So lernt der KI Agent künftig selbstständig
Die Funktion Brain speichert keine Nutzerdaten, sondern Arbeitsschritte. Das senkt Kosten und steigert die Präzision.

Perplexity testet ein neues Gedächtnissystem namens »Brain«. Das System speichert nicht primär Nutzerpräferenzen, sondern analysiert die eigenen Arbeitsschritte, Fehler und Korrekturen. KI-Agenten sollen dadurch mit jeder Aufgabe effizienter arbeiten.
Lernen aus Fehlern
Traditionelle Memory-Funktionen in der KI konzentrieren sich auf den Anwender. Sie speichern Vorlieben, Schreibstile oder Rollenbeschreibungen. Perplexity wählt einen anderen Weg.
Das System protokolliert, was der KI-Agent – bei Perplexity »Computer« genannt – getan hat. Er erfasst, welche Quellen nützlich waren, welche Ansätze fehlschlugen und wie Nutzer die Ergebnisse nachträglich korrigiert haben. Dieses Feedback fließt in einen Kontext-Graphen. Er funktioniert wie ein internes LLM-Wiki innerhalb der Agenten-Sandbox.
Anzeige
Nächtliche Updates
Brain aktualisiert dieses Wiki in festgelegten Intervallen, beispielsweise über Nacht. Es führt vergangene Sitzungen, veränderte Quelldokumente und Nutzerkorrekturen zusammen. Jeder neue Arbeitstag startet für den Agenten mit diesem aktualisierten Wissen. Er kennt seine Fehler der Vergangenheit und greift direkt auf die zuverlässigsten Quellen zu. Das spart Zeit und reduziert den Token-Verbrauch.
Eine von Perplexity veröffentlichte Studie quantifiziert die Leistungssteigerung. Bei bekannten Aufgaben steigt die Korrektheit der Antworten um 25 Prozent. Die Trefferquote relevanter Informationen wächst um 16 Prozent.
Die Agenten arbeiten messbar effizienter. Die Auswertungen zeigen einen Effizienzgewinn durch weniger benötigte Arbeitsschritte. Die Kosten für Aufgaben mit historischem Kontext sinken um 13 Prozent.
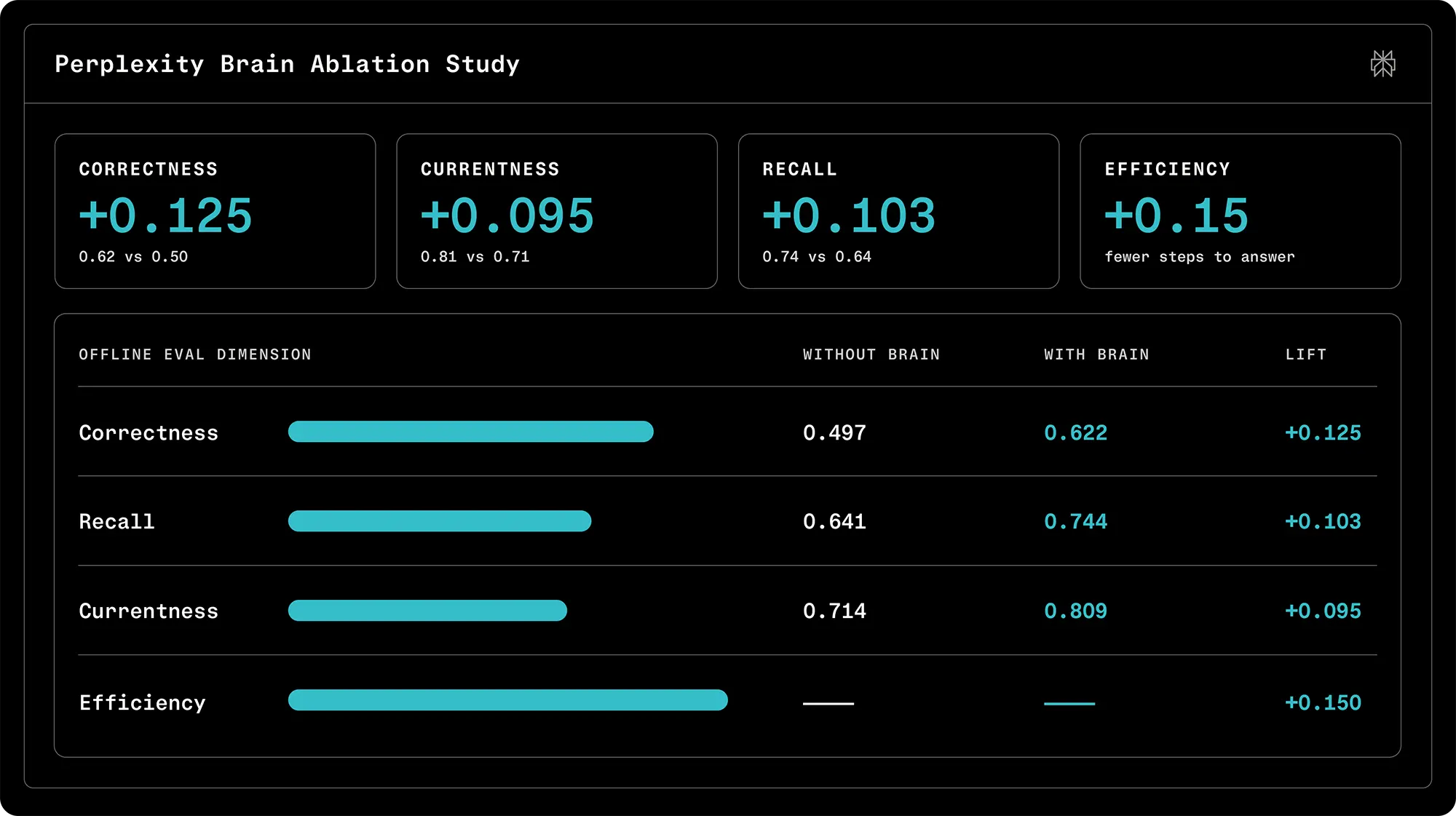
Quelle: Perplexity
Transparenz und Verfügbarkeit
Jeder Gedächtniseintrag bleibt transparent. Brain verlinkt die gesammelten Informationen stets auf die ursprüngliche Sitzung, Datei oder Quelle.
Perplexity hat Brain für Nutzer der Tarife Max und Enterprise Max als Research Preview freigeschaltet. Künftig sollen die Agenten durch dieses kontinuierliche Lernen Probleme in Datensätzen eigenständig erkennen, bevor Anwender sie überhaupt bemerken.





