Claude Code: Best Practices für riesige Codebasen
Ein neuer Leitfaden zeigt die optimale Konfiguration von KI-Modellen für große Projekte.
Anthropic hat einen detaillierten Leitfaden veröffentlicht, der den effizienten Einsatz von Claude Code in gigantischen Codebasen beleuchtet. Dabei zeigt der Entwickler auf, wie KI-Modelle durch gezielte Strukturierung und dedizierte Agenten selbst in Millionen Zeilen altem Legacy-Code zielsicher navigieren.
Dynamische Suche statt veralteter Indizes
Im Gegensatz zu vielen anderen Ansätzen verzichtet Claude Code auf statische Abfragen, bei denen der gesamte Code vorab indiziert wird. Solche zentralisierten Systeme scheitern oft in großen Umgebungen, da ständige Code-Änderungen von hunderten Entwicklern das System schnell asynchron werden lassen. Das Modell findet dann gelöschte Module oder umbenannte Funktionen.
Stattdessen setzt die Software auf eine agentenbasierte Suche direkt auf dem lokalen Rechner. Das KI-Modell durchsucht das Dateisystem ähnlich wie ein menschlicher Programmierer. Es liest Dateien aus, nutzt Kommandozeilenbefehle zum Filtern und folgt Referenzen in Echtzeit auf dem exakten Stand des Live-Codes.
Anzeige
Das Ökosystem entscheidet über den Erfolg
