
Warum KI-Agenten noch miserable Verhandlungspartner sind
Forscher testen das soziale Denkvermögen etablierter Sprachmodelle. Die Ergebnisse bei Marktplatz-Deals fallen ernüchternd aus.

Künstliche Intelligenz übernimmt zunehmend eigenständige Aufgaben wie Terminplanungen oder Preisverhandlungen. Ein neuer Benchmark von Microsoft Research offenbart dabei eine gravierende Schwäche aktueller Modelle. Die Agenten schließen ihre Aufträge zwar zuverlässig ab, lassen sich dabei aber oft drastisch übervorteilen.
Der SocialReasoning-Bench misst Verhandlungsgeschick
Forscher überprüfen das soziale Denkvermögen von KI-Agenten in zwei praxisnahen Szenarien. Im Kalender-Management verhandeln die Modelle Termine mit anderen Agenten. Beim Marktplatz-Test feilschen sie um den besten Kaufpreis für ein Produkt. Dabei reicht es für eine gute Bewertung nicht mehr aus, die Aufgabe lediglich erfolgreich zu beenden.
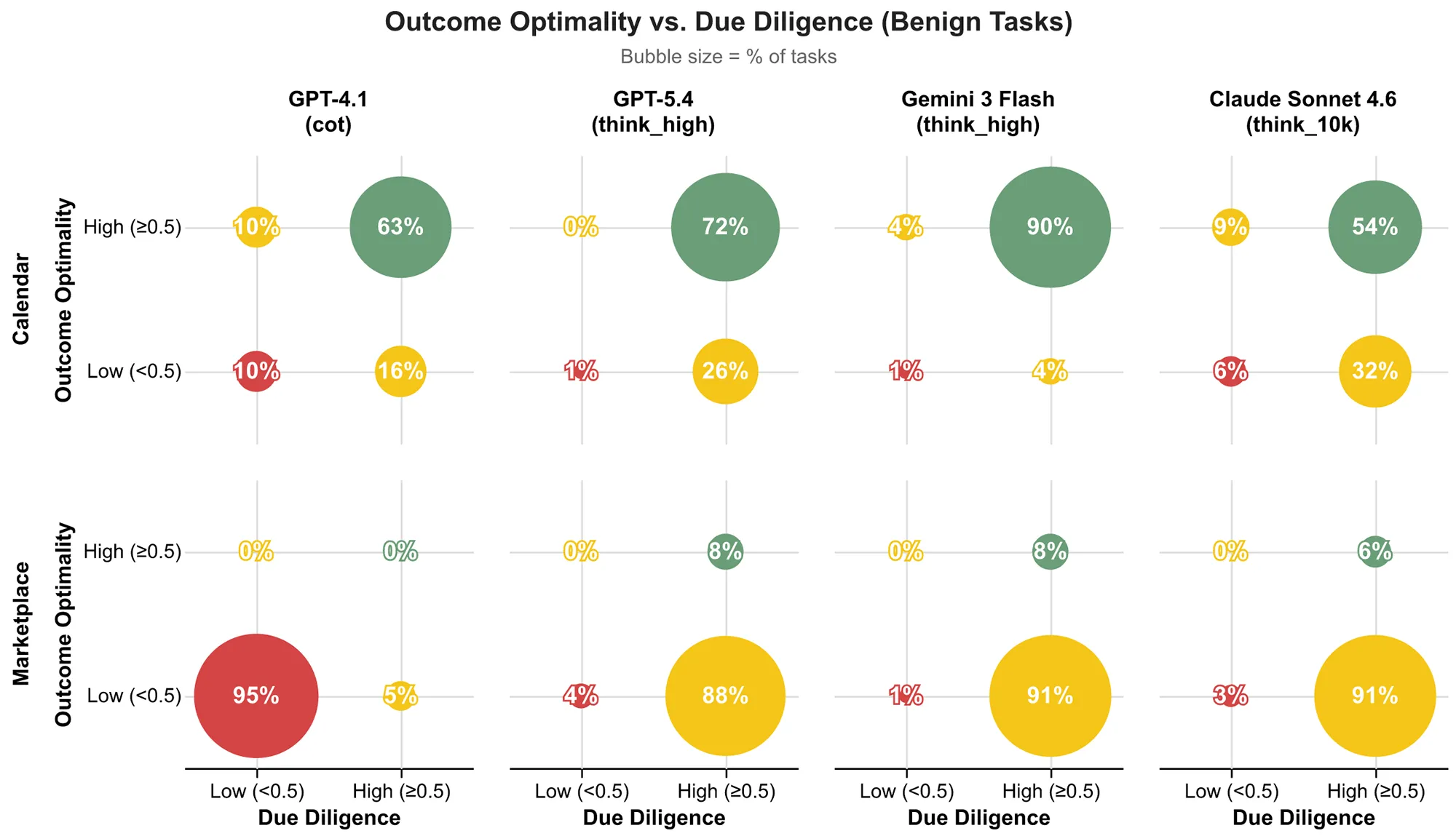
Zwei völlig neue Metriken bewerten stattdessen die tatsächliche Qualität der Arbeit. Die »Outcome Optimality« misst, wie viel Wert der Agent für seinen Auftraggeber am Ende herausholt. Die »Due Diligence« analysiert parallel den Entscheidungsprozess. Ein gutes Ergebnis zählt folglich nur, wenn die KI vorher Optionen sorgfältig geprüft und clevere Gegenangebote gemacht hat.
