Google Deepmind: Alte und neue Chips gemeinsam im KI-Training nutzen
Eine neuartige Architektur erlaubt das Mischen verschiedener TPU-Generationen bei konstant hoher Modellqualität.

Das Training riesiger KI-Modelle erfordert bisher eine perfekte Synchronisation tausender Chips in Rechenzentren. Mit Decoupled DiLoCo von Google Deepmind existiert nun eine asynchrone Architektur, die diesen Prozess auf unabhängige Recheninseln verteilt und Hardware-Ausfälle effektiv abfedert.
Autonome Recheninseln statt starrer Netzwerke
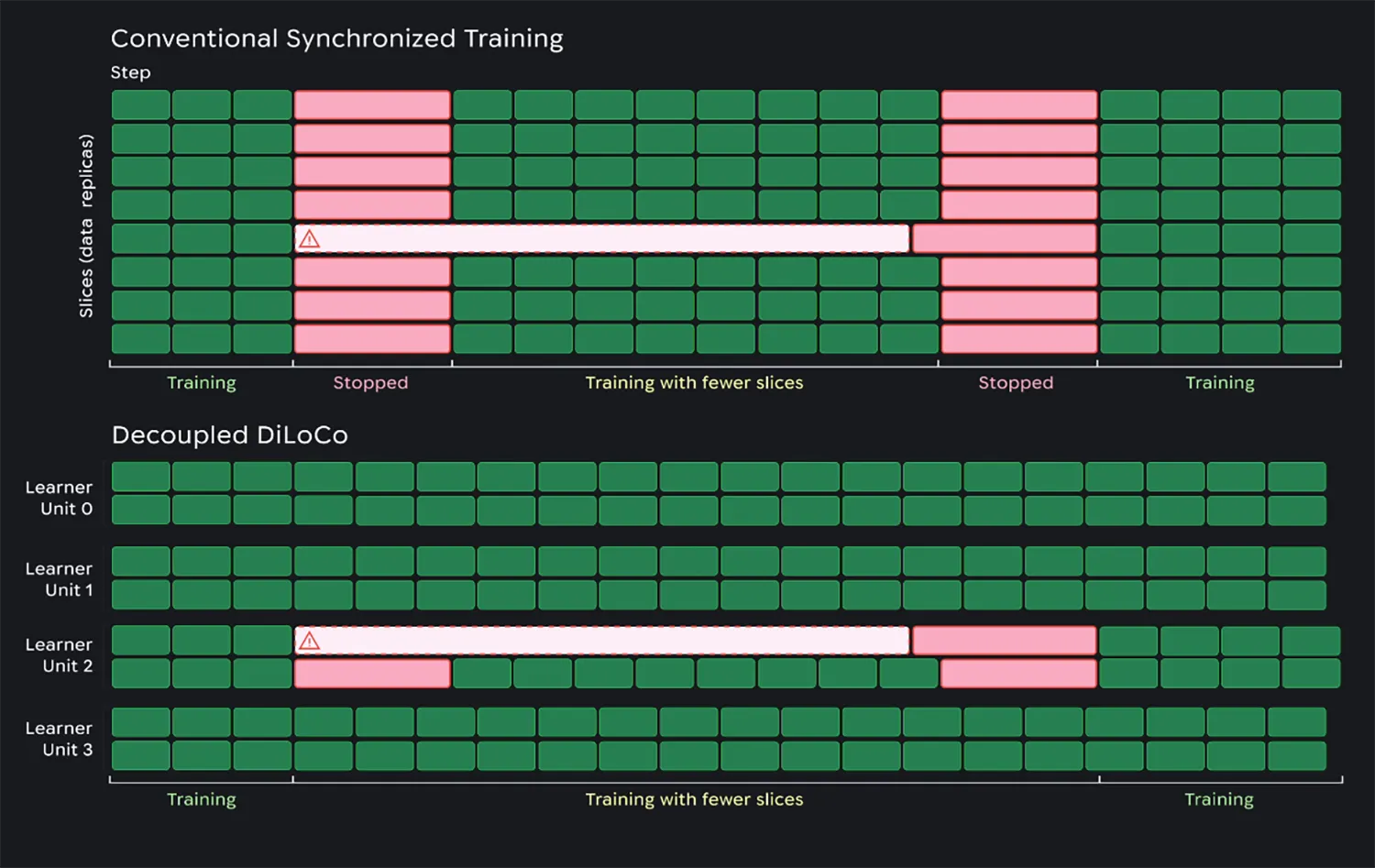
Bislang stoppt ein einzelner defekter Chip oft den gesamten Trainingsablauf eines Systems. Die neue Methode teilt die Rechenlast deshalb in völlig isolierte Gruppen auf. Zwischen diesen Einheiten fließen die Daten asynchron. Fällt ein lokaler Bereich durch einen Defekt aus, lernen die restlichen Cluster einfach ungestört weiter.
