Inclusion Arena räumt auf
Statt künstlicher Tests zeigt dieser Ansatz, welches Sprachmodell im echten Einsatz überzeugt. Welche Modelle führen das neue Ranking an?

gpt-image-1 | All-AI.de
EINLEITUNG
Sprachmodelle wie ChatGPT oder Claude liefern beeindruckende Antworten – aber wie gut sind sie wirklich im Alltag? Die neue Plattform „Inclusion Arena“ will genau das herausfinden. Statt im Labor zu testen, setzt sie auf Daten aus echten Anwendungen. Der Trick: Nutzer vergleichen Antworten von KI-Modellen im laufenden Chat, ohne zu wissen, welches Modell dahintersteckt. Das Ergebnis ist ein Live-Ranking, das zeigt, welche Modelle Menschen tatsächlich bevorzugen.
NEWS
Modelle im echten Einsatz vergleichen
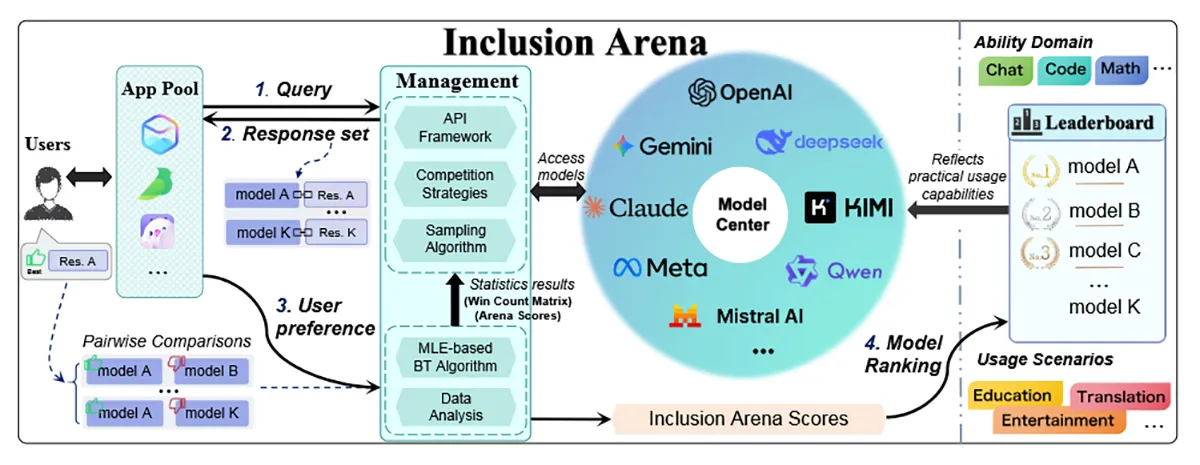
Viele Benchmarks bewerten KI-Modelle mit festgelegten Aufgaben oder Datensätzen. Das Problem: Sie sagen oft wenig darüber aus, wie ein Modell im Alltag funktioniert. Inclusion Arena geht deshalb einen anderen Weg. Die Plattform hängt sich in echte Apps, etwa einen Chat für Rollenspiele und eine App für Bildungskommunikation. Dort liefern mehrere Modelle gleichzeitig Antworten auf Nutzereingaben. Der Nutzer wählt die beste – ohne zu wissen, von wem sie stammt.
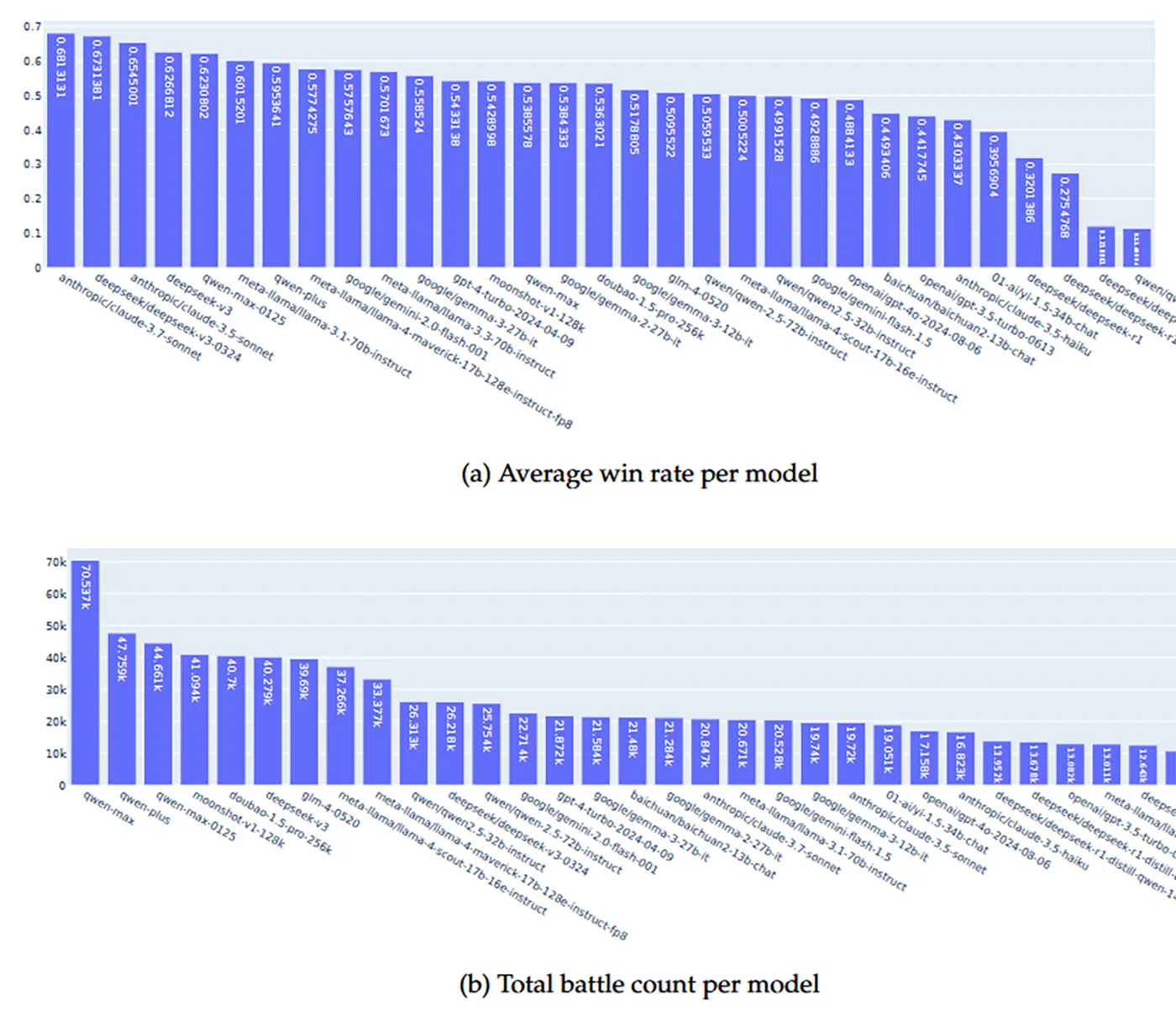
Aus diesen Entscheidungen entsteht eine Rangliste, die direkt auf Nutzerpräferenzen basiert. In der ersten Testphase kamen über 500.000 solcher Paarvergleiche zustande. Beteiligt waren mehr als 46.000 aktive Nutzer, verglichen wurden 49 verschiedene Modelle. Damit entsteht ein praxisnahes Bild davon, welche Modelle im Alltag wirklich überzeugen.
Quelle: https://arxiv.org/abs/2508.11452
Ranking mit Methode – statt reiner Bauchentscheidung
Für die Auswertung nutzt die Arena das Bradley-Terry-Modell. Es berechnet die Stärke eines Modells anhand vieler direkter Duelle – ähnlich wie ein Schachranking, nur mit statistischem Feinschliff. Damit die Bewertung auch bei vielen Modellen effizient bleibt, werden neue Teilnehmer zuerst in sogenannten Placement Matches einsortiert. Danach treten sie vor allem gegen Modelle auf ähnlichem Niveau an. Das spart Rechenleistung und macht das Ranking stabiler.
