
Microsoft Paza löst Datenproblem bei KI-Modellen für Afrika
Spezialisierte Versionen von Whisper und Phi-4 senken die Word Error Rate in Tests um über fünfzig Prozent.

Sprachmodelle funktionieren hervorragend auf Englisch oder Deutsch, scheitern aber oft an Sprachen mit geringer Datenbasis. Microsoft Research reagiert darauf mit dem Projekt Paza und veröffentlicht ab sofort verbesserte Benchmarks sowie spezialisierte Modelle für 29 afrikanische Sprachen auf Hugging Face.
Fokus auf vernachlässigte Sprachen
Moderne KI-Systeme benötigen riesige Mengen an Trainingsdaten. Für sogenannte "Low-Resource Languages", zu denen viele afrikanische Dialekte gehören, existieren diese Daten kaum in ausreichender Qualität. Das führt dazu, dass globale KI-Lösungen in diesen Regionen oft unbrauchbar sind.
Microsoft Research Africa adressiert dieses Ungleichgewicht nun direkt. Mit Paza stellt das Team keine theoretische Arbeit vor, sondern liefert nutzbare Werkzeuge für Entwickler. Der Release umfasst sowohl einen neuen Benchmark-Datensatz als auch speziell feinabgestimmte Versionen bekannter Modelle wie Whisper und Phi-4.
Anzeige
PazaBench setzt auf Qualität vor Quantität
Herzstück der Veröffentlichung ist PazaBench. Dieser Evaluierungsdatensatz deckt 39 Sprachen ab, darunter 29 afrikanische. Anders als bisherige Datensätze beschränkt sich PazaBench nicht auf generische Sätze. Die Daten stammen aus fünf praxisrelevanten Domänen: Landwirtschaft, Finanzen, Gesundheit, Nachrichten und Religion.
Die Grundlage bildete der bekannte FLEURS-102-Datensatz von Google. Microsoft hat diesen jedoch nicht einfach übernommen, sondern durch Muttersprachler massiv überarbeiten lassen.
