
Qwen 3.5 Omni Plus schlägt Gemini 3.1 Pro
Qwen liefert mit der neuen Omni-Generation beeindruckende Benchmark-Ergebnisse und verbesserte Echtzeit-Funktionen für Audio und Video.

Qwen stellt mit Qwen 3.5 Omni Plus und der zugehörigen Realtime-Version die nächste Generation seiner KI-Modelle vor. Die neuen Modelle schlagen Gemini 3.1 Pro in zahlreichen Audio-Tests und bieten weitreichende Verbesserungen bei der Verarbeitung langer Kontexte.
Die Architektur hinter der Omni-Verarbeitung
Der Begriff »Omni« steht bei den neuen Modellen für die Fähigkeit, Text, Bilder, Audio und audiovisuelle Inhalte nativ und parallel zu verarbeiten. Das System erfasst die unterschiedlichen Eingabedaten direkt, ohne sie vorher in reinen Text umzuwandeln.
Die Basis von Qwen 3.5 Omni bildet eine Hybrid-Attention MoE-Architektur. Das Kürzel MoE bedeutet Mixture of Experts und sichert eine hohe Effizienz bei der Berechnung. Sowohl die Komponente für das logische Schließen, der sogenannte »Thinker«, als auch das Sprachmodul, der »Talker«, greifen auf diese Struktur zurück.
Die Modelle analysieren ein Kontextfenster von bis zu 256.000 Token. Damit werten Fachanwender mehr als zehn Stunden reines Audiomaterial oder über 400 Sekunden an Videomaterial in einer Auflösung von 720p am Stück aus.
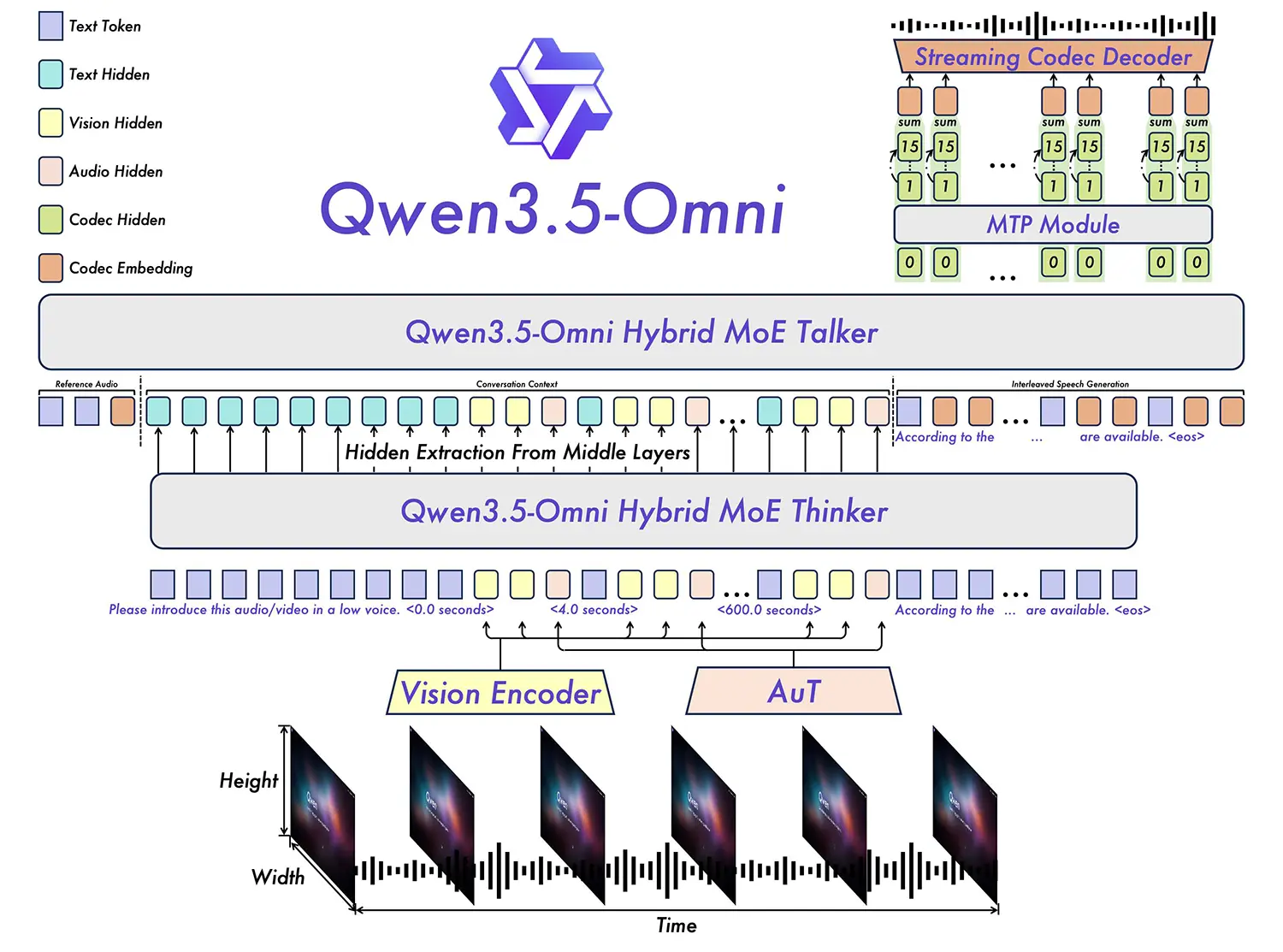
Quelle: Qwen
Zwei Wege für Entwickler: Offline-Analyse und Echtzeit-Dialog
Programmierer steuern die neuen KI-Modelle über zwei verschiedene Schnittstellen an. Die klassische Offline-API eignet sich primär für die Analyse großer, bereits aufgezeichneter Datenmengen. Hier liegt der Fokus auf der genauen Auswertung komplexer Dokumente oder der inhaltlichen Zusammenfassung langer Videos.