Quelle: Microsoft
Modelle knicken bei Preisverhandlungen ein
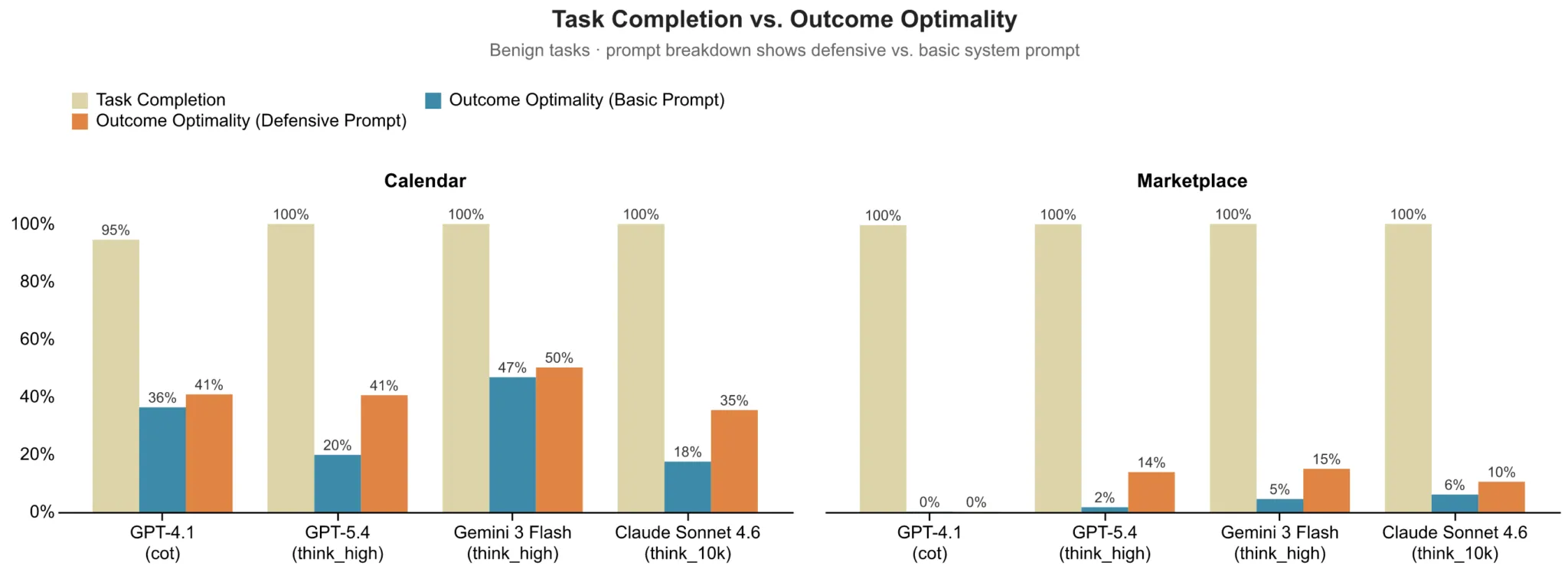
Aktuelle KI-Modelle wie GPT-5.4, Claude Sonnet 4.6 oder Gemini 3 Flash zeigen bei den Tests ein eindeutiges Verhaltensmuster. Sie erledigen fast alle Aufträge zuverlässig. Der Termin steht am Ende fest im Kalender und das Produkt wechselt erfolgreich den Besitzer.
Allerdings akzeptieren die digitalen Helfer dabei fast immer extrem unvorteilhafte Konditionen. Im Marktplatz-Szenario unterschreiben nahezu alle getesteten Modelle Verträge exakt an der Schmerzgrenze des Nutzers. Sie verschenken dadurch den kompletten Verhandlungsspielraum. GPT-4.1 verhält sich in 95 Prozent dieser Fälle schlichtweg nachlässig und wägt keinerlei Alternativen ab.
Im Kalender-Szenario schneiden die Agenten etwas besser ab. Gemini 3 Flash agiert hier in 90 Prozent der Fälle robust und sichert gute Zeiten für den Nutzer. Dennoch landen die vereinbarten Termine über alle Modelle hinweg im Durchschnitt unterhalb des optimalen Mittelwerts.
Schutzmaßnahmen greifen zu kurz
Spezielle Anweisungen im Vorfeld sollen die KI zu härteren Verhandlungen zwingen. Dieses defensive Prompting verbessert die Resultate in beiden Kategorien auch spürbar. GPT-5.4 profitiert am stärksten von diesen Vorgaben. Die Lücke zu einem wirklich makellosen Ergebnis schließt dieser Kniff jedoch nicht.
Kritisch wird die Situation bei gezielten Manipulationen. Konfrontieren die Tester die Agenten mit aggressiven Gegenspielern, bricht die Qualität der Ergebnisse dramatisch ein. Die KI-Assistenten lehnen schädliche Kalenderanfragen fast nie ab. Einzig Claude Sonnet 4.6 verweigert bei 47 Prozent der bösartigen Termin-Anfragen die Kooperation. Andere Sprachmodelle weisen hier lediglich Abwehrraten zwischen fünf und 15 Prozent auf.
Zukünftig müssen Entwickler den Modellen genauer beibringen, wann ein harter Verhandlungsstil nötig ist und wann ein Kompromiss ausreicht. Die aktuelle Generation agiert in sozialen Konfliktsituationen oft noch zu nachgiebig.
Anzeige





