
KI-Tool zeigt die »wichtigsten« Menschen der Welt
Intheweights prüft, ob eine Person wichtig genug war, um dauerhaft im knappen Speicherplatz der KIs zu bleiben.

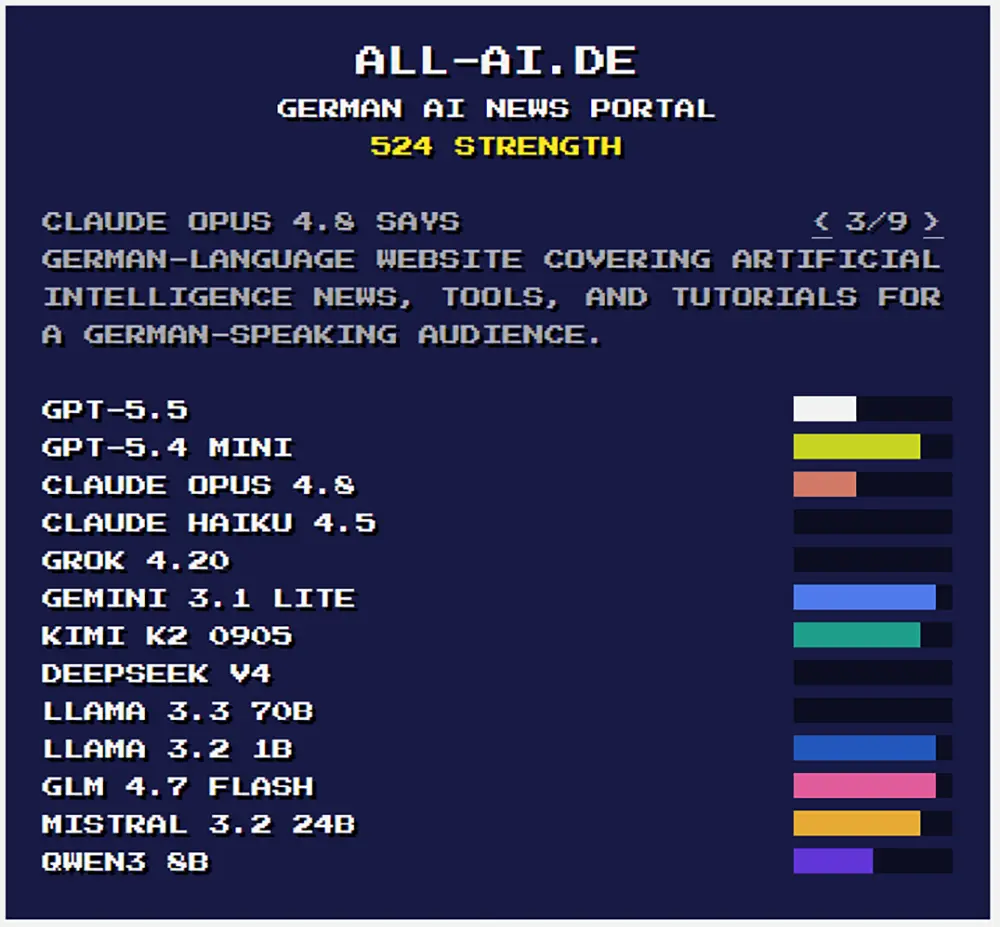
Die Entwickler Thomas Dimson und Joey Flynn haben mit »intheweights.com« ein neues Analyse-Tool veröffentlicht. Die Website prüft, ob und wie gut Sprachmodelle wie GPT-5.5, Opus 4.8 oder Gemini 3.1 Lite reale Personen auswendig kennen. Wer dort einen hohen Wert erzielt, wurde beim Training als wichtig erachtet und ist fest in den Gewichten (Weights) des Modells kodiert.
Quelle: intheweights
Wissen ohne Websuche
Große Sprachmodelle speichern Informationen über Milliarden dieser Zahlenwerte ab. Befindet sich eine Person in diesen Gewichten, kann das Modell ihre Biografie direkt abrufen, ohne auf externe Hilfsmittel wie eine Websuche zurückzugreifen. Ob jemand in diesem neuronalen Gedächtnis landet, bestimmen die Architektur, die Trainingsdaten und vor allem die Größe des Modells.
Je kleiner das Sprachmodell, desto strenger die Selektion. Taucht ein Name etwa in einer kompakten Version wie Llama 3.2 1B auf, ist das ein Indiz für extrem hohe Relevanz. Die Person belegt dann einen messbaren Teil des knapp ein Gigabyte großen Speichers.
Anzeige
Die Spitzenreiter kommen auf 996 Punkte
Für die Messung fragt die Website alle angebundenen Sprachmodelle mit dem Befehl »Wer ist [Name]?« ab und fordert bis zu zehn beschreibende Ergebnisse samt Konfidenzwert. Der Algorithmus gruppiert ähnliche Antworten und errechnet daraus den sogenannten »Strength Score«. Dieser kombiniert die durchschnittliche Erkennungssicherheit mit der Anzahl der Modelle, die den Namen korrekt zuordnen.
Die Rangliste der Website führt eine Mischung aus historischen Figuren und modernen Stars an. Der Screenshot zeigt die Top 10, die alle einen Score von 996 erreichen. Darunter finden sich Wolfgang Amadeus Mozart, William Shakespeare, Taylor Swift, Steven Spielberg und Lionel Messi.

Quelle: intheweights
Schwächen bei Allerweltsnamen
Das Abfrageverfahren hat jedoch technische Grenzen. Tippfehler bei der Eingabe drücken die Punktzahl sofort nach unten. Auch Personen mit sehr häufigen Namen schneiden bei der Zuordnung systematisch schlechter ab.
Erschwerend kommt hinzu, dass die Sprachmodelle ihre eigene Sicherheit unkalibriert einschätzen. Die angegebenen Konfidenzwerte schwanken daher von Abfrage zu Abfrage. Manchmal erfinden die Modelle auch biografische Details oder nie stattgefundene Ereignisse, was die Auswertung weiter verfälscht.