Die Realtime-Version zielt exakt auf die direkte Konversation ab. Qwen integriert hier neue Funktionen wie semantische Unterbrechungen. Das KI-Modell erkennt sofort, wenn eine Person ins Wort fällt, und passt seine eigene Antwort dynamisch an den neuen Kontext an.
Zusätzlich bietet die Echtzeit-Schnittstelle das direkte Klonen von Stimmen und eine schnelle Sprachsteuerung. Durch den Einsatz der neuen ARIA-Technologie klingen die synthetischen Stimmen natürlicher und bleiben auch bei langen Unterhaltungen fehlerfrei. Das Modell versteht Eingaben in 113 Sprachen und Dialekten, während die Sprachausgabe 36 Sprachen abdeckt.
Anzeige
Konkrete Benchmark-Ergebnisse für Audio und visuelle Daten
Qwen 3.5 Omni Plus erzielt in aktuellen Tests insgesamt 215 Bestwerte. Diese SOTA-Ergebnisse verteilen sich auf die Bereiche Audio- und Videoverständnis, logisches Reasoning sowie die direkte Interaktion. Die Entwickler trainierten die KI-Modelle mit umfangreichen Text- und Bilddatensätzen sowie über 100 Millionen Stunden an audiovisuellem Material.
Im Segment der audiovisuellen Aufgaben liefert das direkte Duell mit Gemini 3.1 Pro ein differenziertes Bild. Qwen 3.5 Omni Plus punktet bei der Text Query QA im DailyOmni-Test mit 84,6 zu 82,7 Punkten und übertrifft das Google-Modell beim Omni-Cloze-Benchmark für Captions mit 64,8 zu 57,2 deutlich. Gemini 3.1 Pro behält jedoch bei der VideoMME-Auswertung mit 89,0 zu 83,7 die Oberhand.

Quelle: Qwen
Bei den reinen Audiotests dominiert Qwen in wesentlichen Disziplinen. Im VoiceBench-Dialogtest verbucht Qwen 3.5 Omni Plus starke 93,1 Punkte und schlägt Gemini 3.1 Pro, das hier auf 88,9 Punkte kommt. Auch bei der Spracherkennung im Fleurs-Test liefert das Modell mit einem Messwert von 6,55 das exaktere Resultat im Vergleich zu den 7,32 des Konkurrenten.
