
DeepSeek 4.0 mit neuem »DeepSeek-Moment«?
Mit der V4-Serie verringert das Unternehmen den Speicherbedarf massiv und unterstützt nun auch chinesische Huawei-Chips.

DeepSeek hat mit V4-Pro und V4-Flash zwei neue Modelle veröffentlicht, die ein Kontextfenster von einer Million Token bieten. Eine grundlegend überarbeitete Architektur senkt den Rechenaufwand erheblich, während die Leistungsfähigkeit in vielen Disziplinen an führende US-Konkurrenten heranreicht.
Effizienz durch neue Architektur
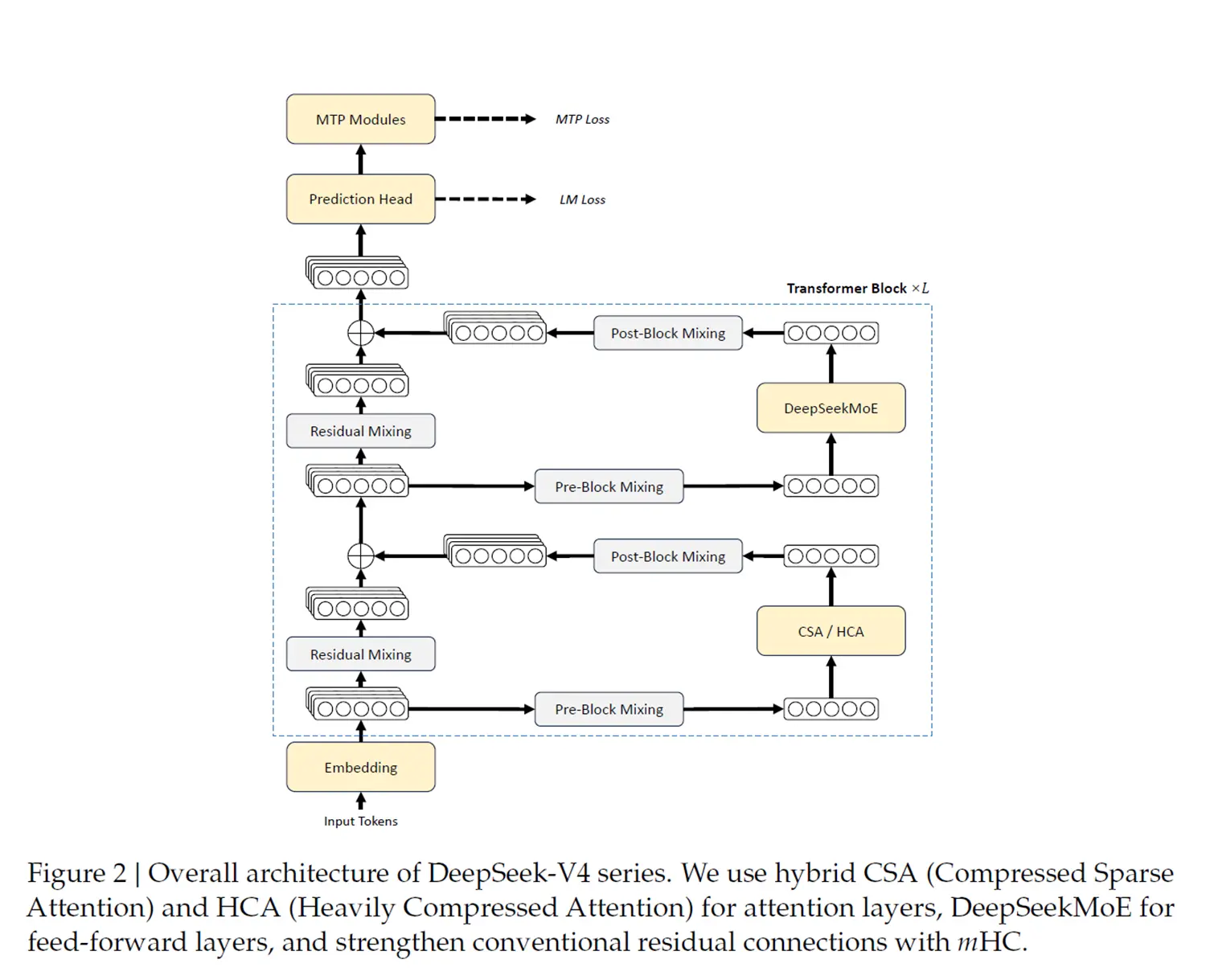
Für die Verarbeitung enormer Datenmengen setzt das Entwicklerteam auf eine ungewöhnliche Kombination aus speziellen Aufmerksamkeitsmechanismen. Mittels Compressed Sparse Attention sowie Heavily Compressed Attention sinkt der Rechenbedarf bei extrem langen Eingaben spürbar. Zieht man den direkten Vergleich zwischen dem neuen Flaggschiff V4-Pro und dem Vorgänger V3.2, benötigt das aktuelle System bei einer Million Token nur noch 27 Prozent der Rechenleistung pro Token.