Viele Transkriptionsfehler und Ungenauigkeiten des Originals wurden korrigiert. Das Ergebnis ist ein verlässlicherer Maßstab, um die Leistung von Spracherkennungsmodellen (ASR) in diesen spezifischen Sprachen wirklich beurteilen zu können.
Quelle: Microsoft
Massive Reduktion der Fehlerraten
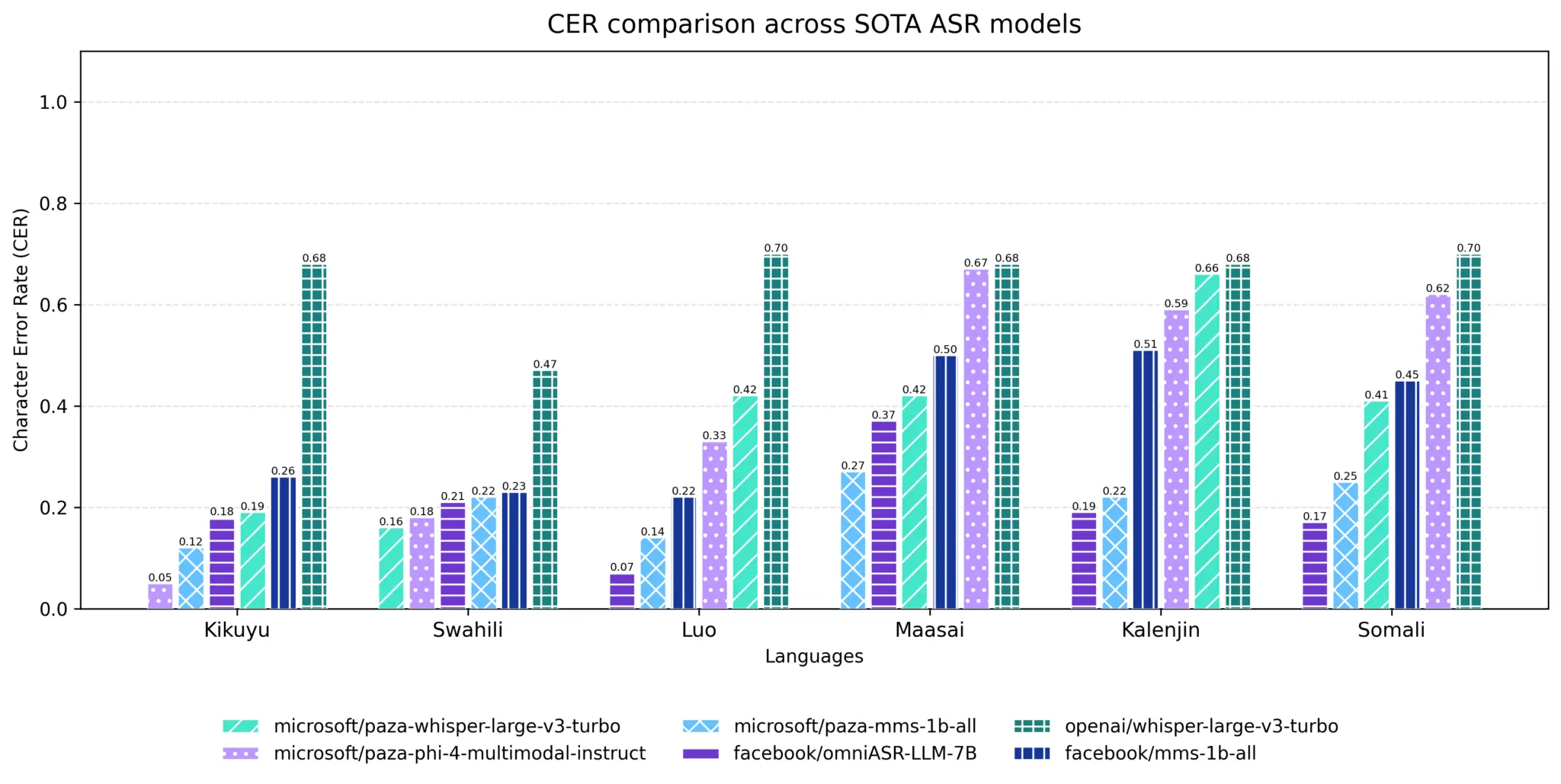
Neben den Daten liefert Microsoft auch die passenden Modelle. Besonders hervorzuheben ist paza-whisper-large-v3-turbo. Dieses Modell wurde spezifisch auf den neuen Daten trainiert und zeigt deutliche Verbesserungen gegenüber der Basisversion.
Die Ergebnisse auf dem PazaBench sind messbar. Das Modell erreicht eine Word Error Rate (WER) von 19,3 Prozent. Im Vergleich zum unveränderten Whisper-Modell entspricht dies einer Reduktion der Fehlerquote um rund 52 Prozent.
Zusätzlich veröffentlichte das Team paza-Phi-4-multimodal-instruct. Dieses Modell erweitert die Fähigkeiten über reine Transkription hinaus und ermöglicht multimodale Interaktionen in den unterstützten Sprachen.
Ursprung in der Landwirtschaft
Das Projekt entstand nicht im luftleeren Raum, sondern als Teil von "Project Gecko". Diese Initiative zielt darauf ab, Kleinbauern durch KI-gestützte Beratung zu unterstützen. Apps wie "Farmer.Chat" benötigen zwingend eine präzise Spracherkennung, da viele Nutzer ihre Anfragen mündlich in lokalen Dialekten stellen.
Die neuen Modelle sind ab sofort als Open Source auf Hugging Face verfügbar. Sie bieten Entwicklern die Möglichkeit, Anwendungen zu bauen, die auch außerhalb der westlichen Sprachräume zuverlässig funktionieren.