
Claude verliert: Neuer Coding-Benchmark macht Mogeln unmöglich
Der neue Härtetest verhindert Betrug durch bekannte Trainingsdaten. Anthropic und Google fallen deutlich zurück.

Forscher präsentieren mit DeepSWE einen neuartigen Härtetest für programmierende KI-Modelle. Der Benchmark schließt rigoros aus, dass die Probanden die geforderten Lösungen bereits aus ihren Trainingsdaten kennen. Die ersten Auswertungen zeigen ein klares Bild: Das KI-Modell GPT-5.5 von OpenAI setzt sich deutlich von der Konkurrenz ab.
Das Problem mit bekannten Leistungstests
Bisherige Leistungstests für Code-generierende KI-Modelle stehen zunehmend in der Kritik. Der populäre SWE-Bench Pro greift beispielsweise auf bestehende Probleme und Lösungen aus der Plattform GitHub zurück. Das birgt ein hohes Risiko für Kontamination. Viele KI-Modelle haben diese offenen Daten bereits während ihres Trainings verarbeitet und rufen lediglich bekannte Lösungen ab, anstatt wirklich neue Probleme zu lösen.
Zudem offenbaren ältere Tests deutliche Schwächen bei der automatischen Bewertung. Analysen zeigen, dass der bisherige Standard-Benchmark gültige Lösungen in 24 Prozent der Fälle fälschlicherweise ablehnt. Umgekehrt lässt er fehlerhaften Code in rund acht Prozent der Fälle unbemerkt passieren. Eine verlässliche Einordnung der Leistungsfähigkeit fällt Entwicklern damit schwer.
Anzeige
Komplexer und realitätsnäher
DeepSWE wählt daher einen anderen Ansatz. Die Initiatoren haben für diesen Benchmark 113 völlig neue Aufgaben quer durch 91 aktive Open-Source-Projekte geschrieben. Diese Referenzlösungen wurden nie veröffentlicht. Ein KI-Modell kann die Antwort folglich nicht auswendig lernen, sondern muss den Code tatsächlich selbstständig erarbeiten.
Die Anforderungen spiegeln den echten Entwickleralltag zudem deutlich besser wider. Die Prompts sind kürzer und natürlicher formuliert. Dennoch fordern sie den KI-Modellen mehr Leistung ab. Im Schnitt erfordern die Lösungen bei DeepSWE das Hinzufügen von 668 Codezeilen verteilt über sieben Dateien. Beim Vorgänger-Test waren es lediglich 120 Zeilen.
Dabei prüft DeepSWE ausschließlich das finale Verhalten des Codes. Es spielt keine Rolle, wie das KI-Modell die interne Struktur aufbaut, solange das gewünschte Endresultat fehlerfrei funktioniert.
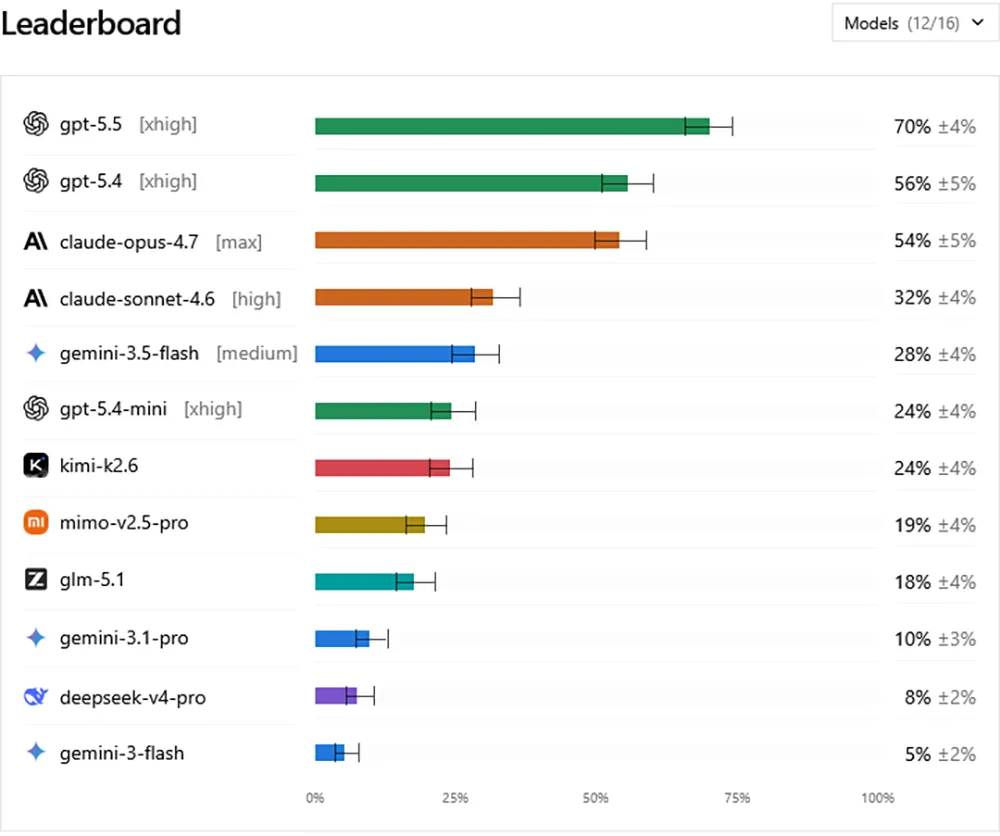
Quelle: https://deepswe.datacurve.ai/blog
Spitzenreiter und Verlierer
Das neue Testverfahren sorgt für deutliche Abstände zwischen den führenden Anbietern. Auf dem Spitzenplatz landet aktuell GPT-5.5 mit einer Erfolgsquote von 70 Prozent. Dahinter folgen GPT-5.4 mit 56 Prozent und Claude Opus 4.7 von Anthropic mit 54 Prozent. Googles Gemini 3.5 Flash erreicht lediglich 28 Prozent.
Der Test deckt auch spezifische Charakterzüge der jeweiligen KI-Modelle auf. Die Claude-Familie neigt bei mehrteiligen Prompts dazu, einzelne Anforderungen schlicht zu vergessen und nur die Hälfte der Aufgabe zu erledigen. GPT-Modelle halten sich hingegen extrem präzise an die Vorgaben.
Gleichzeitig prüfen stärkere KI-Modelle ihre eigene Arbeit häufiger ungefragt mit neuen Tests. DeepSWE liefert Entwicklern durch diese detaillierten Auswertungen eine belastbare Datengrundlage für die Wahl der passenden KI.
Wir können die grundlegenden Ergebnisse ebenfalls unterstreichen. Das Meinungsbild hat sich bei vielen Entwicklern mit Codex 5.5 geändert. Während Claude zuvor unangefochten an der Spitze stand, hat man mit GPT 5.5 nun mindestens eine gleichwertige Alternative.