Gleichzeitig schrumpft der Speicherbedarf für den internen KV-Cache auf zehn Prozent. Möglich werden solche Einsparungen erst durch den Einsatz neuartiger Komprimierungsverfahren.
Weiterhin basieren beide KI-Modelle auf der bewährten Mixture-of-Experts-Struktur. Aus einem gigantischen Pool von 1,6 Billionen Parametern aktiviert V4-Pro pro Token exakt 49 Milliarden. Noch sparsamer agiert die Flash-Variante. Hier kommen bei 284 Milliarden Gesamtparametern lediglich 13 Milliarden aktive Einheiten zum Einsatz, was eine besonders rasante Textgenerierung erlaubt. Um die fehlerfreie Signalübertragung zwischen all diesen Netzwerkschichten zu garantieren, integrierten die Programmierer zudem speziell modifizierte Hyper-Verbindungen.
Quelle: DeepSeek
Hardware-Unabhängigkeit und Optimierung
Besonders interessant zeigt sich die Hardware-Kompatibilität der neuen Modelle. Neben herkömmlichen Grafikprozessoren von Nvidia schlossen die Ingenieure sämtliche Trainings- und Validierungsläufe erfolgreich auf Huawei Ascend NPUs ab. Durch diesen strategischen Schritt demonstriert das Unternehmen eine klare technische Unabhängigkeit von amerikanischen Hardware-Anbietern.
Zusätzlich sorgt bei der Optimierung der Algorithmen nun der sogenannte Muon-Optimizer für Stabilität. Dieser beschleunigt die Konvergenz während der kritischen Trainingsphase spürbar. Auch im Bereich der Berechnungsgenauigkeit sparen die Entwickler geschickt wertvolle Ressourcen ein, indem sie FP4-Quantisierung nutzen. Auf den Servern bleibt der physische Speicherbedarf dadurch gering, ohne dass die inhaltliche Qualität der Antworten abnimmt.
