Qwen3-Coder-Next für effizientes Coding und KI-Agenten
Das neue Alibaba-Modell bietet hohe Effizienz für lokale Entwicklungsumgebungen und überzeugt in aktuellen Coding-Benchmarks.

Alibaba veröffentlicht mit Qwen3-Coder-Next ein neues Open-Weight-Sprachmodell, das sich auf komplexe Programmieraufgaben spezialisiert. Trotz einer kompakten Architektur von nur 3 Milliarden aktiven Parametern übertrifft es in aktuellen Benchmarks deutlich größere Konkurrenten.
Effizienz durch Mixture-of-Experts
Die technische Basis von Qwen3-Coder-Next bildet eine Mixture-of-Experts-Architektur (MoE). Das Modell verfügt zwar über eine Gesamtzahl von 80 Milliarden Parametern, aktiviert für die Berechnung eines einzelnen Tokens jedoch nur knapp 3 Milliarden davon.
Dieser Ansatz reduziert den Rechenaufwand drastisch. Entwickler können das Modell dadurch auch auf leistungsfähiger Consumer-Hardware lokal betreiben, ohne auf die Intelligenz riesiger Server-Modelle verzichten zu müssen. Die Latenz bei der Code-Generierung sinkt spürbar, was besonders für Echtzeit-Anwendungen in Entwicklungsumgebungen wichtig ist.
Anzeige
Benchmark-Ergebnisse schlagen DeepSeek und GLM
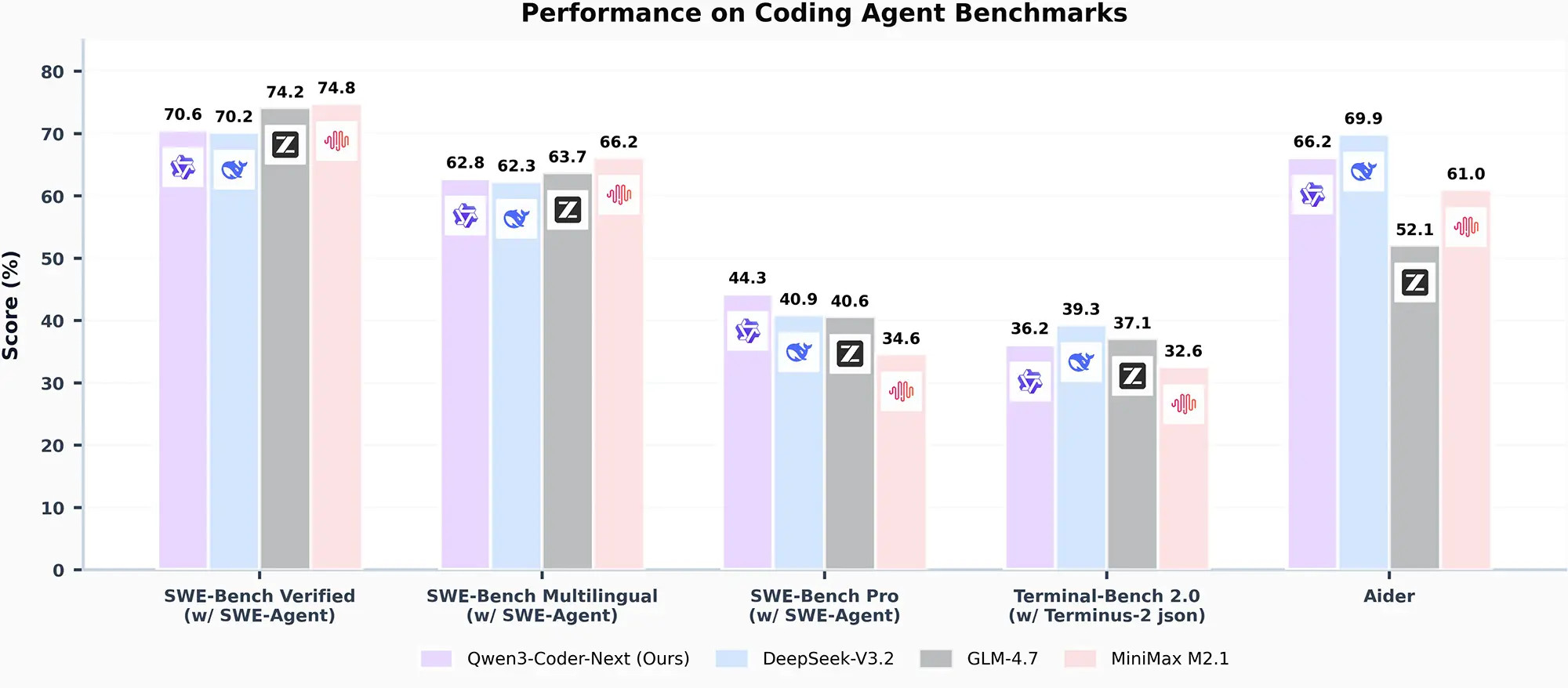
In standardisierten Tests zeigt das Modell beeindruckende Ergebnisse. Im "SWE-Bench Verified", der die Lösung echter GitHub-Issues simuliert, erreicht Qwen3-Coder-Next einen Score von 70,6 Prozent. Damit schlägt es knapp das bisher führende DeepSeek-V3.2 (70,2 Prozent) und das GLM-4.7.
