
Darum warnt OpenAI jetzt vor dem wichtigsten KI-Benchmark
Falsche Tests und geklaute Daten verzerren die Ergebnisse der besten Sprachmodelle. Die Industrie muss sofort umdenken.

OpenAI stuft den etablierten Programmier-Benchmark SWE-bench Verified offiziell als unbrauchbar für modernste KI-Modelle ein. Aufgrund von fehlerhaften Tests und Datenkontamination liefert die Metrik keine verlässlichen Aussagen mehr über die tatsächlichen Coding-Fähigkeiten der Systeme. Das Unternehmen empfiehlt stattdessen den Wechsel auf den deutlich anspruchsvolleren SWE-bench Pro.
Anzeige
Fehlerhafte Tests verzerren das Bild
Die Abwertung durch OpenAI entzieht dem bisherigen Branchenstandard für KI-Agenten die Grundlage. Bislang verließ sich die Industrie auf SWE-bench Verified, um das autonome Lösen von realen Software-Problemen zu evaluieren.
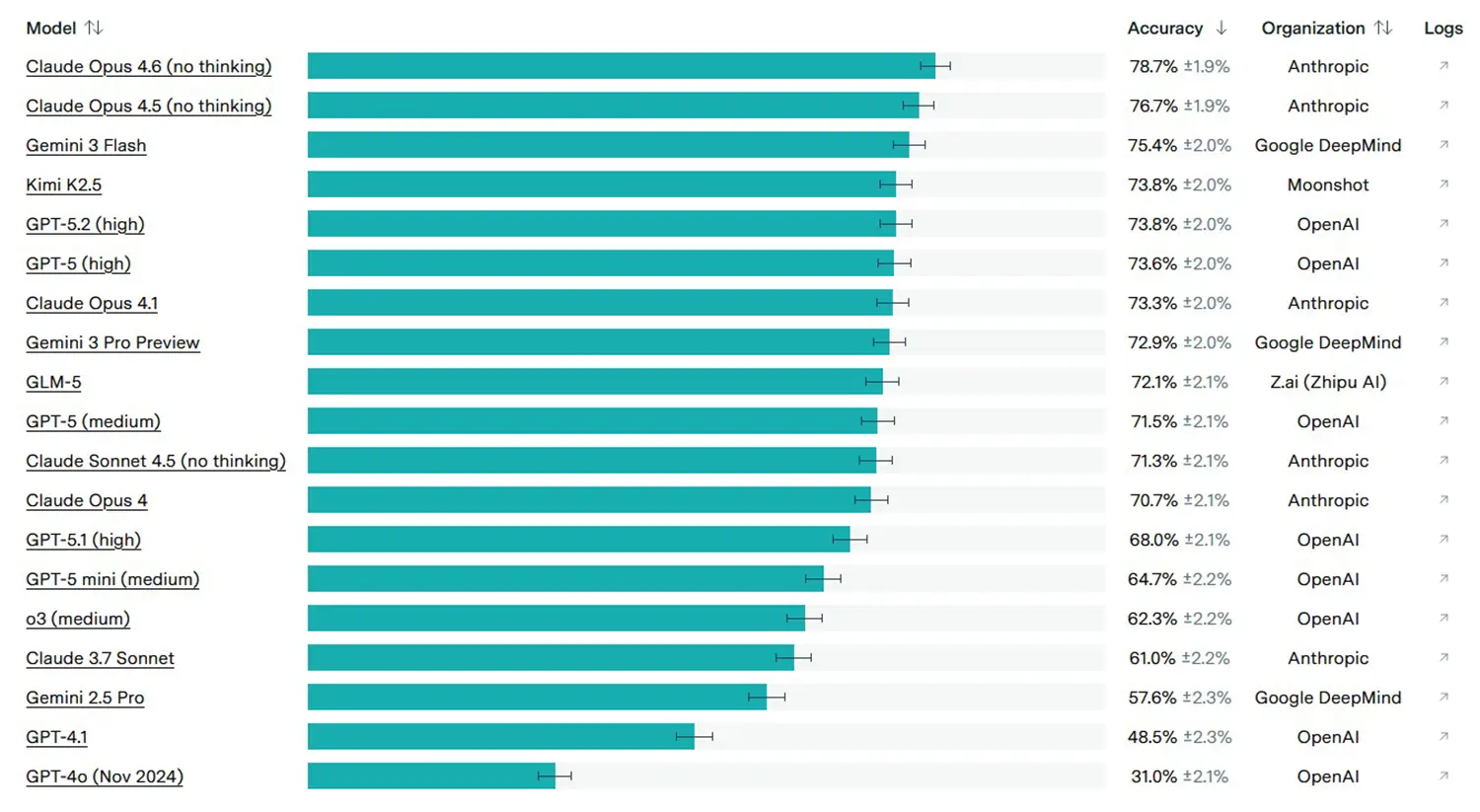
Zuletzt näherten sich Spitzenmodelle wie Claude Opus 4.6 oder GPT-5.2 auf dem Leaderboard einer Genauigkeit von fast 80 Prozent an. Diese scheinbar makellose Erfolgsquote hält jedoch einer genaueren Prüfung nicht stand. Eine gezielte Analyse offenbarte, dass bei knapp 60 Prozent der untersuchten Fehlschläge der generierte Code völlig korrekt funktionierte. Die Einreichungen scheiterten schlicht an schlecht konzipierten Unit-Tests. So wurden funktionierende Lösungen vom System abgelehnt, nur weil das Sprachmodell eine unerwartete API nutzte oder die Prüfroutine bereits im unmodifizierten Originalcode Fehler auswarf.
Zusätzlich entwertet das anhaltende Problem der Datenkontamination die Messergebnisse massiv. Da der Benchmark auf öffentlich zugänglichen Open-Source-Repositories basiert, haben viele Modelle die spezifischen Lösungen bereits während ihrer primären Trainingsphase aufgenommen.
Quelle: epochai
Der Wechsel zu belastbaren Metriken
Um den technischen Fortschritt im Software Engineering wieder realistisch abzubilden, rät OpenAI der Branche nun dringend zur Nutzung von SWE-bench Pro.
Dieser neuere Benchmark verzichtet auf triviale Code-Korrekturen und erfordert stattdessen tiefgreifende, dateiübergreifende Anpassungen in verschiedenen Programmiersprachen wie Go oder TypeScript. KI-Systeme müssen die gesamte Architektur einer Software erfassen, anstatt isolierte Fehler abzuarbeiten.
Ein entscheidender Vorteil der Pro-Variante ist der physische Schutz vor "Training Leakage". Der Benchmark nutzt neben streng lizenziertem Copyleft-Code auch einen privaten Datensatz aus proprietären Codebasen kommerzieller Start-ups, auf die die Sprachmodelle beim Training definitiv keinen Zugriff hatten.
Die massiv erhöhte Schwierigkeit spiegelt sich bereits schonungslos in den aktuellen Auswertungen wider. Modelle, die im alten Verified-Benchmark dominierten, stürzen unter den neuen Bedingungen teilweise drastisch ab. Die Leistungsmessung von KI-Systemen im Programmierbereich orientiert sich damit wieder stärker an der harten Realität der professionellen Softwareentwicklung.