Im Unterschied zu offenen Plattformen wie Chatbot Arena läuft alles im Hintergrund echter Anwendungen. Das macht Manipulation schwieriger und die Daten relevanter für Unternehmen, die auf der Suche nach einem passenden Modell für ihre eigenen Produkte sind.
Quelle: https://arxiv.org/abs/2508.11452
Ergebnisse mit Potenzial – aber noch begrenzt
Die ersten Ergebnisse zeigen bekannte Namen an der Spitze: Modelle von Anthropic und DeepSeek führen das Feld an. Qwen-Modelle von Alibaba sind ebenfalls gut platziert. Damit decken sich die Ergebnisse teilweise mit bestehenden Benchmarks – zeigen aber, welche Modelle in echten Nutzerkontexten gut ankommen.
Noch ist die Auswahl an Apps begrenzt, die das Ranking speisen. Deshalb planen die Macher, Inclusion Arena über eine offene Allianz auszuweiten. Ziel ist eine Plattform, die möglichst viele Anwendungen abdeckt und langfristig ein realistisches Bild vom Modellvergleich im Alltag liefert.
Für Unternehmen zählt der Praxistest
Gerade für Unternehmen, die LLMs in ihre Produkte integrieren wollen, ist ein Benchmark aus echten Nutzungsszenarien besonders wertvoll. Wer wissen will, welches Modell bei Kunden gut ankommt, braucht Daten aus der Praxis – nicht nur gute Ergebnisse bei Schulaufgaben.
Mit Plattformen wie Inclusion Arena und neuen Benchmarks wie RewardBench 2 zeigt sich ein klarer Trend: weg vom Labor, hin zum Alltag. Die Auswahl an Modellen wächst, und damit auch der Bedarf an Orientierung. Realitätsnahe Ranglisten könnten bald zur wichtigsten Entscheidungsgrundlage für den KI-Einsatz im Unternehmen werden.
DEIN VORTEIL - DEINE HILFE
KURZFASSUNG
- Die Inclusion Arena wertet KI-Modelle anhand echter Nutzerpräferenzen in realen Anwendungen aus.
- Mit über 500.000 Paarvergleichen liefert sie ein praxisnahes Live-Ranking von 49 Modellen.
- Das Verfahren nutzt das Bradley-Terry-Modell und setzt auf smarte Duelle zwischen ähnlich starken Modellen.
- Für Unternehmen entsteht damit eine neue Entscheidungsgrundlage für den Einsatz von LLMs in der Praxis.