Der BullshitBench entlarvt die Schwächen von OpenAI und Google
Ein spezieller Benchmark zeigt, dass moderne KI-Systeme kaum noch Widerspruch einlegen. Einzig Anthropic verbessert sich kontinuierlich.

Zahlreiche aktuelle KI-Sprachmodelle fallen auf absichtlich unsinnige Eingaben herein. Der gerade aktualisierte Test "BullshitBench v2" zeigt, dass die meisten Systeme fehlerhafte Anfragen nicht ablehnen, sondern völlig selbstbewusst falsche Antworten erfinden. Dabei gibt es beachtliche Qualitätsunterschiede zwischen den Herstellern.
Der Test für logischen Unsinn
Der Benchmark prüft gezielt, wie KI-Modelle auf unmögliche oder absichtlich fehlerhafte Szenarien reagieren. Die Testfragen decken verschiedene Fachbereiche ab, darunter Programmierung, Medizin, Recht, Finanzen und Physik. Ein gutes System muss den inhaltlichen Fehler im Prompt erkennen und der Eingabe widersprechen. Insgesamt wurden für die zweite Version des Tests über 70 Modellvarianten mit 100 neuen Fragen konfrontiert.
Über alle Fachbereiche hinweg bleibt die Fehlerquote hoch. Die Systeme erkennen den Unsinn in medizinischen Fragen nicht besser als in reinen Programmieraufgaben.
Anzeige
Klare Sieger und Verlierer
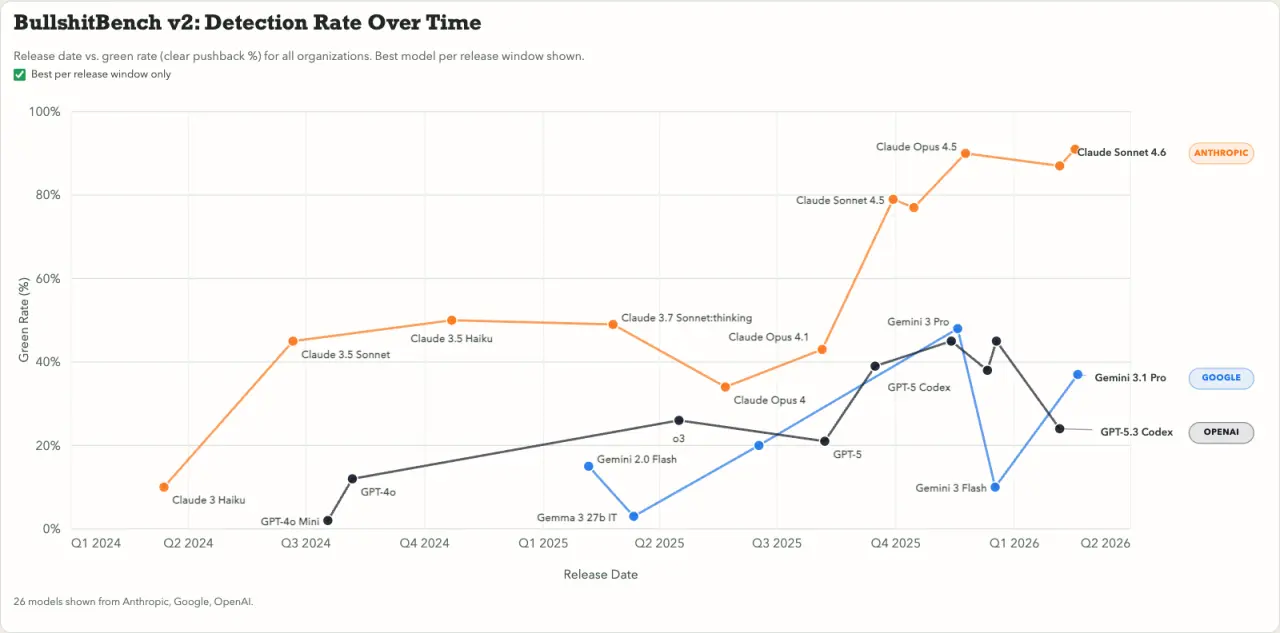
Die Auswertung der Testergebnisse zeichnet ein klares Bild der aktuellen Marktlandschaft. Modelle der Claude-Reihe von Anthropic, insbesondere Versionen wie Claude Sonnet 4.6, dominieren das Feld und weisen fehlerhafte Eingaben sehr zuverlässig ab. Auch das Open-Source-Modell Qwen3.5 von Alibaba liefert hier starke Ergebnisse.
