
Neuer Benchmark prüft Physik und Logik von KI-Videos
Der WorldReasonBench bewertet Videogeneratoren anhand von hunderten Testfällen auf ihre tatsächliche physikalische und soziale Konsistenz.

Moderne KI-Modelle erstellen verblüffend realistische Videos. Ein neuer wissenschaftlicher Test deckt nun auf, dass diese KI-Modelle grundlegende physikalische und logische Gesetze oft völlig missachten. Der Benchmark WorldReasonBench prüft das tatsächliche Weltverständnis der Generatoren auf Herz und Nieren.
Stresstest für das Weltverständnis
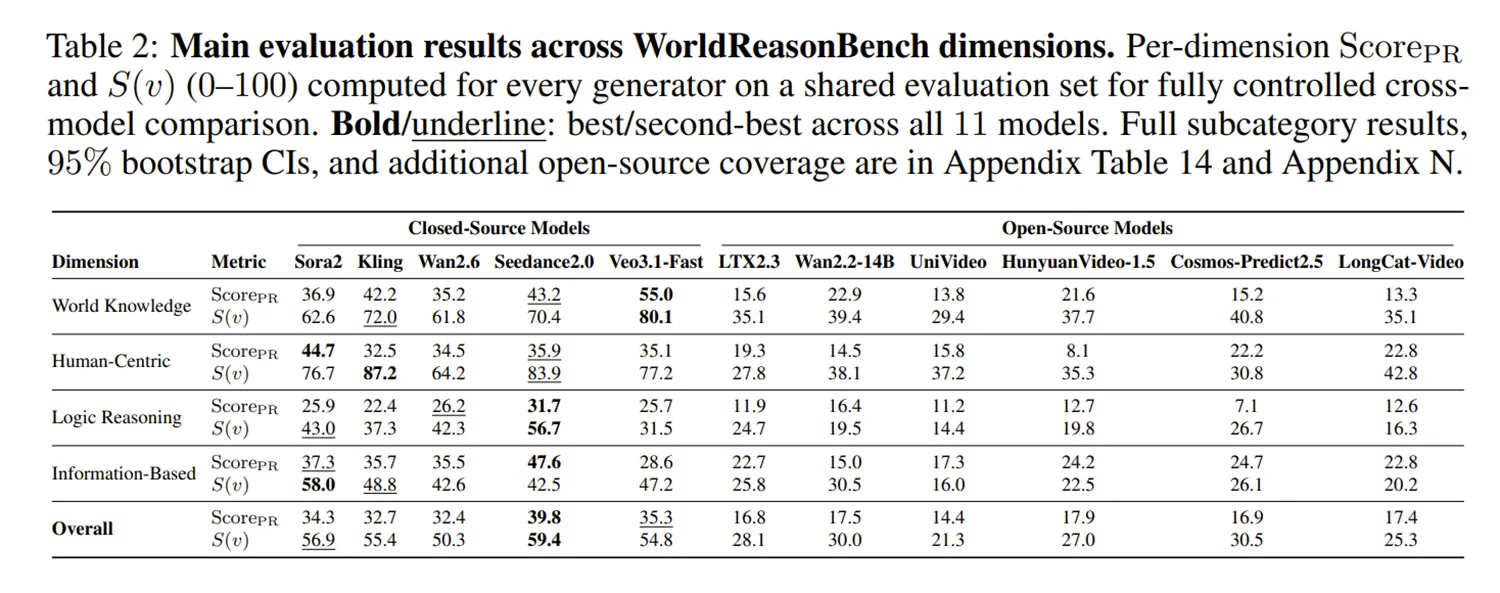
Forscher überprüfen mit dem WorldReasonBench nicht mehr nur die reine visuelle Qualität. Der neue Benchmark legt den Fokus voll auf die physikalische, soziale und logische Konsistenz der erzeugten Szenen. Die Entwickler nutzen dafür 436 spezielle Testfälle, die sich über vier verschiedene Bewertungsdimensionen erstrecken.
Die Methodik fordert die KI-Modelle heraus, zukünftige Zustände einer Welt korrekt vorherzusagen. Fällt ein Ball im Video, muss er physikalisch korrekt vom Boden abprallen und darf nicht einfach verschwinden. Viele optisch beeindruckende Modelle scheitern an exakt solchen trivialen Alltagsaufgaben.
Zusätzlich integriert das Testverfahren den sogenannten WorldRewardBench. Dieser Datensatz umfasst knapp 6.000 Expertenbewertungen über mehr als 1.400 generierte Videos. Das schafft eine enorm fundierte Datengrundlage für die Beurteilung der KI-Modelle.