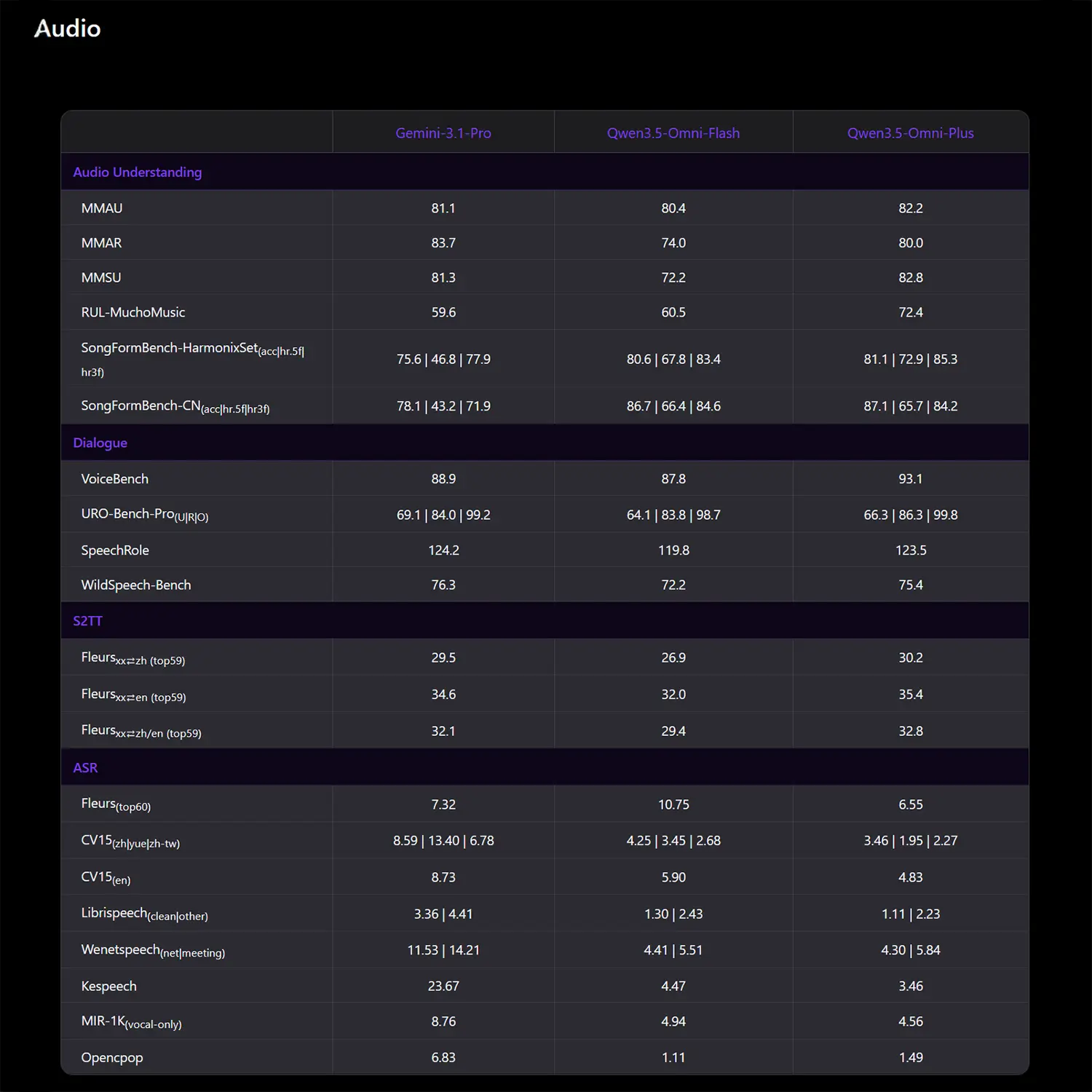
Quelle: Qwen
Leistungssprünge bei Text, Bild und Sprachsynthese
Die visuelle Analysefähigkeit beweist das neue Modell durch konstante Ergebnisse in anspruchsvollen Kategorien. Im MMMU-Test für mathematisch-naturwissenschaftliche Aufgaben erreicht Qwen 3.5 Omni Plus exakt 80,1 Punkte. Bei der allgemeinen Beantwortung von Fragen zu Bildern im RealWorldQA-Benchmark sichert sich das System 84,1 Punkte, während es bei der reinen Videoauswertung im VideoMME-Test auf 81,9 Punkte kommt.