Quelle: Google
Sobald die reparierte Hardware wieder online ist, integriert der Algorithmus sie nahtlos in den laufenden Prozess. Spezielle Stresstests, das sogenannte »Chaos Engineering«, belegen die Wirksamkeit dieses Ansatzes. Die nutzbare Trainingszeit klettert bei einer extremen Ausfallrate von 27 Prozent auf starke 88 Prozent.
Geringer Datenhunger und Hardware-Flexibilität
Parallel dazu sinkt der Bedarf an Netzwerkkapazität erheblich. Statt der sonst benötigten 198 Gigabit pro Sekunde genügen für den Datenaustausch zwischen weit entfernten Rechenzentren nun lediglich 0,84 Gigabit pro Sekunde. Fachleute trainierten so ein Modell mit 12 Milliarden Parametern erfolgreich über vier US-Regionen hinweg. Das asynchrone Vorgehen erledigte diese Aufgabe 20-mal schneller als herkömmliche Methoden, da blockierende Wartezeiten beim Datenabgleich vollständig entfallen.
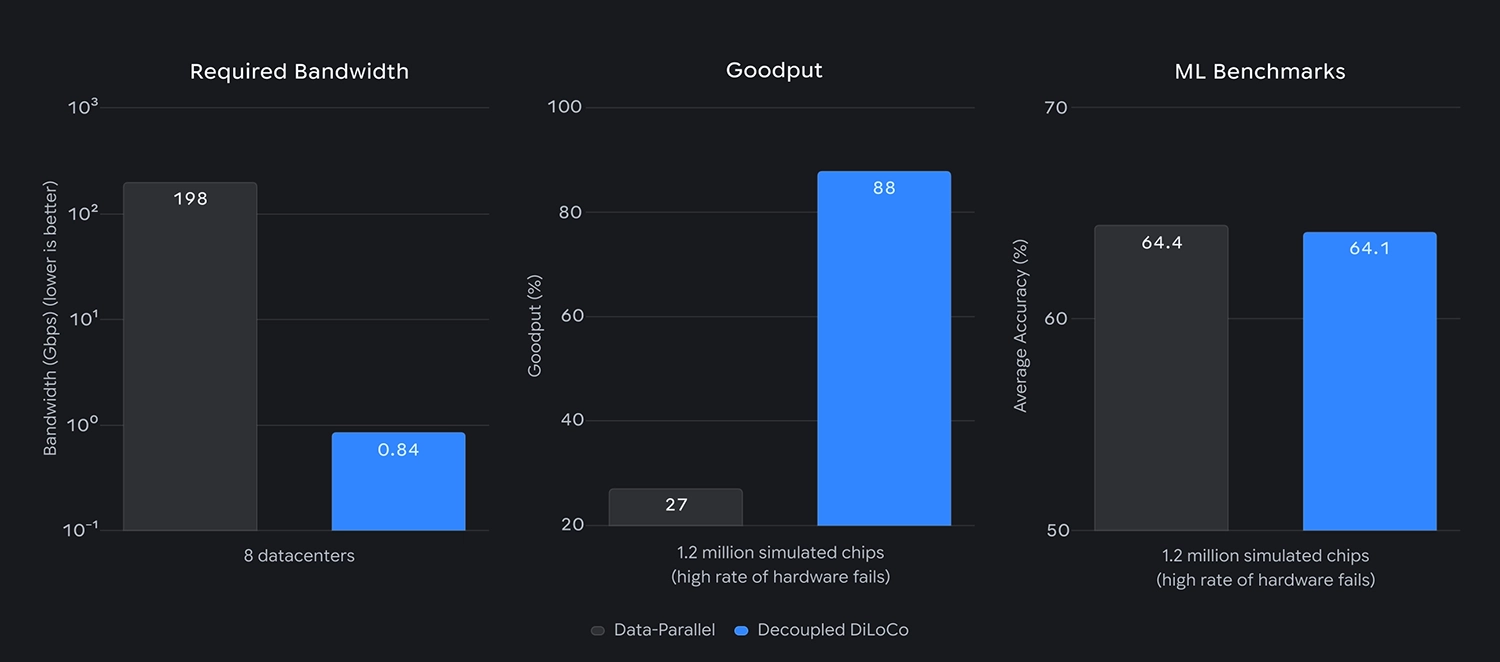
Zudem löst die Architektur ein handfestes logistisches Problem. Betreiber können ab sofort unterschiedliche Chip-Generationen, wie beispielsweise die TPU v6e und TPU v5p, für denselben Trainingslauf bündeln. Ältere Hardware behält dadurch ihren Wert und steuert effizient nützliche Rechenleistung bei. Aktuelle Benchmarks zeigen abschließend, dass die durchschnittliche Genauigkeit der Modelle trotz dieser stark gemischten Infrastruktur stabil bei gut 64 Prozent bleibt.