Die prominenten Systeme von OpenAI und Google fallen im direkten Vergleich deutlich ab. Modelle wie Gemini 3.1 Pro oder GPT-5.3 Codex landen im Mittelfeld oder sogar auf den hinteren Plätzen. Sie neigen stark dazu, den falschen Prämissen des Nutzers zu folgen und unbrauchbare Antworten zu generieren.
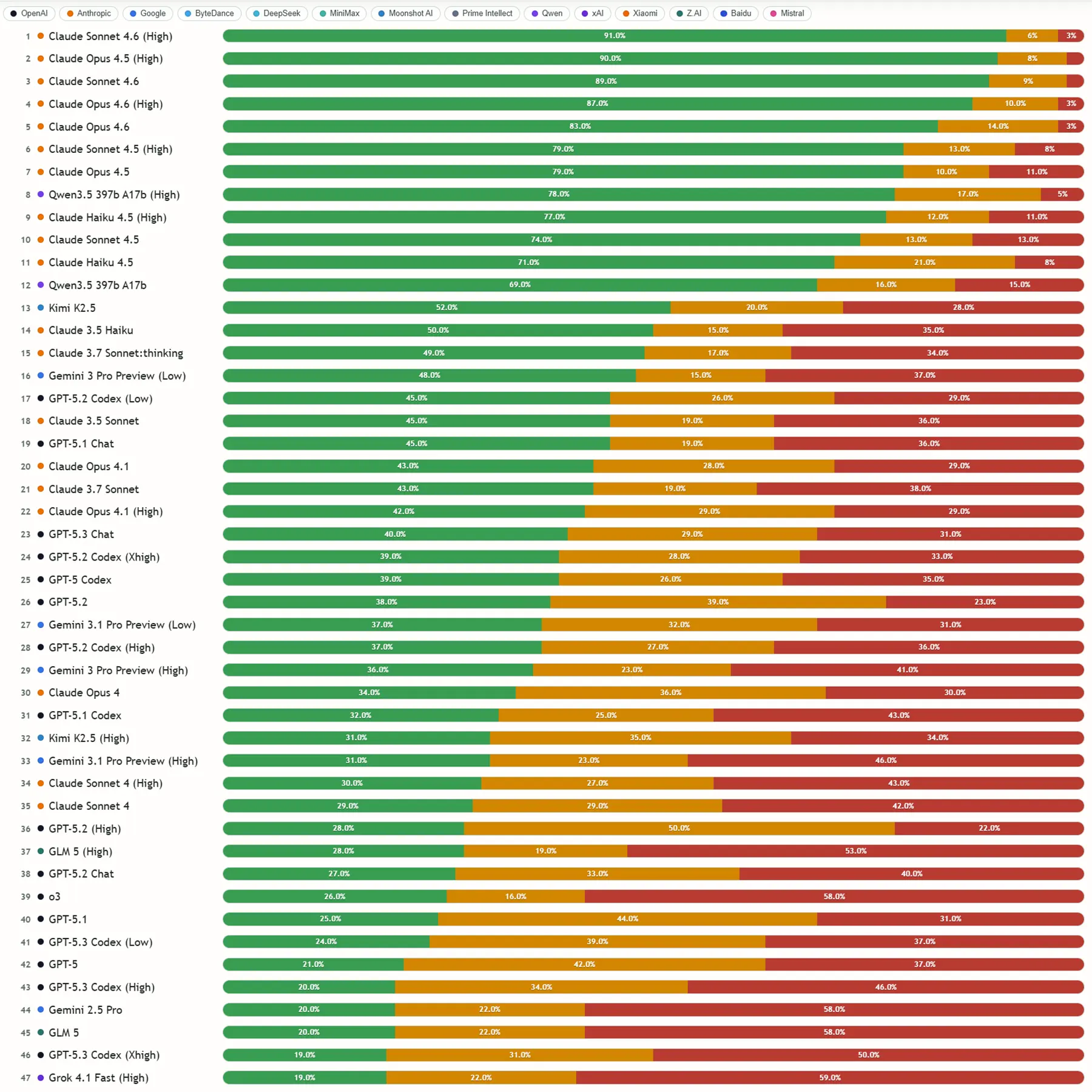
Quelle: petergpt.github.io
Die Falle der Denkpause
Eine überraschende Erkenntnis betrifft die sogenannten Reasoning-Modelle. Diese KI-Systeme nutzen vor der eigentlichen Textausgabe Rechenzeit für einen internen Lösungsweg, messbar in Reasoning-Tokens. Die