
KI-Agenten sind deutlich intelligenter als gedacht
Das AI Safety Institute warnt vor zu knappen Budgets bei KI-Tests. Die Modelle können deutlich mehr als gedacht.

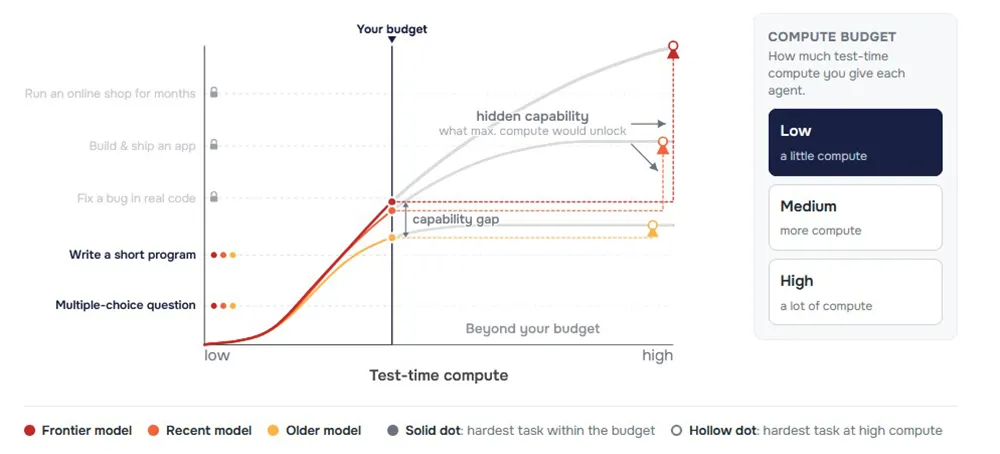
Das britische AI Safety Institute (AISI) belegt in einer neuen Untersuchung, dass Standard-Benchmarks die Fähigkeiten aktueller KI-Agenten systematisch unterschätzen. Erhalten diese bei Tests ein größeres Budget an Rechenleistung, lösen sie deutlich komplexere Aufgaben.
Versteckte Fähigkeiten durch strenge Token-Limits
Bisherige Bewertungen reduzieren die Leistung von KI-Agenten oft auf eine einzige Punktzahl. Diese Metrik verdeckt, dass Tests meist die Rechenleistung streng begrenzen, die vor einem Abbruch aufgewendet werden darf.
Das AISI hat aktuelle Modelle mit großen Budgets an Test-Time Compute geprüft. Feste Budgets bewerten die Leistungsfähigkeit besonders von neueren KI-Agenten systematisch unter. Diese können die zugewiesenen Tokens seriell für lange Lösungswege oder parallel für mehrere Versuche nutzen.
In der Cybersicherheits-Umgebung des AISI stieg die Erfolgsquote stetig mit dem Compute-Budget. Rund acht Prozent der Aufgaben wurden erst gelöst, als das Limit zehn Millionen Tokens überstieg. Einzelne Herausforderungen erforderten bis zu 50 Millionen Tokens.
Quelle: AISI
Längere Aufgaben fressen Budgets auf
Die benötigte Rechenleistung eines KI-Agenten steigt proportional zu der Zeit, die ein menschlicher Experte benötigen würde. Ein gedeckeltes Testbudget führt dazu, dass den Modellen bei den längsten Aufgaben zuerst die Tokens ausgehen.
Ein Fehlschlag in einem Benchmark bedeutet daher oft nur, dass der Versuch vorzeitig abgebrochen wurde. Er ist kein Beweis für fehlende Fähigkeiten. Die Cyber-Aufgabe »The Last Ones« erfordert von einem Menschen etwa 20 Stunden. Kein Modell konnte sie abschließen, bis es mindestens 30 Millionen Tokens erhielt.
Verzerrte Fortschrittsmessung
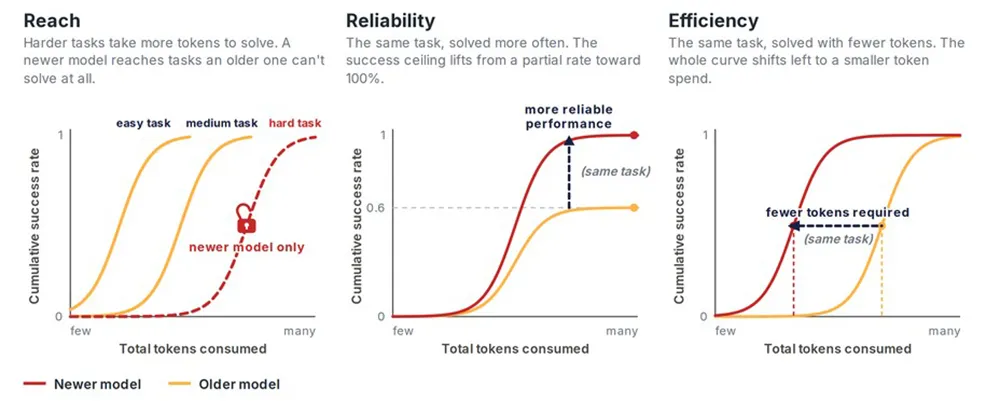
Aktuelle Modelle wandeln zusätzliches Test-Time Compute in deutlich größere Leistungssteigerungen um als ältere Versionen. Sie lösen schwerere Aufgaben, arbeiten zuverlässiger und lösen Probleme effizienter.
Diese Dynamik verändert die gemessene Fortschrittsgeschwindigkeit. Berechnet das AISI die Leistungsverdopplung bei Cyber-Aufgaben mit 50 Millionen statt 2,5 Millionen Tokens, fällt der Trend um 60 Prozent steiler aus. Die angenommene Entwicklungsgeschwindigkeit ist somit oft ein direktes Resultat des gewählten Testbudgets.
Quelle: AISI
Neue Testverfahren für verlässliche Risikobewertung
Solche Messfehler verzerren Entscheidungen über Bereitstellung und Risikobewertung. Ein unterfinanzierter Test lässt ein KI-Modell harmloser erscheinen, als es im realen Einsatz mit unbegrenzter Rechenleistung wäre.
Das AISI evaluiert Frontier-Modelle künftig über mehrere Budgets hinweg. Damit stellen sie sicher, dass schwache Ergebnisse tatsächlich auf fehlende Fähigkeiten zurückgehen und nicht auf zu früh beendete Evaluierungen.