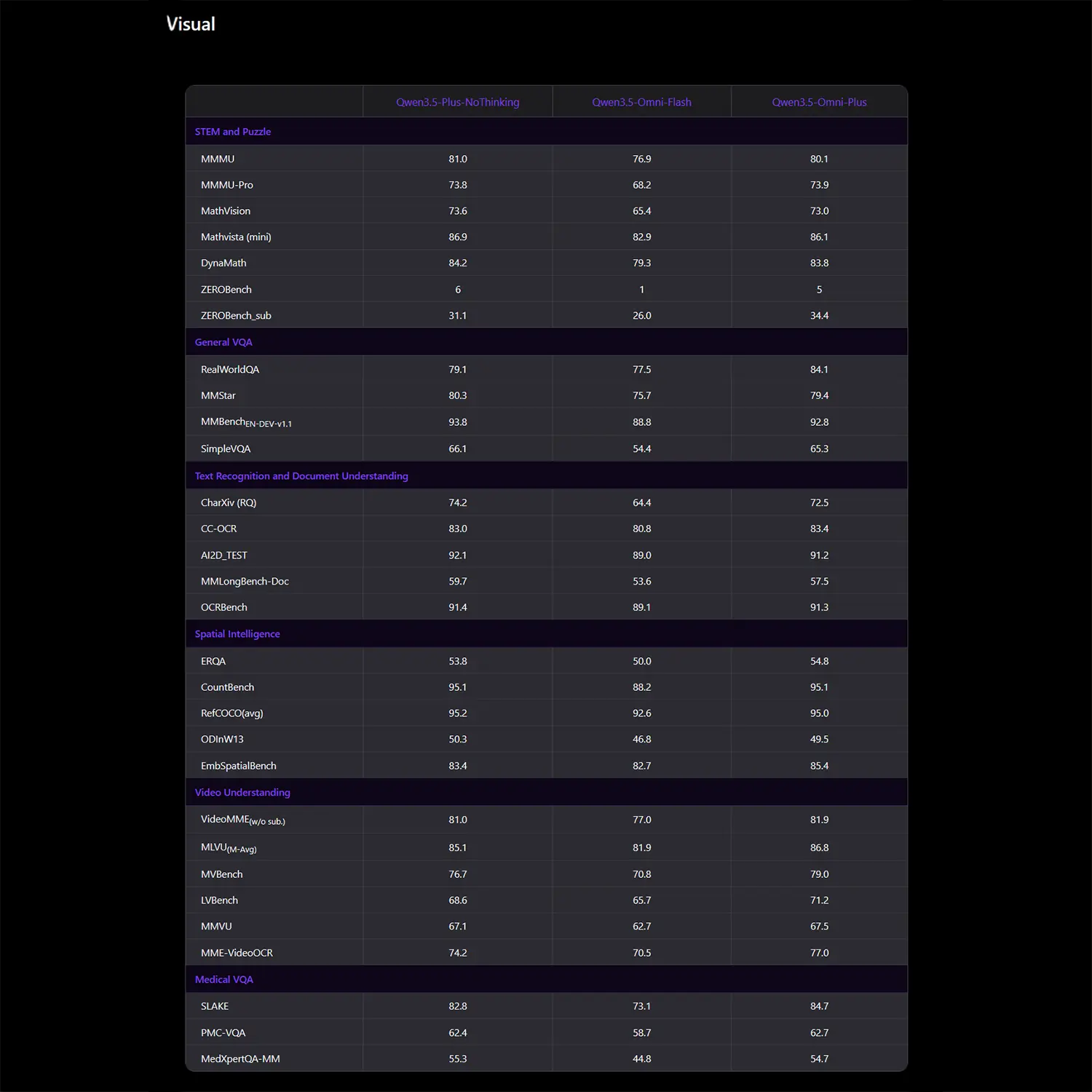
Quelle: Qwen
Im klassischen Textverständnis liefert das KI-Modell verlässliche Werte für komplexe Anforderungen. Das System erreicht beim Wissenstest MMLU-Pro 85,9 Punkte und erzielt im IFEval-Benchmark für das strikte Befolgen von Instruktionen 89,7 Punkte. Bei den speziellen Reasoning-Aufgaben im LiveCodeBench v6 steht zudem ein solides Ergebnis von 65,6 Punkten auf dem Papier.