Daten zeigen einen negativen Zusammenhang auf: Je mehr Tokens ein Modell für das Nachdenken aufwendet, desto seltener erkennt es den fehlerhaften Prompt.
Die Systeme verfangen sich offensichtlich in ihren eigenen Lösungsversuchen. Sie versuchen unter allen Umständen, die Anfrage zu beantworten, anstatt einen logischen Schritt zurückzutreten und die Grundannahme des Nutzers infrage zu stellen.
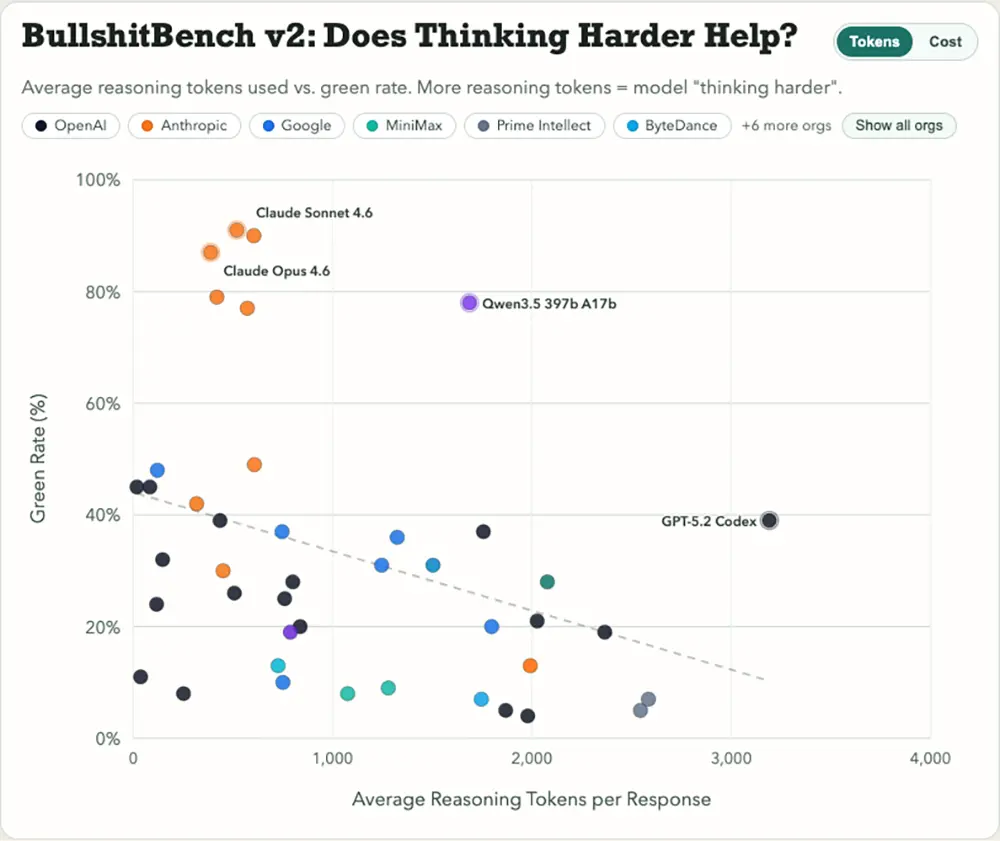
Quelle: petergpt.github.io
Stagnation bei neuen Versionen
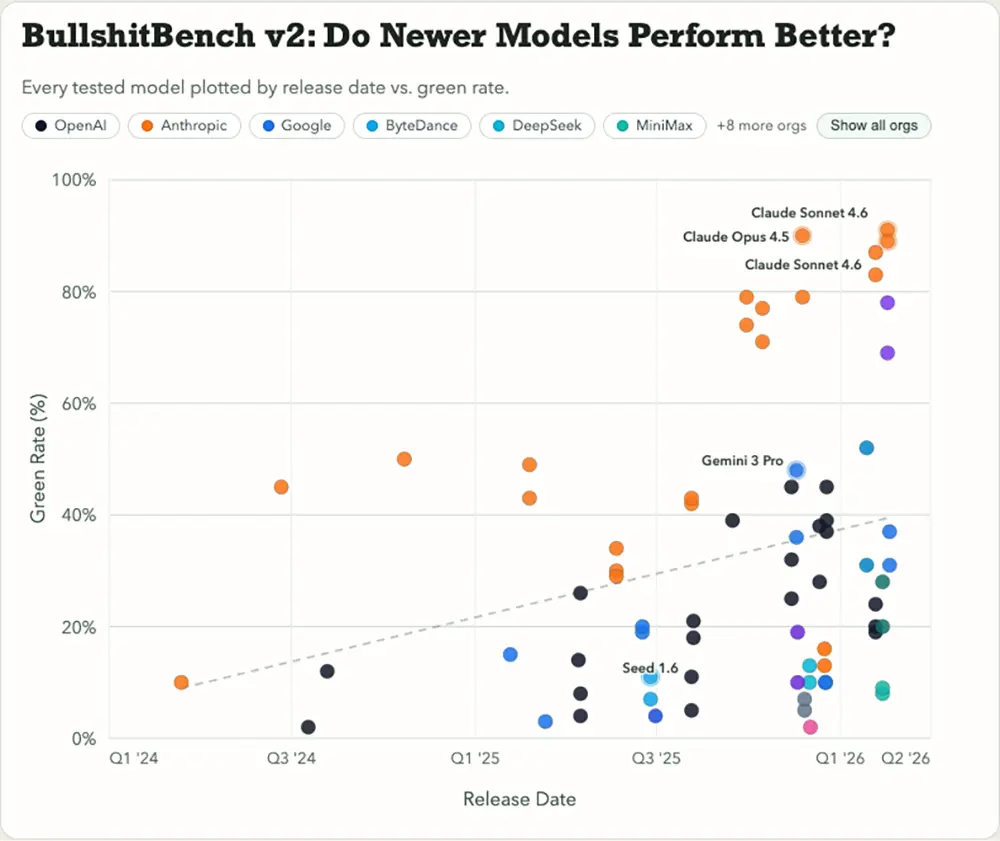
Der Blick auf das Veröffentlichungsdatum der getesteten KI-Modelle offenbart ein generelles Problem in der Entwicklung. Die Fähigkeit, auf unsinnige Prompts mit Ablehnung zu reagieren, verbessert sich im Branchendurchschnitt nicht.
Während Anthropic diese Eigenschaft mit jedem neuen Release kontinuierlich optimiert, zeigen die Modelle der Konkurrenz fast durchgehend eine Stagnation. Ein aktuelles Sprachmodell fällt in diesem speziellen Leistungstest somit oft genauso leicht auf eine unlogische Frage herein wie ein Modell aus dem vergangenen Jahr. Dieser Trend deutet darauf hin, dass viele Entwickler ihren Fokus derzeit auf andere Bewertungskriterien legen.