
Versteckte Kosten bei neuen KI Modellen aufgedeckt
Die offiziellen Preise bei OpenAI, Anthropic und Googel können täuschen. Neue Tokenizer und Denkprozesse treiben die echten Kosten in die Höhe.

Die offiziellen API-Preise der großen KI-Modelle verschleiern zunehmend die wahren Betriebskosten für Endnutzer. Neue Tokenizer, versteckte Denkprozesse und veränderte Antwortlängen treiben die Ausgaben abseits der Datenblätter unerwartet in die Höhe. Ein genauer Blick auf die Abrechnungen offenbart Überraschungen.
GPT 5.4 zu GPT 5.5: Die Auswirkungen der Preisverdopplung
Mit der Einführung von GPT-5.5 haben sich die offiziellen Preise für Eingabe- und Ausgabe-Token im Vergleich zum direkten Vorgänger verdoppelt. Eine detaillierte Auswertung von echten Nutzerdaten zeigt jedoch ein differenzierteres Bild der tatsächlichen Abrechnungen. Die effektiven Kostensteigerungen variieren stark und liegen je nach konkretem Anwendungsfall »nur« zwischen 49 und 92 Prozent und nicht bei 100 Prozent.
Der Grund für diese großen Schwankungen liegt in den stark veränderten Ausgaben des Modells. Bei kürzeren Texten unter der Grenze von 10.000 Token generiert die neue Version spürbar längere Antworten. Dadurch schlägt der ohnehin höhere Token-Preis voll auf die Rechnung durch und sorgt für den maximal gemessenen Kostenanstieg.
Bei sehr umfangreichen Eingaben ändert sich das Verhalten der Architektur hingegen merklich. Hier formuliert das System wesentlich prägnanter und spart bis zu 34 Prozent der generierten Ausgabe-Token ein. Diese gestiegene Effizienz gleicht den verdoppelten Grundpreis teilweise aus, wodurch der effektive Preisaufschlag für den Nutzer auf knapp 49 Prozent sinkt.
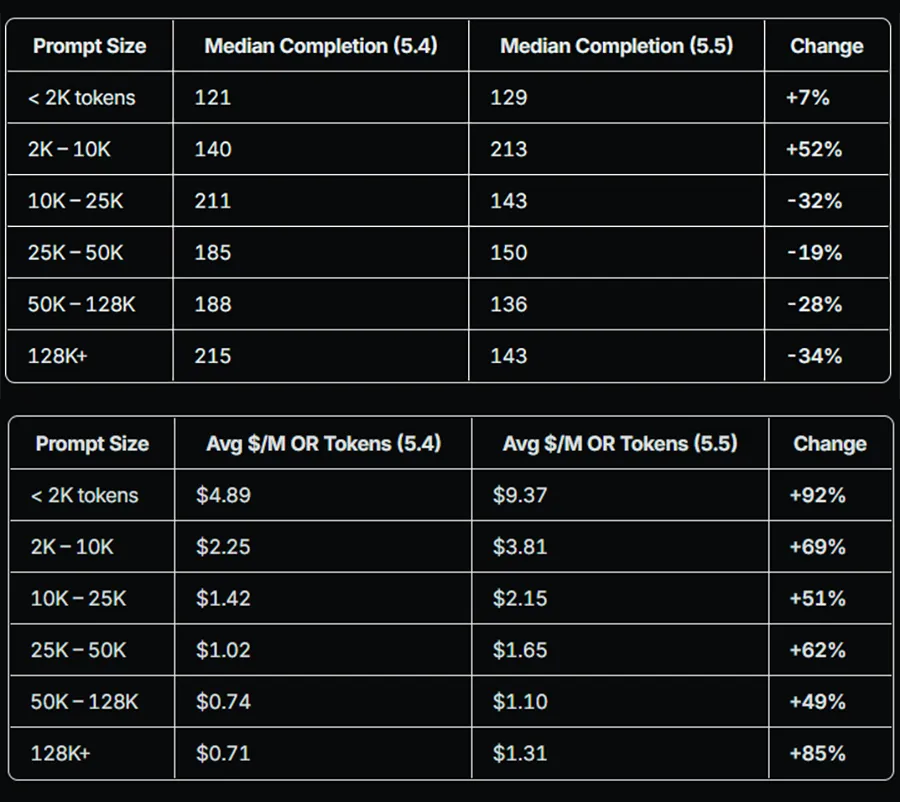
Quelle: openrouter
Opus 4.6 zu Opus 4.7: Kostensteigerung durch neuen Tokenizer
Bei Claude Opus 4.7 bleiben die offiziellen Basispreise exakt auf dem Niveau der älteren Vorgängerversion. Dennoch berichten Anwender von spürbar gestiegenen Ausgaben, da ein neu implementierter Tokenizer die Texteingaben völlig anders verarbeitet. Identische Anfragen erzeugen intern nun bis zu 45 Prozent mehr Token als noch bei Opus 4.6.
