
Lokales Schreiben mit über 1.000 Token pro Sekunde
Mit DiffusionGemma von Google läuft die Textgenerierung auf lokalen Grafikkarten jetzt viermal schneller als gewohnt.

Google hat heute mit DiffusionGemma ein experimentelles KI-Modell veröffentlicht. Die Software generiert Text nicht mehr linear Wort für Wort, sondern berechnet ganze Absätze gleichzeitig. Das erhöht die Geschwindigkeit auf lokalen Grafikkarten um das Vierfache.
Text-Diffusion statt Schreibmaschine
Bisherige KI-Modelle arbeiten autoregressiv und setzen Text wie eine Schreibmaschine Wort für Wort zusammen. Das ist in Rechenzentren effizient, wenn Server tausende Anfragen bündeln.
Auf einer lokalen Grafikkarte entsteht dabei jedoch Leerlauf. Der Prozessor wartet ständig auf den nächsten Schritt.
DiffusionGemma ändert dieses Prinzip. Das KI-Modell nutzt eine Technik, die bisher vor allem bei der Bildgenerierung zum Einsatz kam. Es beginnt mit einem Raster aus zufälligen Platzhaltern.
In mehreren Durchgängen verfeinert die Software diese Platzhalter zu sinnvollen Wörtern. Der Prozessor berechnet dadurch 256 Token parallel. Google vergleicht diesen Vorgang mit einer Druckerpresse, die einen kompletten Textblock in einem einzigen Arbeitsschritt erzeugt.
Anzeige
Mehr als 700 Token auf der RTX 5090
Dieser Ansatz verschiebt den Flaschenhals von der Speicherbandbreite hin zur reinen Rechenleistung. Lokale Beschleuniger werden so besser ausgelastet.
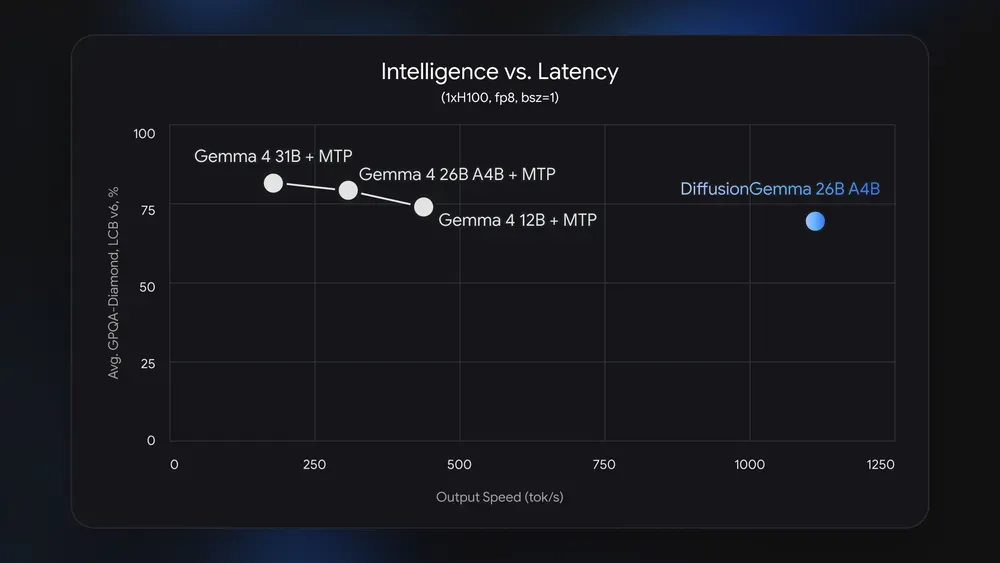
Laut den veröffentlichten Benchmarks erreicht das Modell auf einer Nvidia H100 mehr als 1000 Token pro Sekunde. Auf einer Consumer-Grafikkarte wie der Geforce RTX 5090 sind es über 700 Token pro Sekunde.
Die Architektur basiert auf einem Mixture-of-Experts-Ansatz. Das KI-Modell besitzt insgesamt 26 Milliarden Parameter, aktiviert bei einer Abfrage aber nur 3,8 Milliarden.
Das senkt die Hardware-Anforderungen erheblich. In einer quantisierten Version passt die Software in den 18-Gigabyte-Speicher aktueller High-End-Grafikkarten.

Bidirektionale Aufmerksamkeit löst Sudokus
Diese parallele Berechnung ermöglicht völlig neue Anwendungsfälle. Da alle 256 Token zeitgleich entstehen, kann jedes Wort den Kontext aller anderen Wörter berücksichtigen.
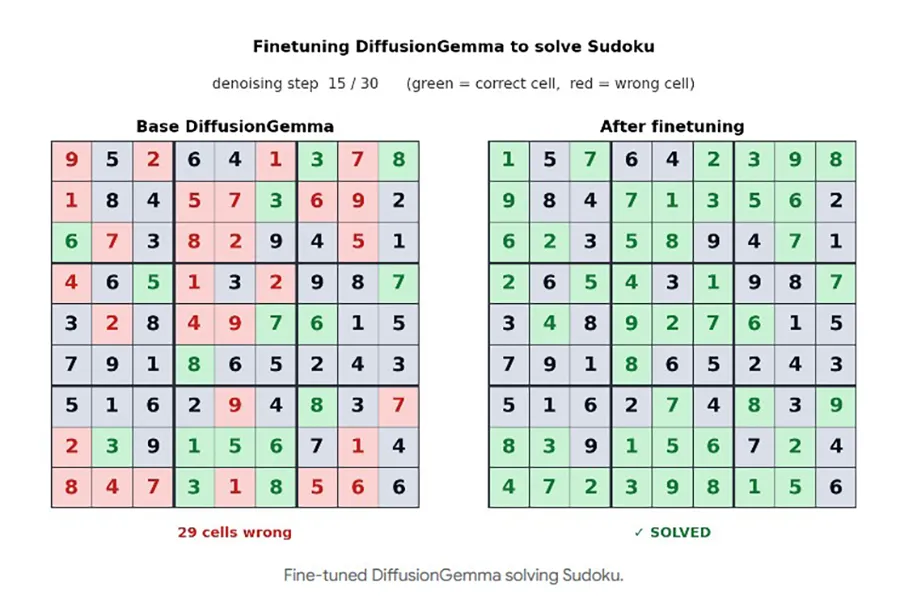
Diese bidirektionale Aufmerksamkeit hilft besonders bei nicht-linearen Problemen. Google demonstriert das in seinen Benchmarks anhand von Sudoku.
Klassische Modelle scheitern bei diesem Rätsel oft, da jedes generierte Zeichen bereits die genaue Vorhersage zukünftiger Zahlen erfordert. DiffusionGemma löst solche Aufgaben durch die parallele Auswertung leichter.
Die Software eignet sich durch diese Architektur für Code-Infilling oder interaktives Editieren in Echtzeit. Das System erkennt und korrigiert eigene Fehler direkt während der Block-Generierung.
Quelle: Google
Kompromisse bei der Textqualität
Die hohe Geschwindigkeit geht jedoch zulasten der Textqualität. Die allgemeine Textqualität liegt unter der des regulären Gemma-4-Modells.
Für produktive Aufgaben mit hohem Qualitätsanspruch empfiehlt Google weiterhin die autoregressive Variante. Wer die schnelle Text-Diffusion selbst testen möchte, findet das Modell unter einer Apache-2.0-Lizenz auf Hugging Face.





