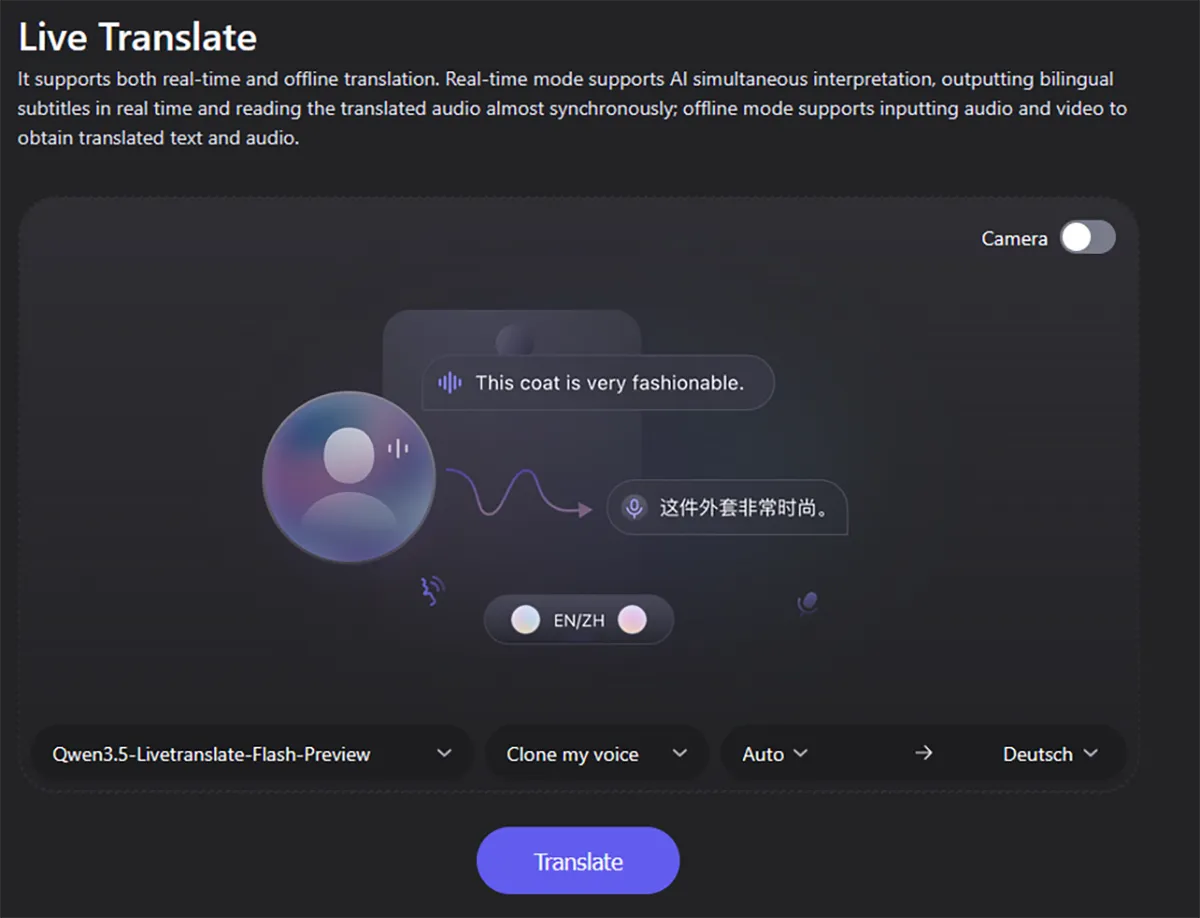
Qwen übersetzt simultan mit deiner Originalstimme
Qwen3.5-LiveTranslate-Flash übersetzt mit einer Latenz von unter drei Sekunden und behält dabei das Stimmprofil bei.

