
BabyVision Benchmark: Warum die beste KI an Kleinkind-Rätseln zerbricht
Milliarden-Modelle scheitern an simplen Bauklötzen – was der neue Test über die echten Grenzen der künstlichen Intelligenz verrät.

Modelle wie GPT-5 und Gemini 3 wirken oft allwissend, doch ein neuer Benchmark offenbart jetzt eine peinliche Lücke in ihrer "Intelligenz". Bei visuellen Aufgaben, die Dreijährige spielend lösen, brechen die Leistungen der teuersten KI-Systeme dramatisch ein.
Realitätscheck durch "BabyVision"
Wir vertrauen künstlicher Intelligenz mittlerweile komplexe Analysen und Programmieraufgaben an. Doch wie sieht es mit dem bloßen "Verstehen" der physischen Welt aus? Eine neue Studie unter dem Titel "BabyVision", veröffentlicht von Forschern um Liang Chen, zeigt ein ernüchterndes Bild. Die Wissenschaftler konfrontierten aktuelle Top-Modelle mit visuellen Aufgaben, die eigentlich für die Entwicklung von Kleinkindern im Alter von drei bis fünf Jahren gedacht sind.
Dabei ging es nicht um komplexe Interpretation von Kunst, sondern um basale Logik: Das Verfolgen einer Linie durch ein einfaches Labyrinth, das Zählen von gestapelten Bauklötzen oder das Erkennen von "Objektpermanenz" – also dem Verständnis, dass Dinge noch da sind, auch wenn sie kurz verdeckt werden.
Quelle: https://www.alphaxiv.org/overview/2601.06521
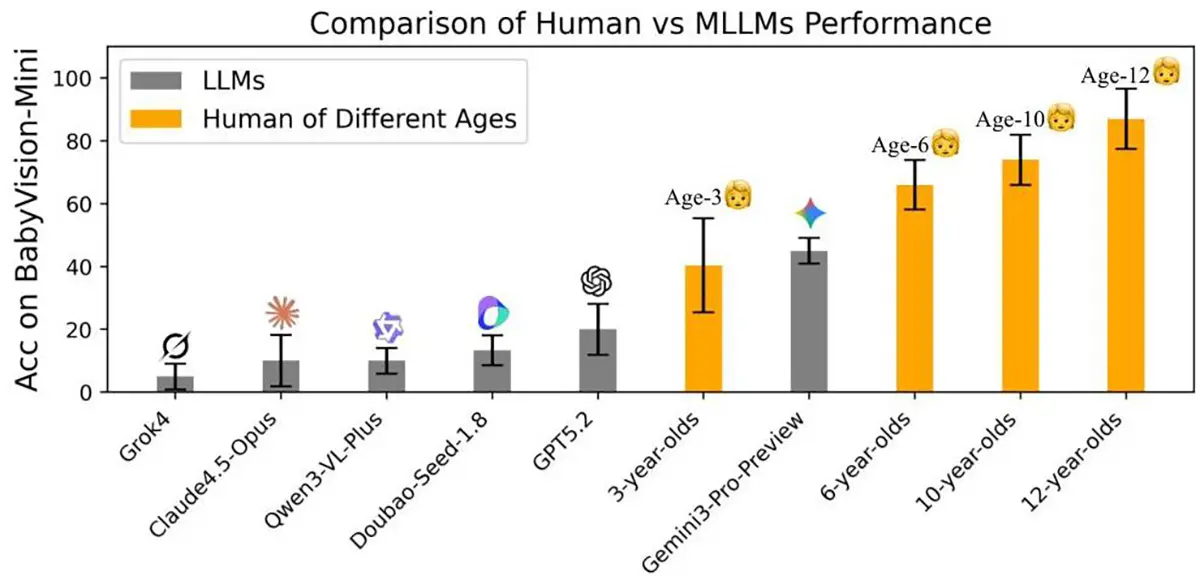
Die Zahlen der Schande
Die Ergebnisse sind für die Tech-Branche ein Weckruf. Während erwachsene Menschen bei diesen Tests eine Trefferquote von durchschnittlich 94,1 % erreichen, scheitern die KI-Modelle grandios. Selbst das leistungsfähigste getestete Modell kam nur auf knapp 49,7 %. Andere prominente Modelle wie GPT-5.2 oder Open-Source-Alternativen lagen teilweise sogar unter 35 %.
Das Kernproblem identifizierten die Forscher als "Sprach-Krücke". Heutige KIs "sehen" nicht wirklich logisch. Sie versuchen, das Bild in Text zu übersetzen und dann diesen Text zu analysieren. Sobald eine Aufgabe visuelles räumliches Denken erfordert, das sich schwer in Worte fassen lässt (z.B. komplexe räumliche Rotationen), bricht die Leistung zusammen. Die KI "rät" dann effektiv nur noch.
Anzeige
Warum das für uns gefährlich ist
Man könnte nun lachen und sagen: "Na und? Dann kann mein Chatbot eben keine Bauklötze zählen." Doch das Defizit ist gravierend für die geplante Integration von KI in die physische Welt. Ein Roboter in einer Fabrik oder ein autonomes Fahrzeug muss visuelle Situationen physikalisch korrekt einschätzen, ohne alles erst intern zu "vertexten".
Wenn eine KI nicht zuverlässig verstehen kann, ob ein Objekt hinter oder vor einem anderen steht, sobald die Perspektive etwas knifflig wird, ist sie für sicherheitskritische Aufgaben in der realen Welt (noch) ungeeignet. Der "BabyVision"-Benchmark zeigt, dass wir zwar exzellente Text-Generatoren gebaut haben, aber noch weit von einer Maschine entfernt sind, die die Welt so sieht und begreift wie ein menschliches Kind.