
Google stellt Gemini 3.1 Flash Live für Audio vor
Die neue Architektur überzeugt in ersten Tests durch hohe Genauigkeit und schnelle Reaktionszeiten bei komplexen Aufgaben.

Google veröffentlicht mit Gemini 3.1 Flash Live ein neues KI-Modell für die Echtzeit-Sprachverarbeitung. Die Architektur zeigt in aktuellen Tests hohe Werte beim logischen Denken und übertrifft Konkurrenten in komplexen Audio-Szenarien.
Twitter Beitrag - Cookies links unten aktivieren.
Say hello to Gemini 3.1 Flash Live. 🗣️
— Google DeepMind (@GoogleDeepMind) March 26, 2026
Our latest audio model delivers more natural conversations with improved function calling – making it more useful and informed. Here’s what’s new 🧵 pic.twitter.com/uv8cW447kE
Fokus auf komplexe Audio-Aufgaben
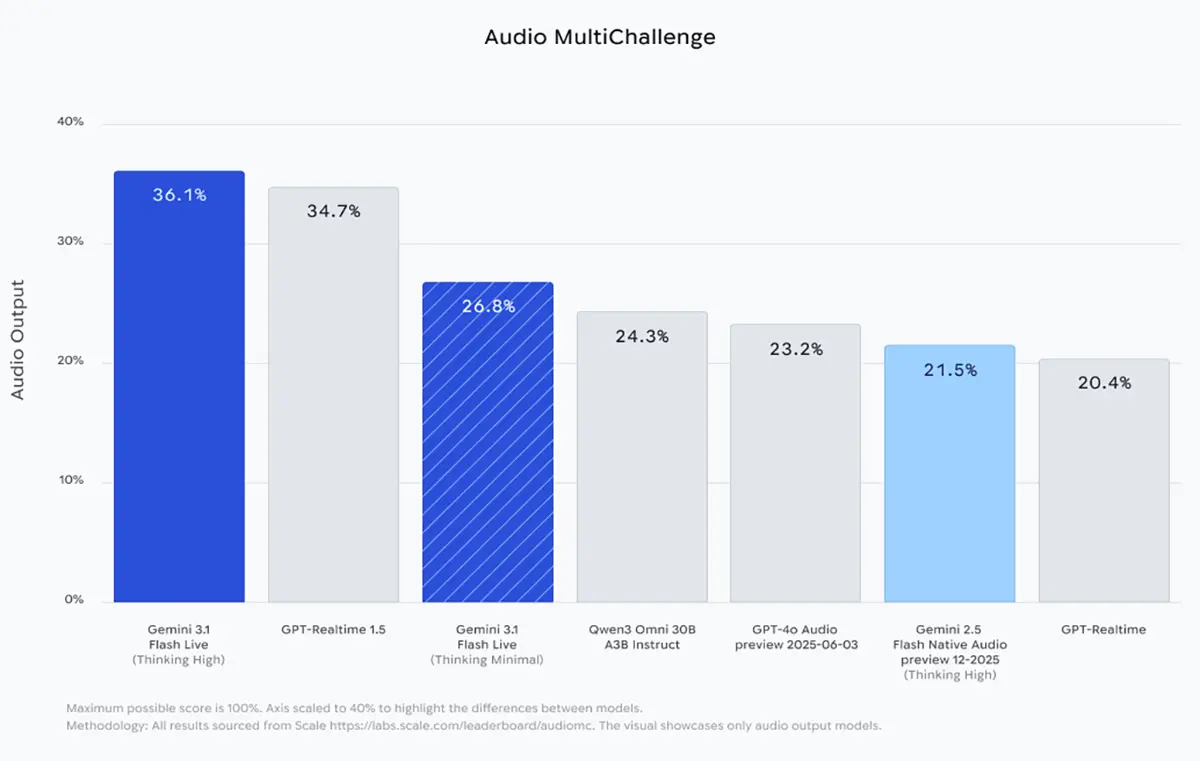
Das Modell bietet zwei Ausbaustufen für unterschiedliche technische Anforderungen. Die Variante "Thinking High" zielt auf anspruchsvolle Aufgaben ab, die eine tiefere Analyse erfordern. In der Audio MultiChallenge erreicht diese Version einen Wert von 36,1 Prozent. Damit schiebt sich das Modell knapp vor GPT-Realtime 1.5, das in diesem Benchmark bei 34,7 Prozent liegt. Die schnellere Version "Thinking Minimal" erzielt in demselben Test 26,8 Prozent.