Mit Qwen3.5-LiveTranslate-Flash steht ein neues, multimodales KI-Modell für die Echtzeit-Übersetzung bereit. Die KI interpretiert gesprochene Sprache sowie visuelle Kontexte simultan. Dabei übersetzt das KI-Modell in Dutzende Sprachen und imitiert direkt die Originalstimme des Sprechers.
Schneller sprechen in vielen Sprachen
Für flüssige Gespräche senkt Qwen3.5-LiveTranslate-Flash die Latenz erheblich. Pro Token vergehen nun durchschnittlich nur noch 2,8 Sekunden bis zur hörbaren Sprachausgabe.
Eine spezielle Technologie zur Verarbeitung sogenannter Lese-Einheiten ermöglicht diese Geschwindigkeit. Gleichzeitig bleibt der semantische Sinn der übersetzten Sätze vollständig erhalten.
Deutlich gewachsen ist zudem das sprachliche Repertoire des KI-Modells. Die Eingabe versteht mittlerweile 60 verschiedene Sprachen, während die Audioausgabe 29 Zielsprachen fließend abdeckt.
Ausprobieren kann man das hier: Qwen Live
Quelle: Alibaba
Visuelles Verständnis und Fachbegriffe
Bemerkenswert an Qwen3.5-LiveTranslate-Flash ist die zugrundeliegende multimodale Architektur. Die KI verlässt sich bei der Übersetzung nicht nur auf den reinen Audiostream.
