
Drei neue Audio-Modelle von OpenAI
Drei frische KI-Modelle versprechen natürlichere Sprachschnittstellen und rasantere Übersetzungen in Echtzeit.

OpenAI veröffentlicht drei neue Audio-Modelle für die Entwickler-API, um reaktionsschnelle Sprachschnittstellen zu verbessern. Im Zentrum steht dabei GPT-Realtime-2, ein KI-Modell mit Reasoning-Fähigkeiten auf GPT-5-Niveau für deutlich flüssigere und dynamischere Unterhaltungen.
Logisches Denken und messbare Leistung
Entwickler können bei GPT-Realtime-2 den Grad der Rechenleistung für das logische Denken in fünf Stufen von minimal bis sehr hoch justieren. Standardmäßig arbeitet das KI-Modell auf einer niedrigen Stufe, um Latenzen bei einfachen Anfragen zu minimieren. Steigen die Anforderungen an den Kontext, löst die KI komplexe Aufgaben durch weitaus intensiveres Reasoning.
Begleitet wird diese Flexibilität von einer massiven Vergrößerung des Speichergedächtnisses. Das Kontextfenster wächst von 32.000 auf 128.000 Token, wodurch die fehlerfreie Verarbeitung deutlich längerer Sitzungen ermöglicht wird. Gleichzeitig führt die KI nun mehrere Funktionsaufrufe parallel aus und kommentiert diese Aktionen hörbar, um Nutzern eine direkte akustische Rückmeldung zu geben.
Aufschluss über die tatsächliche Leistung in der Praxis geben die offiziellen Benchmarks. Beim Big Bench Audio Intelligence Test erreicht die hohe Reasoning-Stufe eine Genauigkeit von 96,6 Prozent, was einen ordentlichen Sprung gegenüber den 81,4 Prozent des Vorgängers GPT-Realtime-1.5 darstellt. Ähnlich positiv fallen die Ergebnisse beim Audio MultiChallenge aus, wo die höchste Rechenstufe eine durchschnittliche Erfolgsquote von 48,5 Prozent beim Befolgen von Instruktionen erzielt.
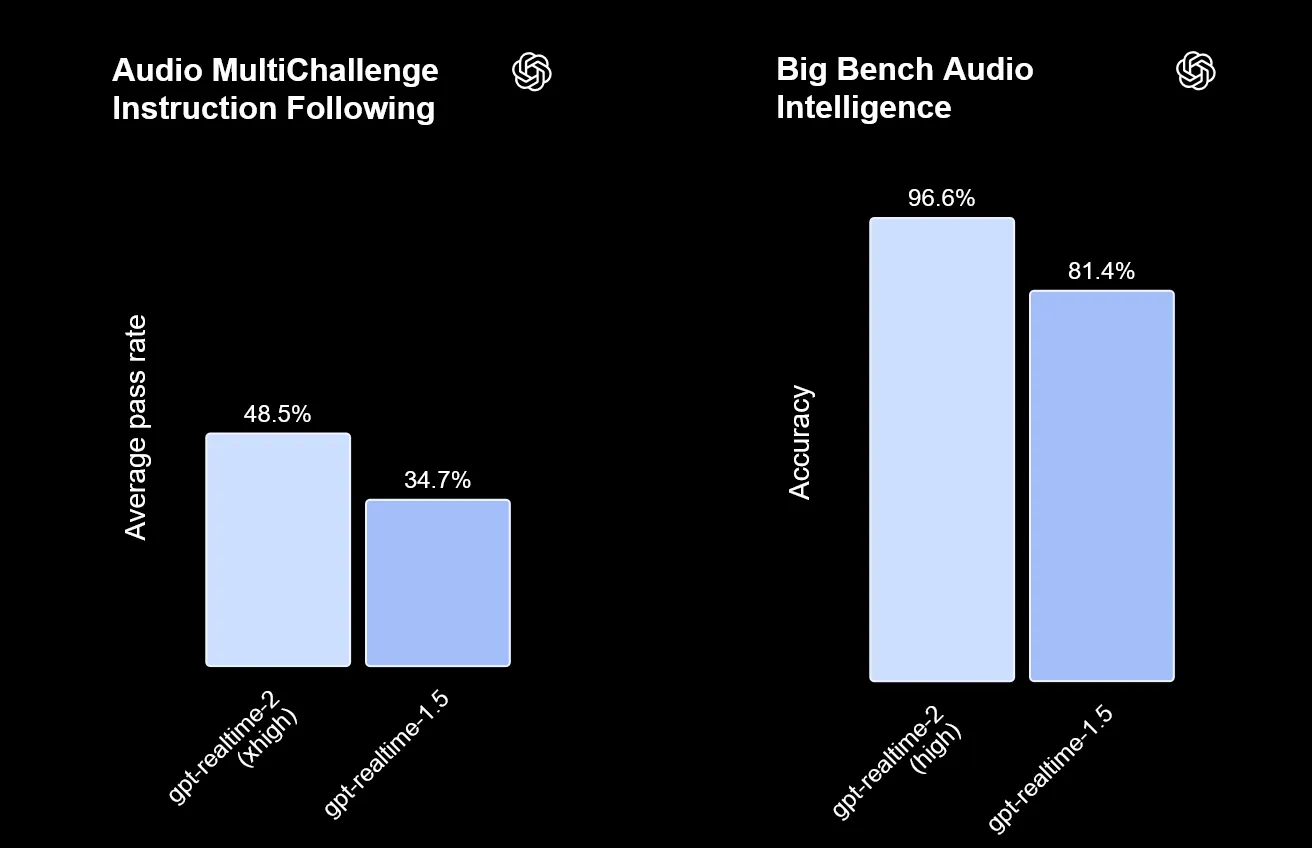
Quelle: OpenAI
Echtzeit-Übersetzung und schnelle Transkription
Flankiert wird das Hauptmodell von zwei spezialisierten Ergänzungen für den internationalen Markt. GPT-Realtime-Translate verarbeitet gesprochene Sprache aus über 70 Eingabesprachen und übersetzt diese verzögerungsfrei in 13 Zielsprachen. Dabei behält das KI-Modell das Sprechtempo der jeweiligen Person konsequent bei und erfasst selbst fachspezifisches Vokabular problemlos.
Für die reine Verschriftlichung von Sprache dient hingegen das neue GPT-Realtime-Whisper. Dieses Streaming-Modell wandelt Audioinhalte mit extrem geringer Latenz direkt in Text um. Dadurch lassen sich Live-Untertitel für Meetings oder schnelle Zusammenfassungen in Geschäftsprozessen realisieren, während die eigentliche Konversation noch andauert.
Anzeige
Transparente Kostenstruktur für Entwickler
Bei der Abrechnung über die API unterscheidet der Anbieter zwischen den verschiedenen Diensten. Für GPT-Realtime-2 fallen 32 US-Dollar pro einer Million Audio-Input-Token an, während für generierte Ausgaben 64 US-Dollar berechnet werden. Günstiger fällt der Preis für bereits zwischengespeicherte Input-Token aus, welcher bei lediglich 40 US-Cent liegt.
Die beiden spezialisierten Modelle für Sprache werden hingegen klassisch pro Minute abgerechnet. GPT-Realtime-Translate kostet 0,034 US-Dollar pro Minute, die reine Transkription mit Whisper schlägt mit 0,017 US-Dollar zu Buche. Damit erhalten Entwickler die nötigen technischen Bausteine zur Erstellung moderner Audio-Anwendungen.