In der täglichen Praxis steigen die abgerechneten Kosten dadurch um 12 bis 27 Prozent. Dass der prozentuale Preissprung nicht noch deutlich höher ausfällt, liegt an der effizienten Caching-Funktion des Anbieters. Bei sehr großen Datenmengen puffert das System die neu entstandenen Token ab, was den finanziellen Mehraufwand für die Nutzer stark dämpft.
Eine bemerkenswerte Ausnahme bilden bei diesem Modell lediglich sehr kurze Anfragen von unter 2.000 Token. In diesem spezifischen Bereich arbeitet das aktualisierte System extrem fokussiert und liefert um 62 Prozent kürzere Antworten. Durch diese enorme Einsparung bei den generierten Texten sinken die realen Kosten für solche Aufgaben sogar minimal.
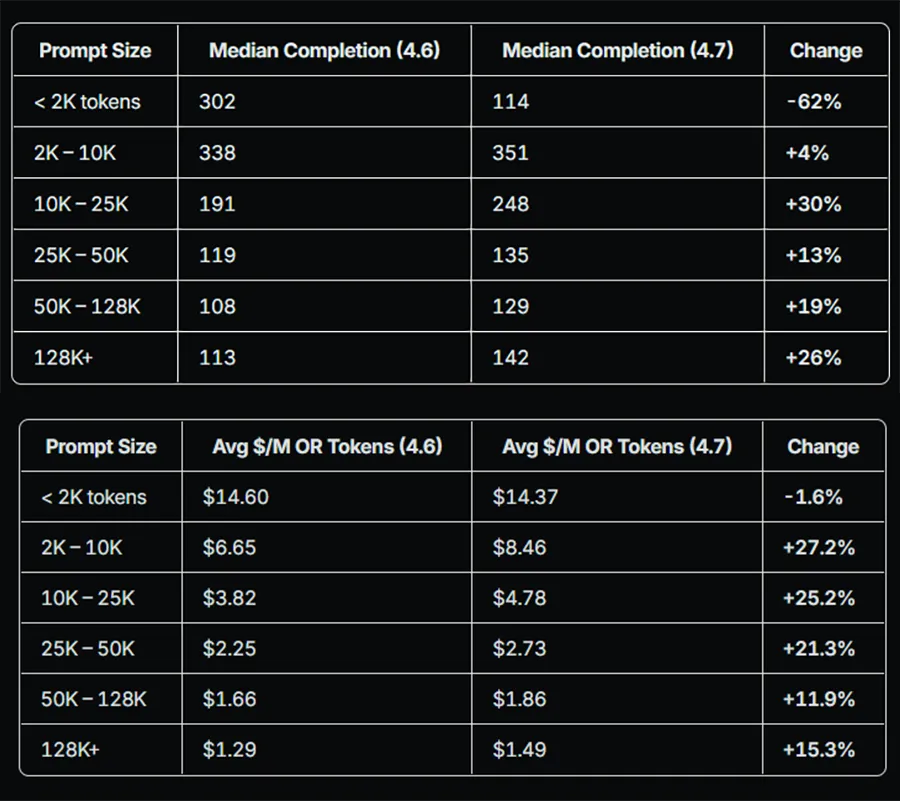
Quelle: openrouter
Gemini Pro 3.1 und Gemini Flash 3.5: Der teure Denker
Google positioniert Gemini 3.5 Flash eigentlich als besonders schnelles und effizientes Mittelklasse-Modell für Entwickler. Der Basispreis stieg zwar auch schon deutlich auf neun US-Dollar, bleibt damit aber trotzdem unter den zwölf US-Dollar des aktuellen Flaggschiffs Gemini 3.1 Pro. Dennoch übersteigen die Gesamtkosten der Flash-Variante im produktiven Alltag häufig die Ausgaben für das weitaus größere Modell.
Verantwortlich für diese Entwicklung ist ein exzessiver Token-Verbrauch im Hintergrund. Das KI-Modell generiert selbst im low-thinking-mode fortlaufend Tausende sogenannte »Thinking-Tokens« für interne Denkprozesse. Bei standardisierten Benchmarks verursacht Gemini 3.5 Flash dadurch Kosten von über 1.500 US-Dollar, während das Pro-Modell dieselben Aufgaben für unter 900 US-Dollar abschließt.