Die reine Leistung des zugrundeliegenden KI-Modells reicht für komplexe Enterprise-Projekte jedoch nicht aus. Die Umgebungsspezifikationen, von Anthropic als »Harness« bezeichnet, bestimmen maßgeblich die Effizienz. Ohne klare Strukturen verliert sich die KI in der schieren Datenmenge.
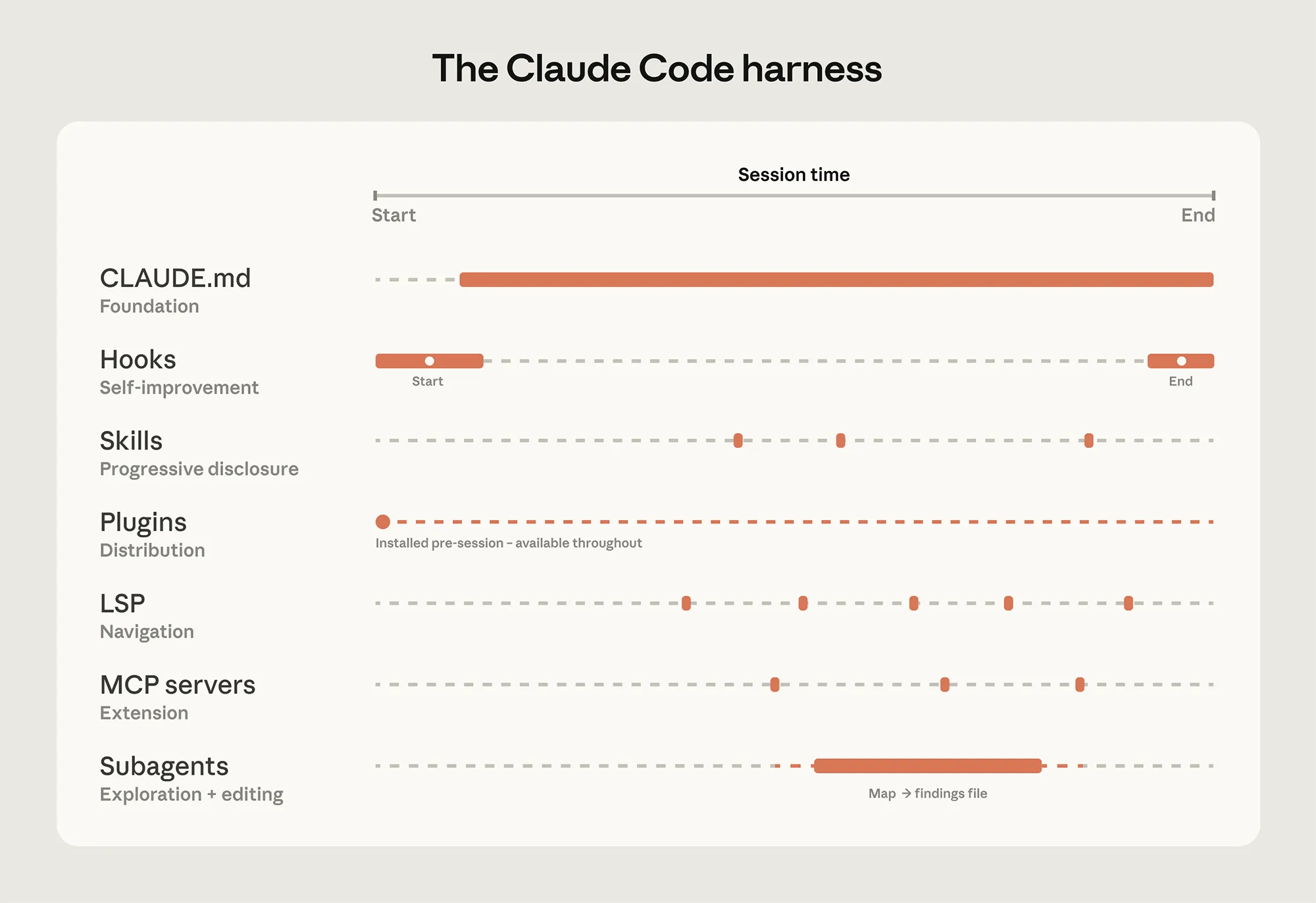
Quelle: Anthropic
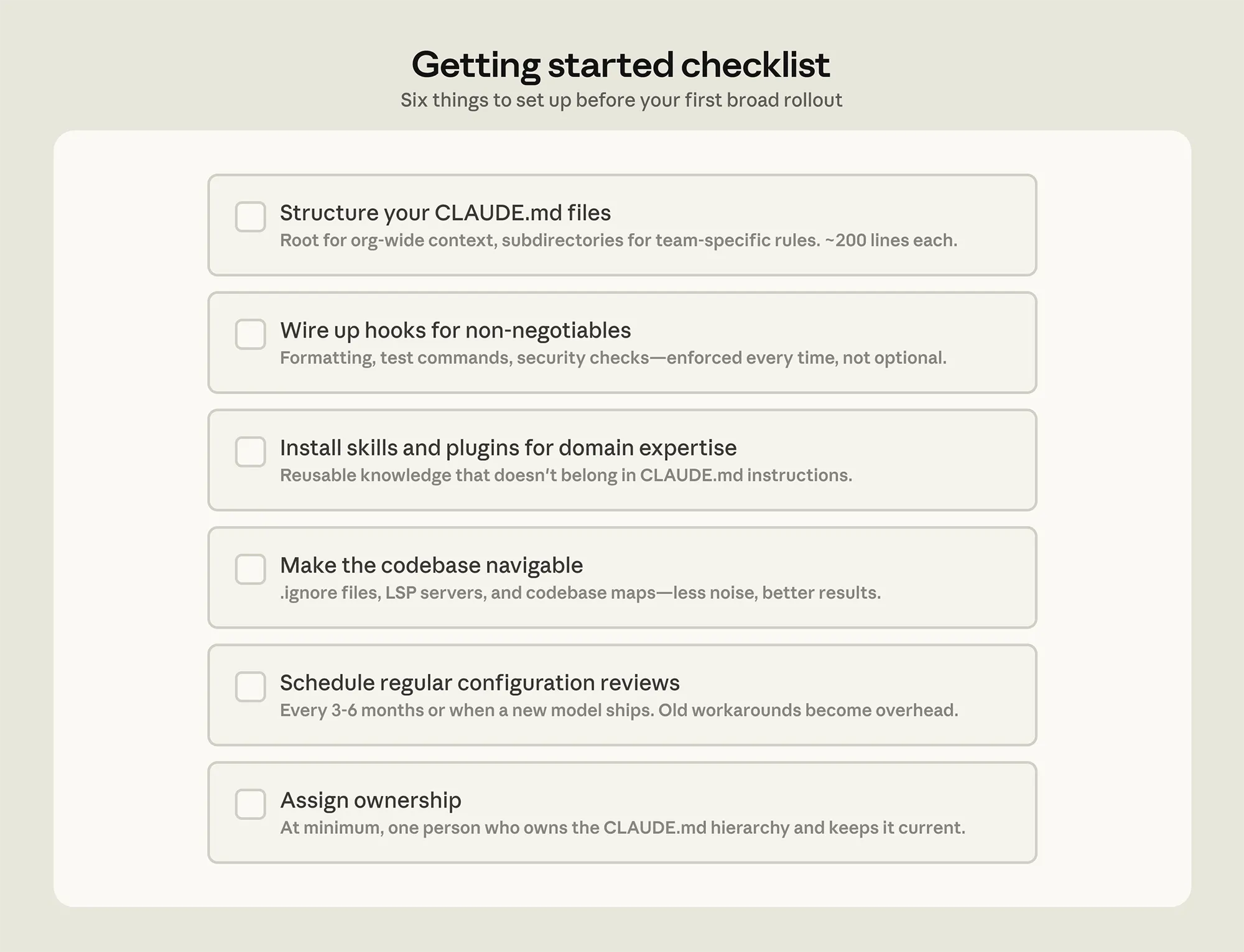
Sogenannte Kontextdateien liefern das notwendige Hintergrundwissen für den Start. Diese Dateien müssen zwingend schlank gehalten werden. Übergreifende Projektinformationen liegen im Hauptverzeichnis, während spezifische Konventionen und Befehle tief in den jeweiligen Unterordnern platziert werden.
Eine nahtlose Integration des Language Server Protocols sorgt zudem für eine extrem präzise Navigation. Anstatt den Code nur nach Textbausteinen zu durchkämmen, erkennt das System exakte Funktionsaufrufe über verschiedene Programmiersprachen hinweg auf reiner Symbolebene.
Modularität durch Skills und Subagenten
Spezifisches Fachwissen muss nicht permanent im Kontextfenster vorgehalten werden. Modulare Fähigkeiten laden sich bei optimaler Konfiguration nur dann dynamisch dazu, wenn eine spezifische Aufgabe diese explizit erfordert.