Anzeige
Benchmarks: stark, aber nicht überall vorn
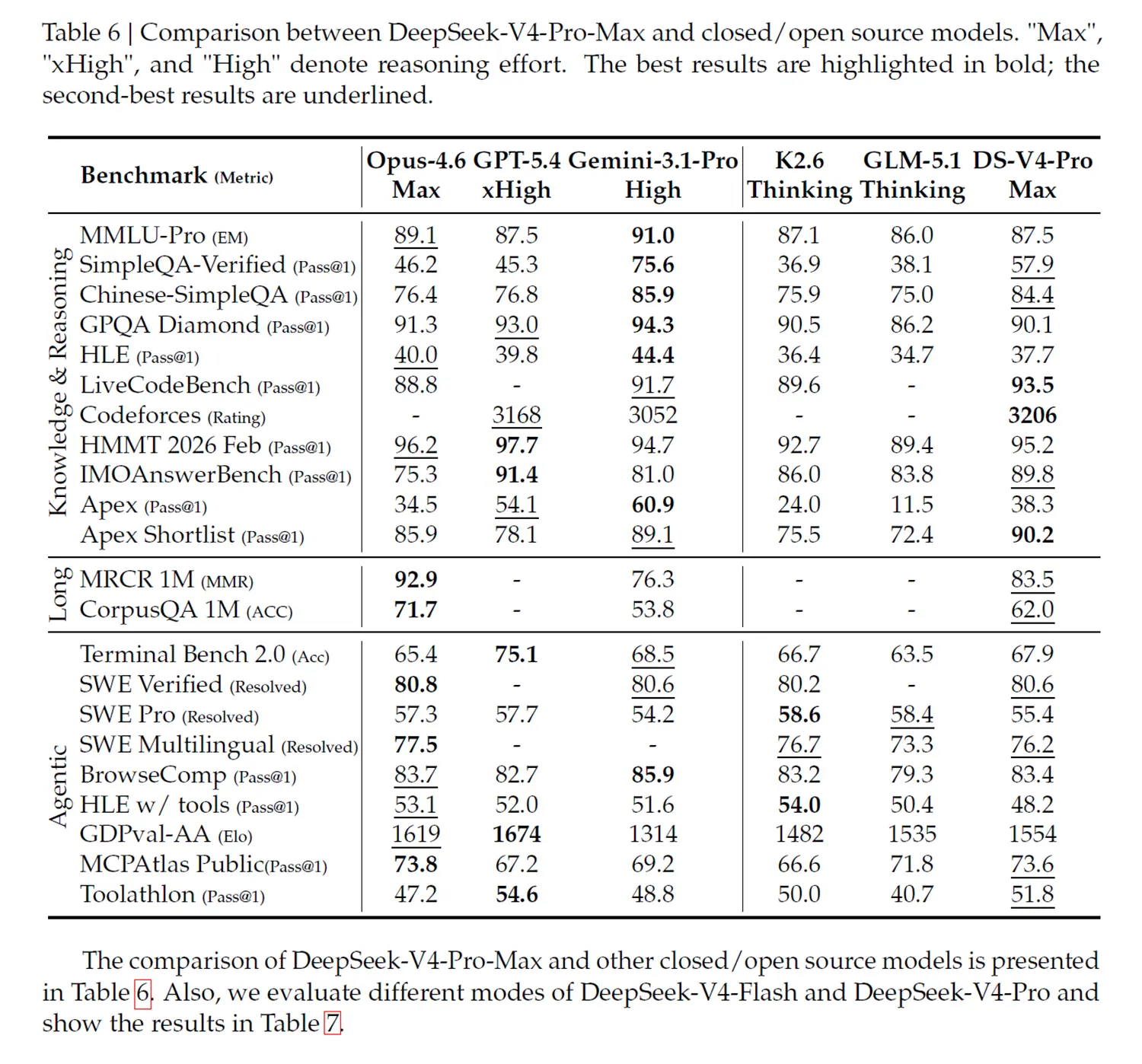
Gegen Open-Weight-Konkurrenz sieht DeepSeek in den eigenen Zahlen stark aus. V4-Pro-Max erreicht bei SimpleQA Verified 57,9 Punkte und liegt damit klar vor Kimi K2.6 Thinking mit 36,9 sowie GLM-5.1 Thinking mit 38,1. Bei Chinese-SimpleQA kommt V4-Pro-Max auf 84,4 Punkte.
Gegen geschlossene Modelle wird das Bild differenzierter. Auf LiveCodeBench erreicht V4-Pro-Max 93,5 Punkte und liegt damit vor Claude Opus 4.6 und Gemini-3.1-Pro. Beim Codeforces-Rating kommt das Modell auf 3206 Punkte und übertrifft GPT-5.4-xHigh knapp.
Bei agentischen Benchmarks wirkt V4-Pro-Max solide, aber nicht dominant. Terminal Bench 2.0 sieht DeepSeek mit 67,9 Punkten vor Kimi K2.6 und GLM-5.1, aber hinter GPT-5.4-xHigh. Bei SWE Verified liegt V4-Pro-Max mit 80,6 praktisch gleichauf mit Gemini-3.1-Pro und Kimi K2.6.
Wissens- und Reasoning-Tests zeigen die Grenze. In GPQA Diamond erreicht V4-Pro-Max 90,1 Punkte, Gemini-3.1-Pro liegt bei 94,3. In Humanity’s Last Exam kommt DeepSeek auf 37,7 Punkte, Gemini auf 44,4 und Claude Opus 4.6 auf 40,0.
Für lange Kontexte liefert DeepSeek dagegen ein starkes Profil. In MRCR 1M erreicht V4-Pro-Max 83,5 Punkte und liegt vor Gemini-3.1-Pro, aber hinter Claude Opus 4.6. In CorpusQA 1M kommt DeepSeek auf 62,0 Punkte, vor Gemini mit 53,8 und hinter Claude mit 71,7.