Quelle: Google
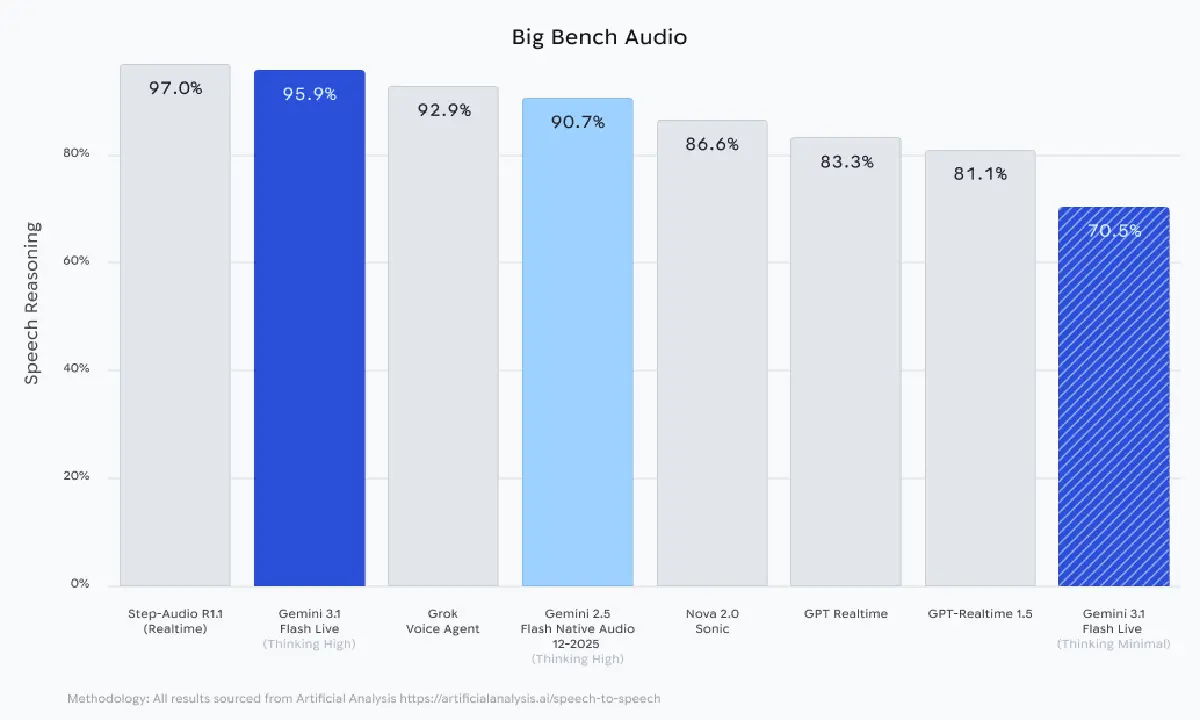
Im Big Bench Audio belegt das System seine Fähigkeiten beim Speech Reasoning. Mit 95,9 Prozent platziert sich Gemini 3.1 Flash Live in der höchsten Ausbaustufe unmittelbar hinter Step-Audio R1.1. Dieses System führt die Tabelle mit 97,0 Prozent an, während Modelle wie Grok Voice Agent (92,9 Prozent) und Nova 2.0 Sonic (86,6 Prozent) folgen.
Quelle: Google
Präzision bei Funktionsaufrufen
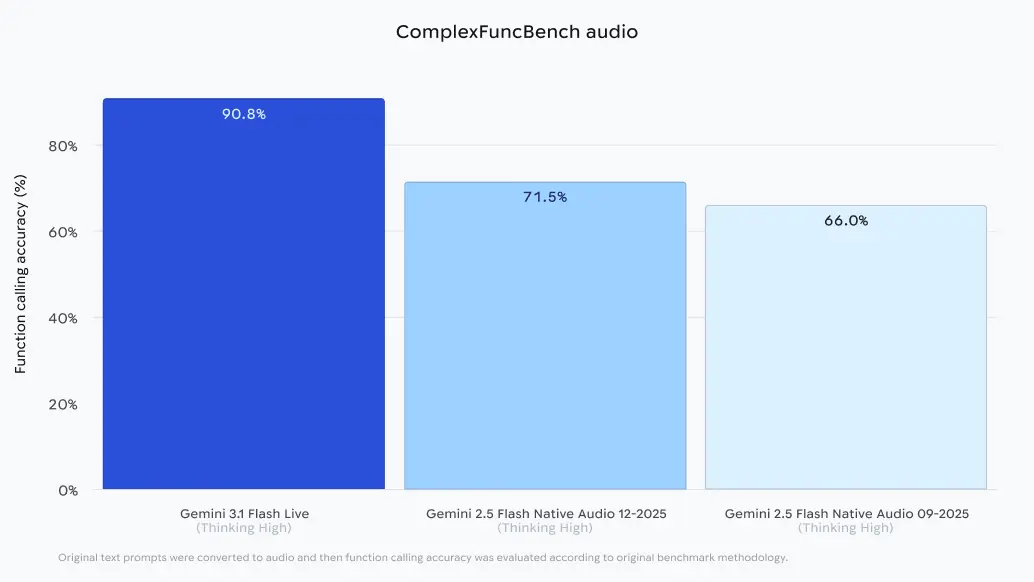
Der produktive Einsatz von KI-Modellen erfordert häufig die fehlerfreie Interaktion mit externen Systemen. Im ComplexFuncBench für Audio verzeichnet das neue Modell eine Genauigkeit von 90,8 Prozent beim Function Calling. Die Prüfer wandelten für diesen spezifischen Test textbasierte Prompts in Audio-Dateien um, um die direkte Verarbeitung gesprochener Instruktionen zu evaluieren.
Quelle: Google
Dieses Ergebnis markiert einen klaren Fortschritt gegenüber der Vorgängergeneration. Gemini 2.5 Flash Native Audio kam im Dezember 2025 auf 71,5 Prozent. Die gesteigerte Präzision verringert Fehlerquoten bei der automatisierten Ausführung von Befehlen. Durch die Aufteilung in verschiedene Leistungsstufen passen Entwickler Latenz und Antwortqualität an das jeweilige Projekt an. Das Modell bildet damit eine valide Grundlage für reaktionsschnelle Sprach-Interfaces.