
So schlecht ist KI im echten Laboralltag
OpenAI deckt mit dem neuen Benchmark LifeSciBench deutliche Schwächen bei Sprachmodellen auf.

OpenAI misst KI-Modelle künftig an realen Aufgaben aus der Biowissenschaft. Der neue Test »LifeSciBench« zeigt, dass GPT-Rosalind Konkurrenten wie Gemini 3.1 Pro hinter sich lässt. Bei der Analyse komplexer Forschungsdaten stoßen die Modelle allerdings auf Schwierigkeiten.
Forschungspraxis statt Multiple Choice
Bisherige Tests für Sprachmodelle bestanden in der Wissenschaft oft aus strukturierten Fragen mit eindeutigen Antworten. OpenAI hat LifeSciBench entwickelt, um den tatsächlichen Forschungsalltag abzubilden.
Dafür formulierten 173 promovierte Biowissenschaftler insgesamt 750 praxisnahe Aufgaben. Die KI muss unvollständige Beweise interpretieren, Experimente entwerfen oder Fehler in Testreihen finden. Mehr als die Hälfte der Aufgaben erfordert die Arbeit mit zusätzlichen Dateien wie PDFs, Diagrammen oder chemischen Strukturen.
Quelle: OpenAI
Neues Modell schlägt die Konkurrenz
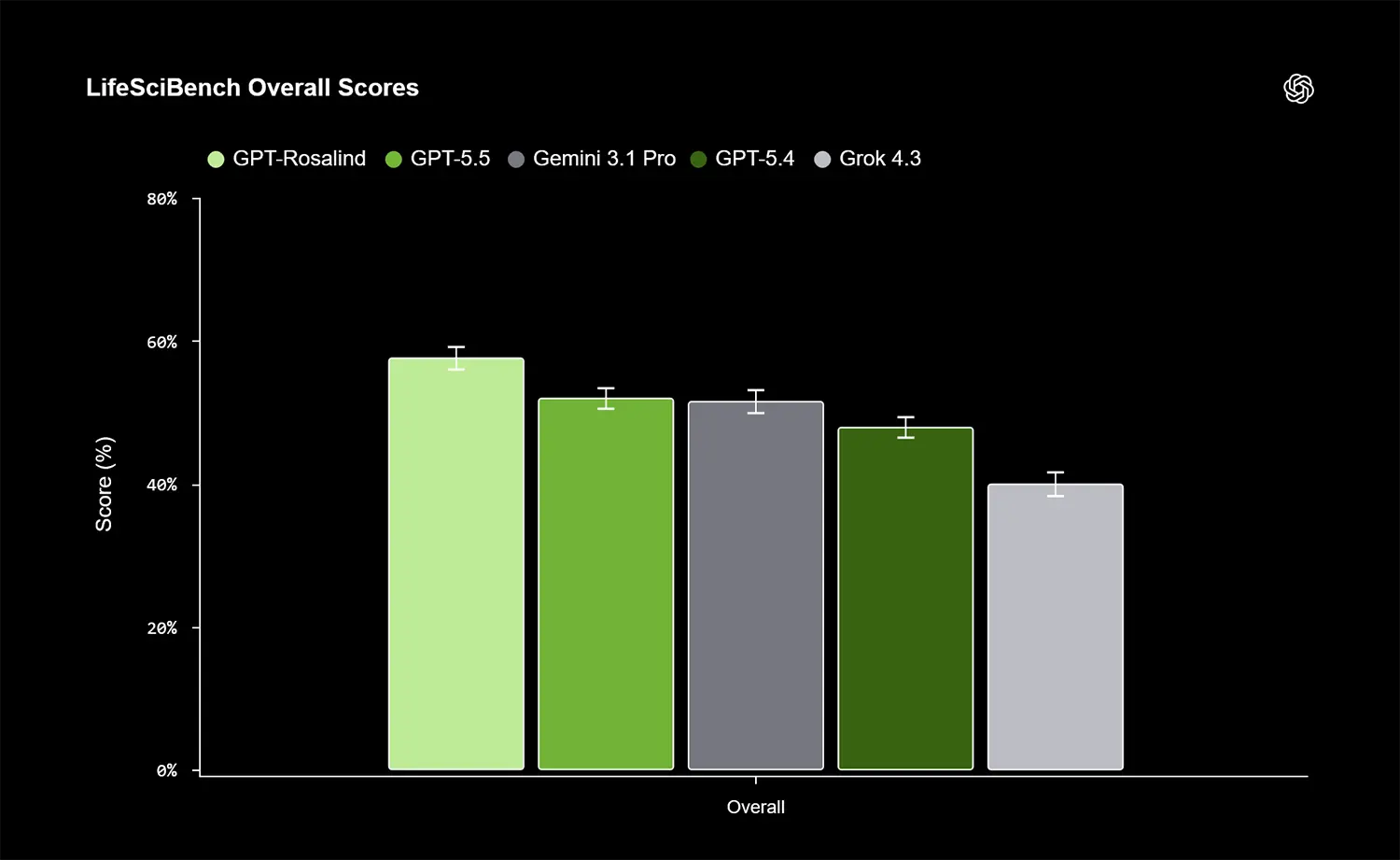
In der Gesamtwertung erreicht GPT-Rosalind knapp 58 Prozent der möglichen Punkte. Es übertrifft damit sein Vorgängermodell GPT-5.5 sowie Googles Gemini 3.1 Pro, das bei etwa 51 Prozent liegt. Schlusslicht im aktuellen Vergleich ist Grok 4.3 mit rund 40 Prozent.
GPT-Rosalind schneidet besonders gut bei der wissenschaftlichen Kommunikation ab. Auch bei der Übertragung von präklinischen Ergebnissen in die klinische Anwendung verzeichnet es deutliche Fortschritte. Das Modell organisiert Beweise effizient und liefert Erklärungen, die für Fachleute nützlich sind.
Quelle: OpenAI
Probleme abseits reiner Textverarbeitung
Sobald die Aufgaben exakte Berechnungen oder spezifische Ausgaben erfordern, sinkt die Erfolgsquote drastisch. Bei der Erstellung genauer Sequenzen oder Strukturen erreicht GPT-Rosalind lediglich 24 Prozent.
Die Verarbeitung von angehängten Dokumenten fällt den Modellen ebenfalls schwer. Besteht eine Aufgabe nur aus Text, löst GPT-Rosalind diese in 45 Prozent der Fälle. Kommen externe Quellen oder Dateien hinzu, fällt der Wert auf 28 Prozent.
Die Modelle extrahieren Informationen aus Diagrammen oder großen Sequenzdateien oft fehlerhaft. Ein starkes Abschneiden im Benchmark bedeutet daher noch nicht, dass eine KI im echten Labor verlässliche Ergebnisse liefert.





