
Warum KI-Agenten oft den Faden verlieren und was nun hilft
Wenn der Kontext zu lang wird, sinkt die Leistung von Sprachmodellen enorm. Ein neues System von Microsoft Research löst dieses Problem.

Microsoft Research hat mit PlugMem ein neues Gedächtnismodul für KI-Agenten vorgestellt. Das System wandelt rohe Interaktionsdaten in strukturiertes Wissen um. Dadurch steigt die Leistung der Modelle spürbar, während der Token-Verbrauch drastisch sinkt.
Strukturierte Daten statt Informationsflut
KI-Modelle haben häufig Probleme mit der Verarbeitung von sehr langen Kontexten. Wenn sie auf vergangene Interaktionen zugreifen, verarbeiten sie in herkömmlichen Systemen meist die kompletten, unstrukturierten Rohdaten. Diese Methode der reinen Datenabfrage überflutet die KI-Agenten schnell mit irrelevanten Textpassagen. Das kostet nicht nur wertvolle Rechenleistung. Es führt oft auch zu ungenauen oder fehlerhaften Ergebnissen, da das Modell die wichtigen Kerninformationen schlichtweg übersieht.
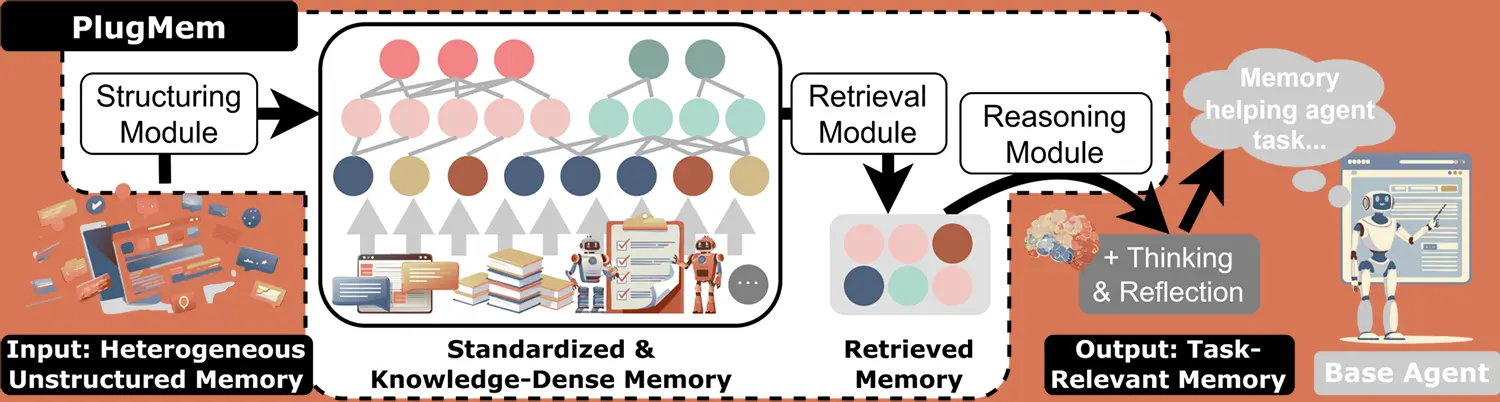
PlugMem löst dieses Problem durch eine gänzlich neue Form der Datenorganisation. Das Modul speichert die gesammelten Informationen nicht einfach stur chronologisch ab. Es wandelt die rohen Interaktionen aktiv in einen strukturierten Wissensgraphen um. Dabei extrahiert das System eigenständig grundlegende Konzepte aus den Texten und nutzt diese als eine Art intelligentes Inhaltsverzeichnis. Die eigentlichen Fakten und detaillierten Aussagen legt PlugMem separat als verknüpfte Nutzlast ab.
Quelle: Meta
Benötigt ein KI-Agent nun eine bestimmte Information, durchsucht er zunächst nur die schlanken, übergeordneten Konzepte. Erst bei einem relevanten Treffer ruft er die exakten Fakten ab. Dadurch entsteht ein fundiertes, wiederverwendbares Wissen, das der Agent jederzeit präzise ansteuern kann.