Technisch punktet die aktuelle Flash-Architektur zweifellos mit einer sehr hohen Verarbeitungsgeschwindigkeit von 219 Token pro Sekunde. Auch bei der Steuerung von autonomen Agenten-Aufgaben liefert das System exzellente Werte und schließt mühelos zur Konkurrenz auf. Dieser nachweisbare Leistungssprung wird jedoch durch den unerwartet teuren Denkmodus auf der monatlichen Rechnung erkauft. Zu Kosten, die man im ersten Moment nicht sieht.
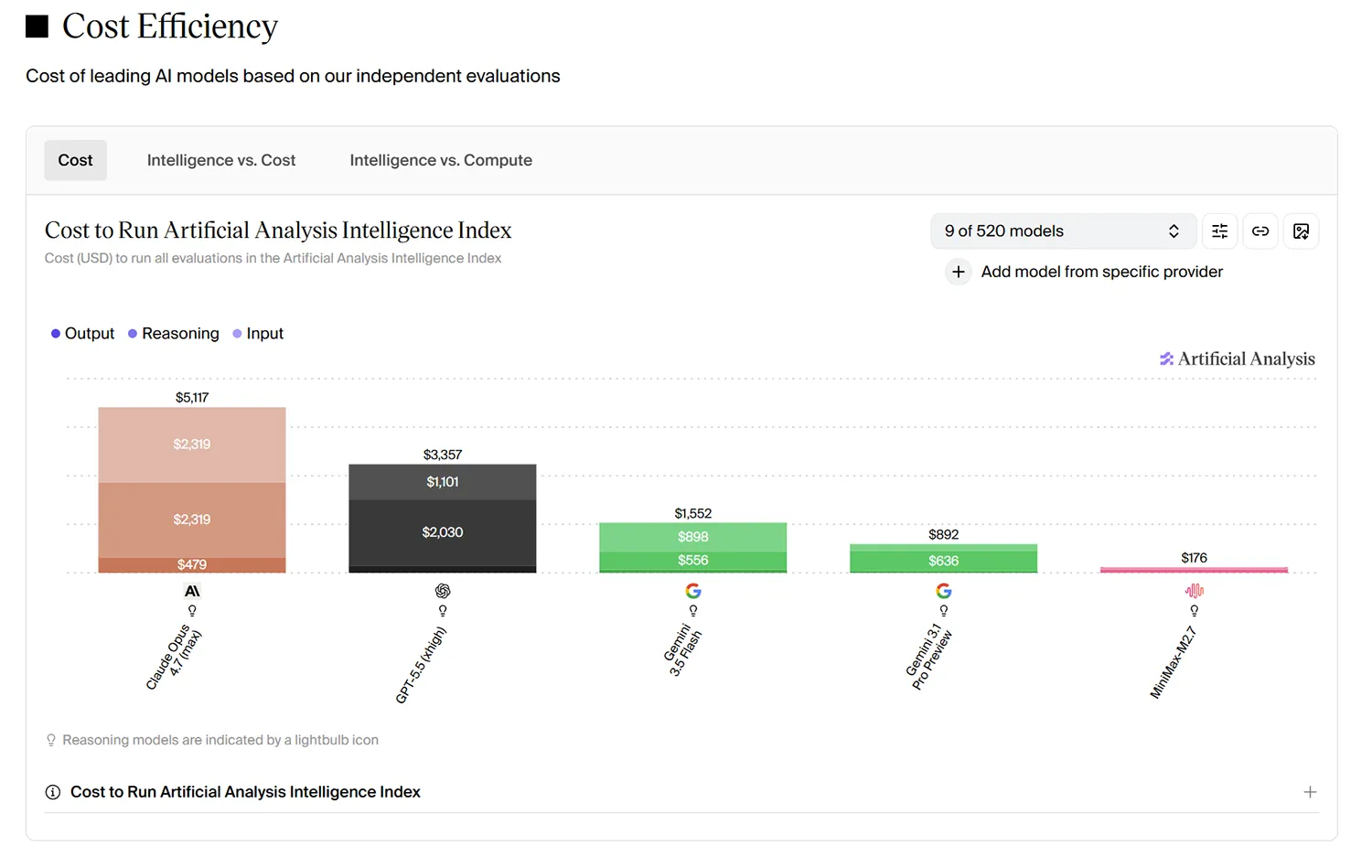
Quelle: artificialanalysis
Ein zweiter Blick auf die Kosten lohnt sich also!
Die Betrachtung der reinen Datenblätter reicht für eine belastbare Budgetplanung bei modernen KI-Modellen nicht mehr aus. Versteckte Denkprozesse, neue Tokenizer und veränderte Antwortlängen beeinflussen die finalen Ausgaben der Endnutzer erheblich.
Unternehmen und Entwickler müssen die tatsächlichen Token-Verbräuche ihrer spezifischen Anwendungen daher kontinuierlich überwachen und neu bewerten. Ein zweiter Blick auf die Kosten lohnt sich also.