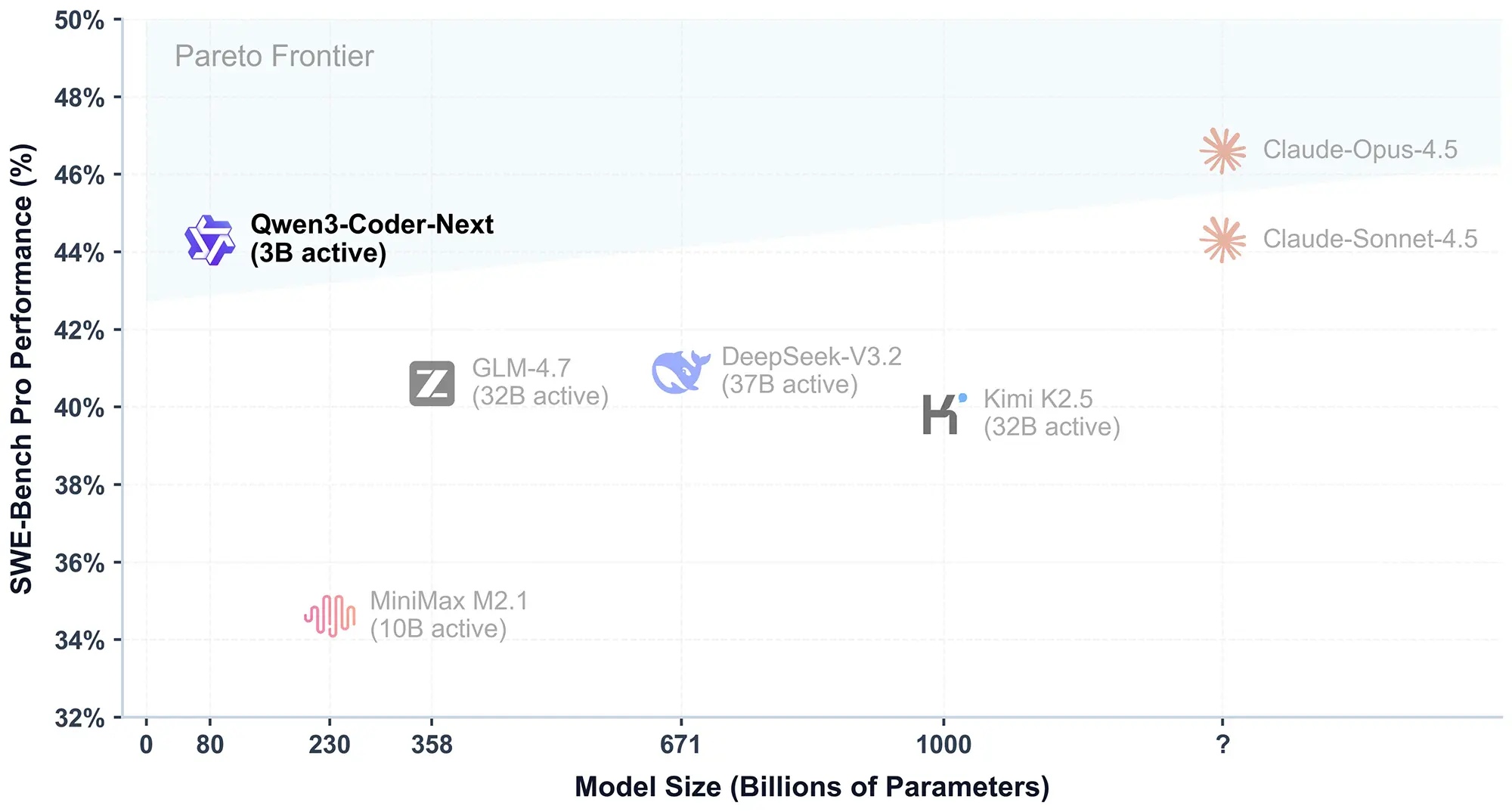
Noch deutlicher ist der Vorsprung im anspruchsvollen "SWE-Bench Pro". Hier erzielt das Alibaba-Modell 44,3 Prozent und liegt damit deutlich vor der Konkurrenz, die teilweise mehr als die zehnfache Menge an aktiven Parametern benötigt. Das Modell positioniert sich in der Effizienz-Leistungs-Kurve (Pareto-Frontier) damit extrem günstig und kommt sogar an die Leistung geschlossener Systeme wie Claude Opus 4.5 heran.
Quelle: Alibaba
Fokus auf Agenten und Terminals
Alibaba optimierte Qwen3-Coder-Next nicht nur für das Schreiben von Code, sondern für das agieren als "Agent". Das Modell soll eigenständig Fehler suchen, Tests schreiben und Kommandozeilen-Befehle ausführen.
Die Ergebnisse im "Terminal-Bench 2.0" bestätigen diese Ausrichtung, auch wenn das Modell hier mit 36,2 Prozent noch hinter DeepSeek-V3.2 liegt. Dennoch zeigt die Architektur, dass spezialisierte Coding-Modelle mit geringem Speicherbedarf zunehmend komplexe Workflows übernehmen können. Das Modell steht ab sofort auf Hugging Face zum Download bereit.