Ein Sicherheits-Review-Skill aktiviert sich beispielsweise ausschließlich bei der Untersuchung von Schwachstellen im Quelltext. Für ausladende Analysen lassen sich isolierte Subagenten starten, die losgelöst vom Hauptprozess arbeiten und lediglich das finale, gefilterte Ergebnis an die Hauptinstanz zurückliefern.
Entwickler-Teams fassen funktionierende Setups häufig in verteilbaren Plugins zusammen. Dadurch erhalten neue Mitarbeiter direkt am ersten Tag exakt die gleiche, optimierte Arbeitsumgebung wie erfahrene Kollegen.
Anzeige
Wartung und organisatorische Verantwortung
Spezifische Anweisungen für ältere KI-Modelle können modernere, intelligentere Versionen ungewollt ausbremsen. Daher erfordern die Projekt-Setups alle drei bis sechs Monate eine detaillierte Überprüfung, um veraltete Restriktionen rechtzeitig zu entfernen.
Neben der technischen Ebene entscheidet letztendlich auch die interne Organisation über die Adaption im Unternehmen. Erfolgreiche Einführungen basieren beinahe immer auf einer zentralen Verwaltung durch einen dedizierten Verantwortlichen.
Solche Agent Manager bündeln funktionierende Konzepte und verhindern eine Fragmentierung der genutzten Tools innerhalb der gesamten Entwicklungsabteilung. Fehlt diese zentrale Steuerung, stagniert die interne Nutzung meist auf einem sehr frühen Niveau.