Quelle: DeepSeek
Unabhängige Benchmarks aus der Arena
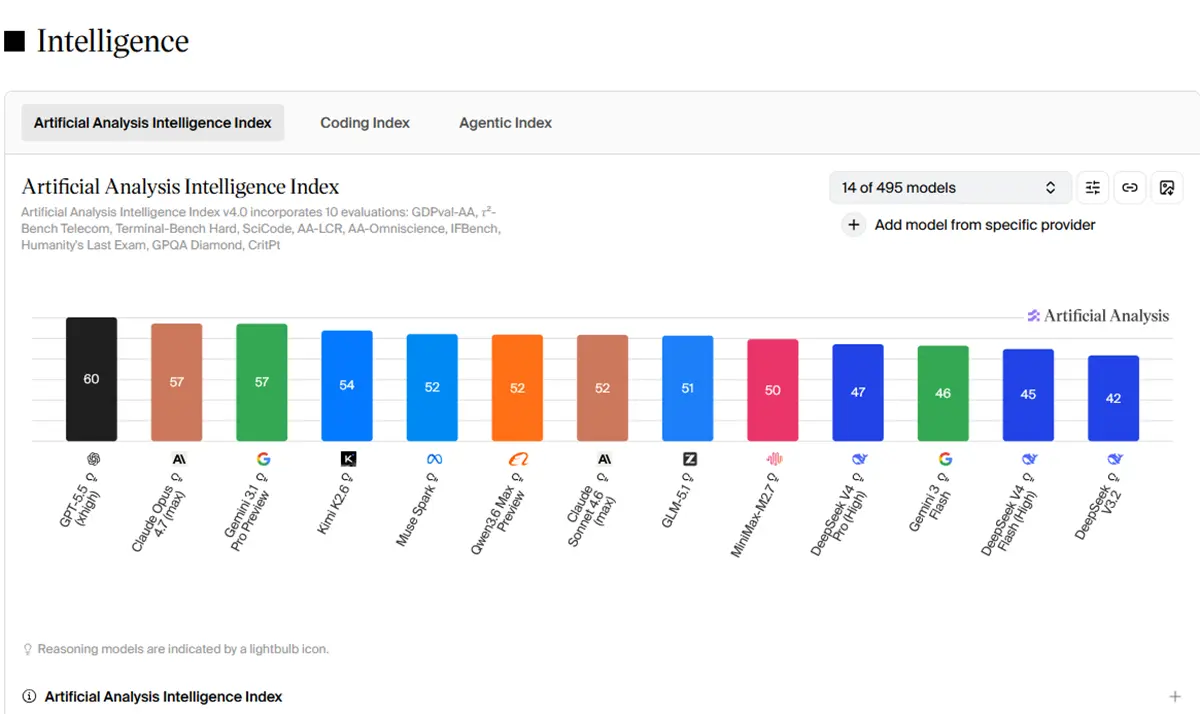
Die unabhängigen Rankings wirken ernüchternder als DeepSeeks eigene Tabellen. Im Artificial Analysis Intelligence Index liegt DeepSeek V4 Pro High bei 47 Punkten. Damit landet das Modell klar hinter der US-Konkurrenz und auch hinter einigen chinesischen Modellen wie Kimi K2.6 mit 54 Punkten.
Auch die LM Arena sortiert V4-Pro nicht an die Spitze. In der Text Arena steht DeepSeek-V4-Pro bei Rang 20 mit 1463 Punkten. Die führenden Plätze gehen dort klar an die US-Konkurrenz.
Etwas besser sieht es in der Code Arena WebDev aus, aber auch dort führt DeepSeek nicht. DeepSeek-V4-Pro-Thinking erreicht Rang 14 insgesamt und Rang 3 unter den offenen Modellen. Vor ihm liegen in dieser offenen Gruppe GLM-5.1 und Kimi K2.6.
Quelle: artificialanalysis
Preis und Verfügbarkeit
Preislich wirkt V4-Pro nicht mehr wie der frühere DeepSeek-Schock. DeepSeek verlangt 1,74 Dollar pro Million Input-Token bei Cache-Miss und 3,48 Dollar pro Million Output-Token. Kimi K2.6 liegt offiziell bei 0,95 Dollar für Input-Token und 4 Dollar für Output-Token.
Damit ist DeepSeek beim Output etwas günstiger, beim Input aber deutlich teurer. Gerade lange neue Kontexte machen diesen Unterschied relevant. Für ähnliche Leistung gegenüber Kimi K2.6 fällt das ernüchternd aus, weil DeepSeek lange als aggressiver Preisführer galt.
Verfügbar sind die Modelle über Hugging Face, ModelScope und DeepSeeks API. Auf GitHub liegen zudem Inferenz- und Kernel-Komponenten, während Anbieter wie OpenRouter V4-Pro bereits in ihre Modellkataloge aufgenommen haben.