Das KI-Modell analysiert parallel visuelle Informationen wie eingeblendete Texte oder physisch gezeigte Objekte. Diese intelligente Kontextualisierung hilft der KI, mehrdeutige Wörter passend zur Situation präzise zu übersetzen.
Für anspruchsvolle Fachgespräche bietet die Architektur eine dynamische Konfiguration von Schlüsselwörtern. Spezifische Markennamen oder medizinische Fachbegriffe übersetzt die KI dadurch wesentlich verlässlicher.

Quelle: Alibaba
Echtzeit-Klonen der Originalstimme
Während der laufenden Simultanübersetzung klont Qwen3.5-LiveTranslate-Flash die charakteristischen Stimmmerkmale des ursprünglichen Sprechers. Ein einzelner gesprochener Satz reicht der KI für diese komplexe akustische Anpassung aus.
Zuhörer nehmen die übersetzte Sprache dadurch deutlich natürlicher wahr. Besonders bei internationalen Konferenzen oder in Livestreams entsteht so eine authentische Gesprächsatmosphäre.
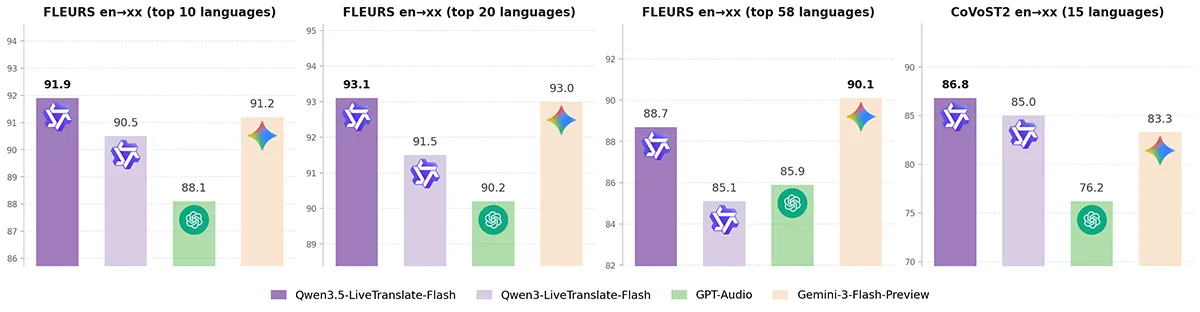
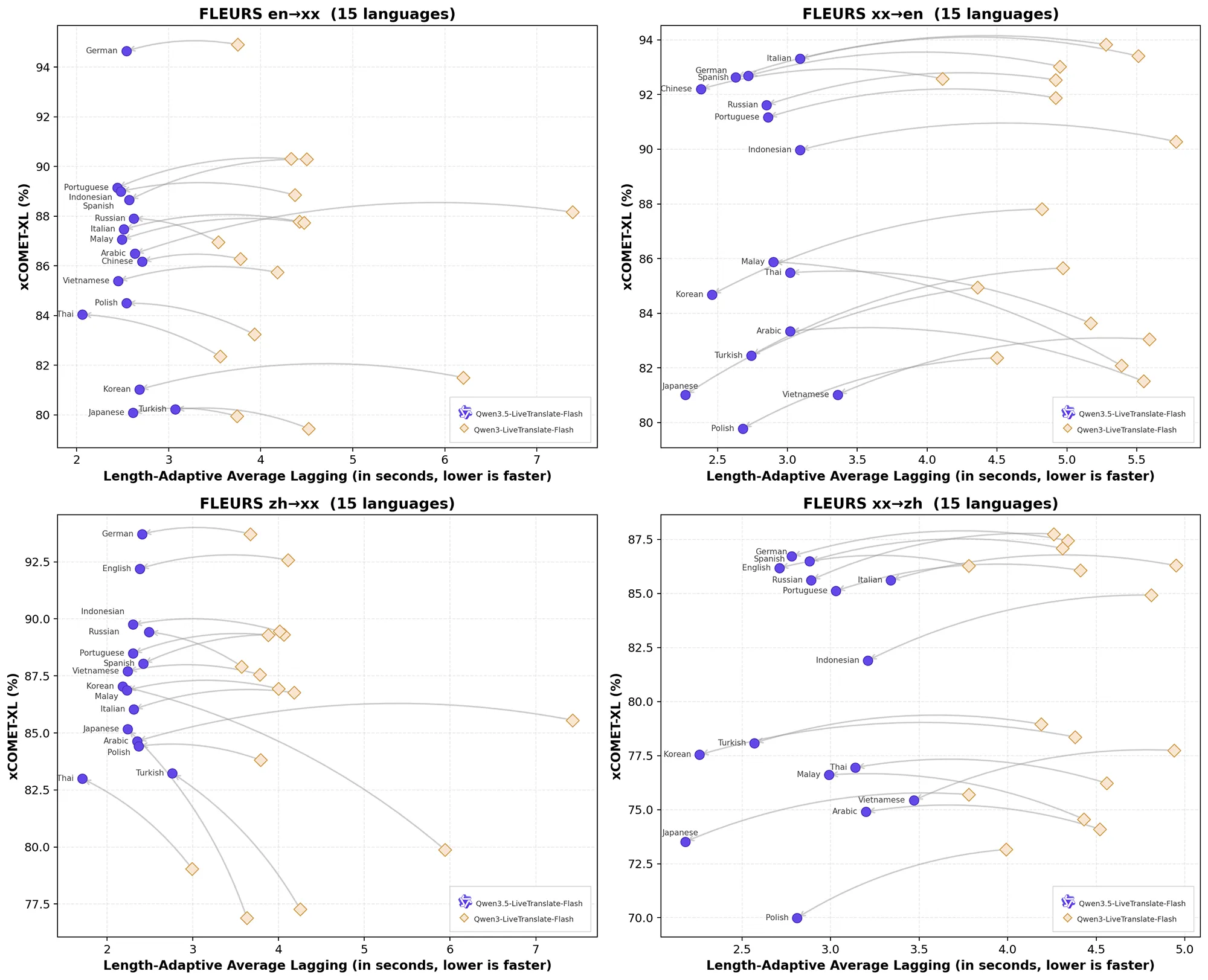
In etablierten Benchmarks wie FLEURS oder CoVoST2 übertrifft dieses KI-Modell gängige kommerzielle Konkurrenten. Zukünftige Entwicklungen fokussieren sich auf noch geringere Latenzen und die Integration spezieller regionaler Dialekte.