Quelle: https://arxiv.org/pdf/2605.10434
Spitzenreiter und Verfolger
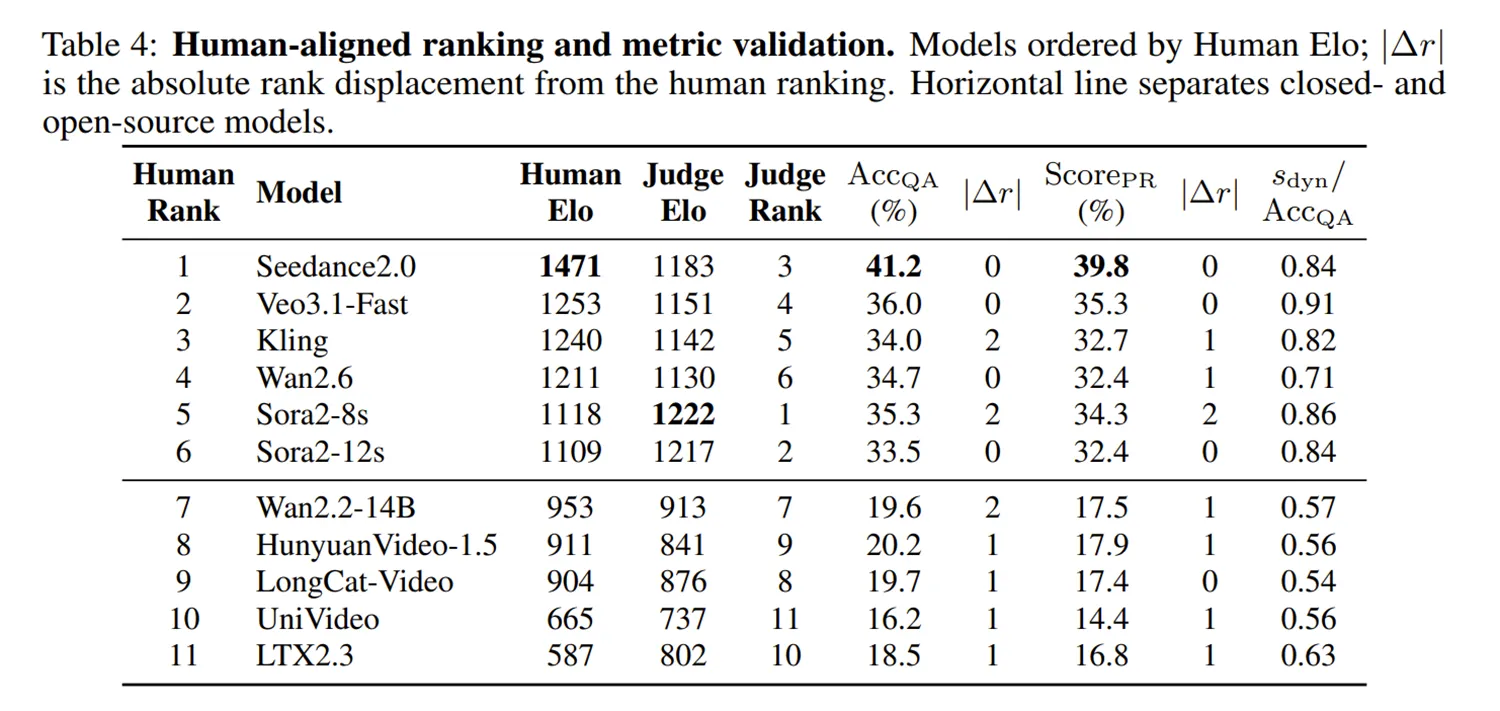
Die Auswertung zeigt gravierende Leistungsunterschiede zwischen den aktuellen Anbietern. Das KI-Modell Seedance2.0 sichert sich souverän den ersten Platz im Ranking der menschlichen Prüfer. Es erreicht die höchste Gesamtpunktzahl und demonstriert das verlässlichste logische Denkvermögen aller Testkandidaten.
Direkt auf dem zweiten Platz positioniert sich Veo3.1-Fast. Dieses KI-Modell glänzt laut den Daten besonders beim grundlegenden Weltwissen und liefert dort die besten Einzelwerte. Die Modelle Kling und Wan2.6 sichern sich solide Platzierungen im vorderen Mittelfeld.
Sora2 behauptet eine starke Position bei spezifischen, menschenzentrierten Szenen. Das System erzeugt besonders glaubwürdige und korrekte Interaktionen zwischen Personen im Video. Bei tieferen logischen Schlussfolgerungen fällt das Modell jedoch messbar hinter die Spitzenreiter zurück.
Offene Modelle bleiben zurück
Die umfangreiche Studie offenbart eine sehr große Lücke zwischen kommerziellen und frei zugänglichen Ansätzen. Open-Source-Modelle wie Wan2.2-14B oder HunyuanVideo-1.5 erreichen bei weitem nicht das Niveau der geschlossenen KI-Modelle. Sie bilden in fast allen Testkategorien das absolute Schlusslicht.
Solche frei verfügbaren KI-Modelle generieren häufig physikalisch völlig unmögliche Abläufe. Objekte verschmelzen fehlerhaft miteinander oder verändern spontan ihre Form. Das mindert die Nutzbarkeit für ernsthafte Anwendungen enorm.
Optik schlägt Logik
Ein visuell fotorealistisches Video garantiert heute noch keine korrekte Darstellung der Wirklichkeit. Die KI-Modelle lernen primär optische Pixel-Muster, ohne die zugrunde liegenden Naturgesetze wirklich zu verstehen. Viele Forscher sehen genau hierin eine der größten aktuellen Hürden der KI-Entwicklung.
Die Testergebnisse des WorldReasonBench bieten nun eine klare Metrik für kommende Entwicklungszyklen. Die Anbieter müssen ihren KI-Modellen ein echtes, grundlegendes physikalisches Verständnis antrainieren. Ohne diese Fähigkeiten bleiben die generierten Videos schöne, aber fehlerhafte Illusionen.