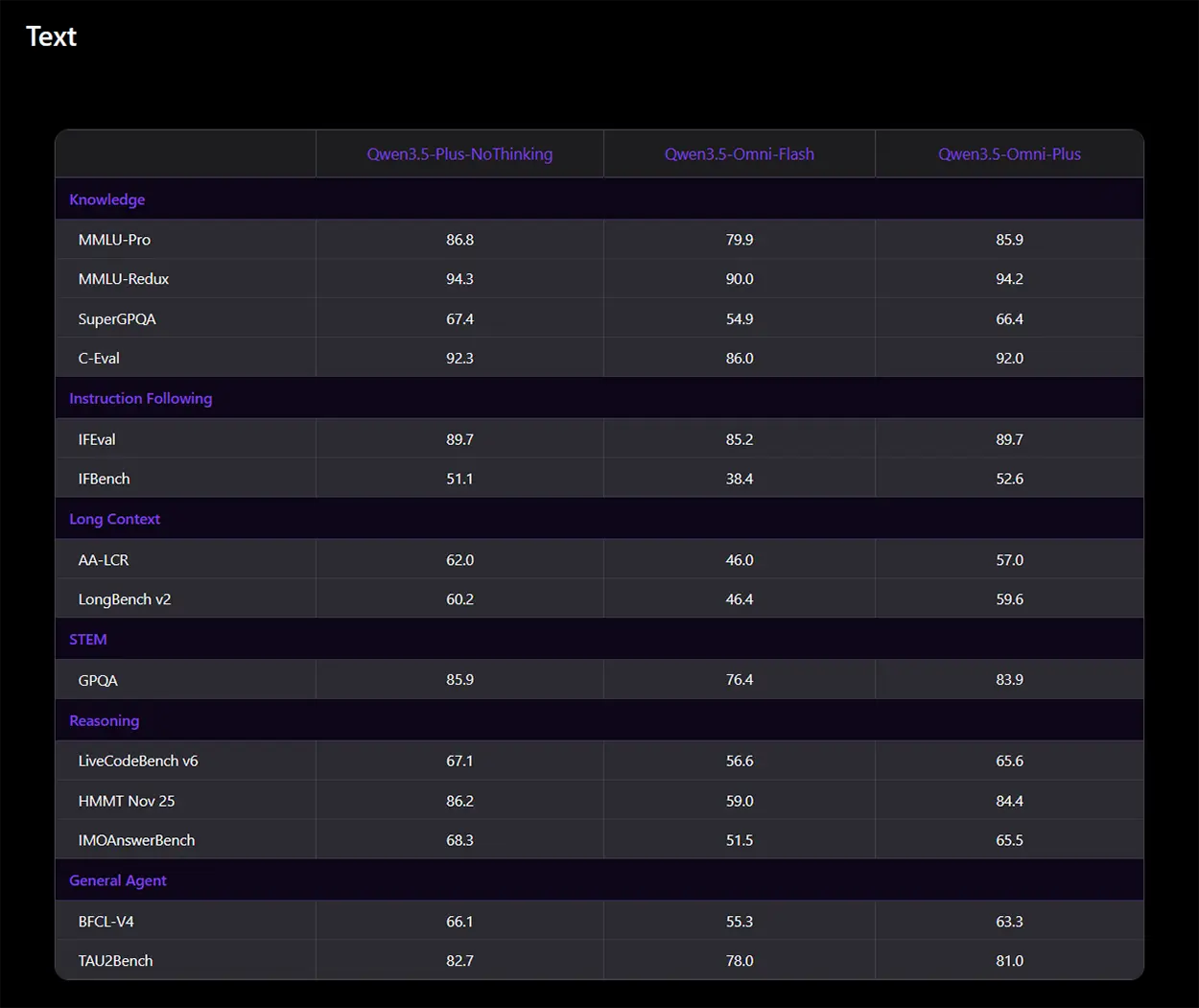
Quelle: Qwen
Die Sprachsynthese und das Klonen von Stimmen testet der Benchmark im direkten Vergleich mit etablierten Spezialisten wie ElevenLabs und GPT-Audio. Qwen 3.5 Omni Plus glänzt bei der Stabilität der geklonten Stimmen im mehrsprachigen Test mit einem niedrigen Fehlerwert von 1,87 und lässt ElevenLabs mit 10,29 weit hinter sich. Auch bei der Metrik für generelle Sprachstabilität unterbietet Qwen mit 5,82 den Messwert von Gemini 2.5 Pro, das hier 6,61 erreicht.