Anzeige
Hoher Nutzen bei geringen Token-Kosten
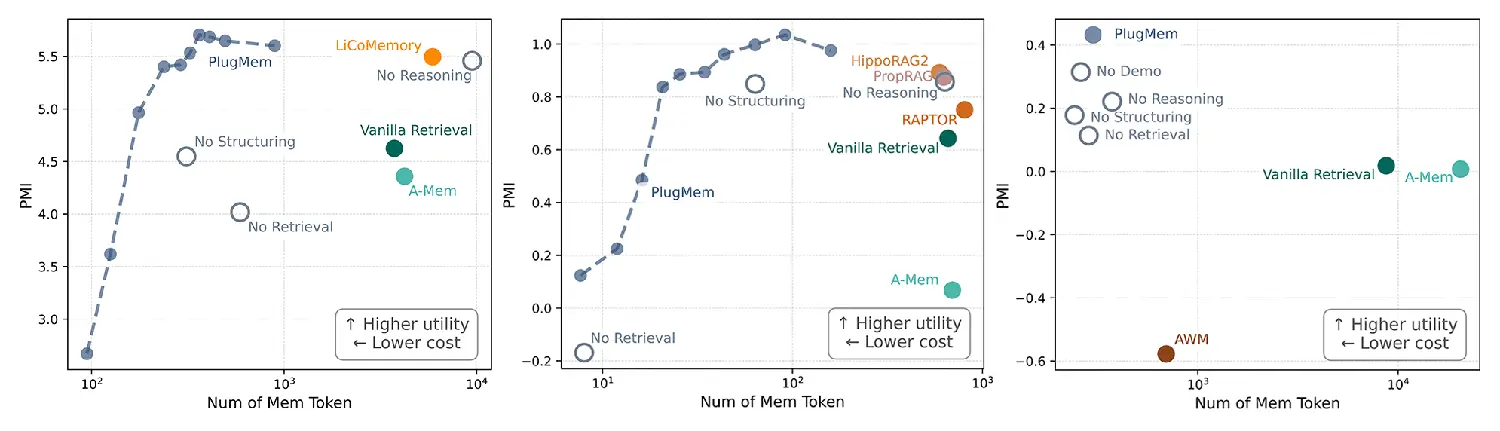
Dieser strukturierte Ansatz führt zu deutlich messbaren Verbesserungen bei der täglichen Nutzung. Eine aktuelle Auswertung der Forscher zeigt den direkten Vergleich mit etablierten Gedächtnis-Methoden wie RAPTOR, Vanilla Retrieval oder HippoRAG2. PlugMem liefert den Agenten sehr exakt die Informationen, die sie für komplexe Entscheidungsfindungen benötigen. In den durchgeführten Benchmarks erreicht das neue Modul den höchsten inhaltlichen Nutzen für das Gesamtsystem.
Quelle: Meta
Gleichzeitig benötigt das Modul für diesen effizienten Abruf deutlich weniger Memory-Tokens als die konkurrierenden Ansätze. Da Entwickler bei der Nutzung von Sprachmodellen oft pro verarbeitetem Token bezahlen, senkt dieser geringere Verbrauch die laufenden Betriebskosten erheblich.
Ein weiterer technischer Vorteil liegt in der hohen Flexibilität der Architektur. PlugMem ist strikt aufgabenübergreifend konzipiert und nicht auf ein spezielles Fachgebiet beschränkt. Entwickler können es als fertiges Plugin direkt in verschiedene, bereits bestehende KI-Architekturen integrieren. Sie müssen das Gedächtnismodul somit nicht für jede neue Anwendung mühsam neu trainieren oder anpassen. Das vereinfacht den generellen Aufbau neuer KI-Anwendungen und sorgt für einen verlässlichen, ressourcenschonenden Betrieb im Alltag.