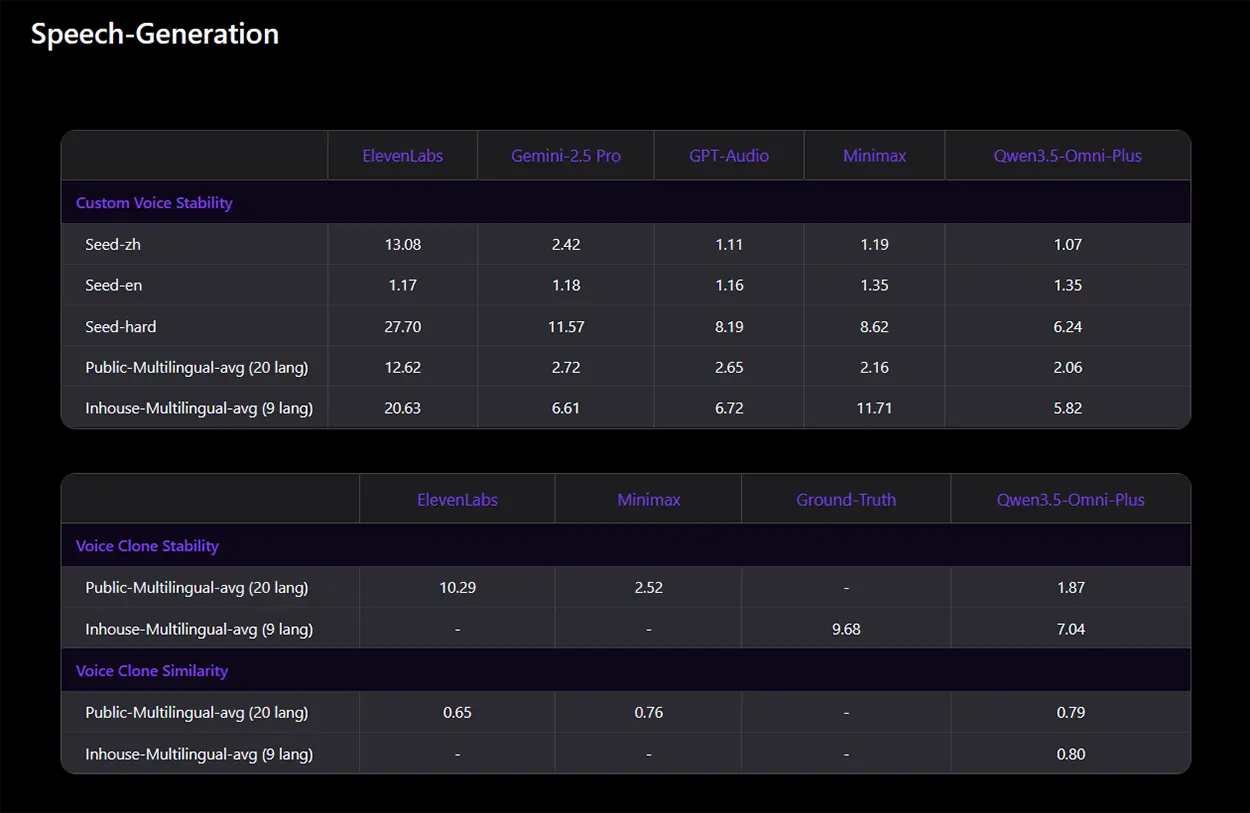
Quelle: Qwen
Der Entwicklungssprung von Version 3 auf 3.5
Die Vorgängerversion legte den Grundstein für die multimodale Verarbeitung bei Qwen. Das Update auf Version 3.5 erweitert diese Fähigkeiten nun gezielt um eine exaktere Mehrsprachigkeit und ein tieferes inhaltliches Verständnis für hochauflösende Videos.
Das neue Modell behält den inhaltlichen Faden in sehr langen Unterhaltungen nun deutlich besser bei. Softwareentwickler erhalten somit eine präzise Lösung für komplexe und andauernde Aufgaben. Die Modelle Qwen 3.5 Omni Plus sowie die Realtime-Variante stehen ab sofort über die offizielle API zur Verfügung.