
Microsoft Maia 200 verspricht günstigere KI-Nutzung in der Azure Cloud
Die neue Inferenz-Hardware liefert dreifache Leistung und senkt massiv die Betriebskosten für generative KI-Modelle.

Microsoft präsentiert mit dem Maia 200 einen neuen KI-Beschleuniger, der die Inferenz-Leistung in der Cloud drastisch steigern soll. Dieser Schritt markiert einen entscheidenden Punkt in der technologischen Emanzipation von Nvidia und verspricht effizientere KI-Anwendungen auf der Azure-Plattform.
Fokus auf Effizienz statt reinem Training
Die zweite Generation der hauseigenen Silizium-Architektur zielt spezifisch auf Inferenz-Workloads ab. Während das Training von Modellen immense, rohe Rechenkraft benötigt, entscheidet die Inferenz – also die Anwendung des trainierten Modells – über die laufenden Betriebskosten und die Antwortgeschwindigkeit für Endnutzer. Microsoft optimiert die Architektur hier für die Verarbeitung riesiger Datenmengen in Echtzeit.
Dies ist besonders für generative Dienste wie den Copilot essenziell, wo Millisekunden über die Nutzererfahrung entscheiden. Der Konzern verringert damit weiter seine Abhängigkeit von externen Zulieferern und stärkt die Kontrolle über die eigene Lieferkette. Redmond signalisiert damit deutlich, dass Hardware-Design nun zur Kernkompetenz gehört.
Technische Daten im Vergleich zur Konkurrenz
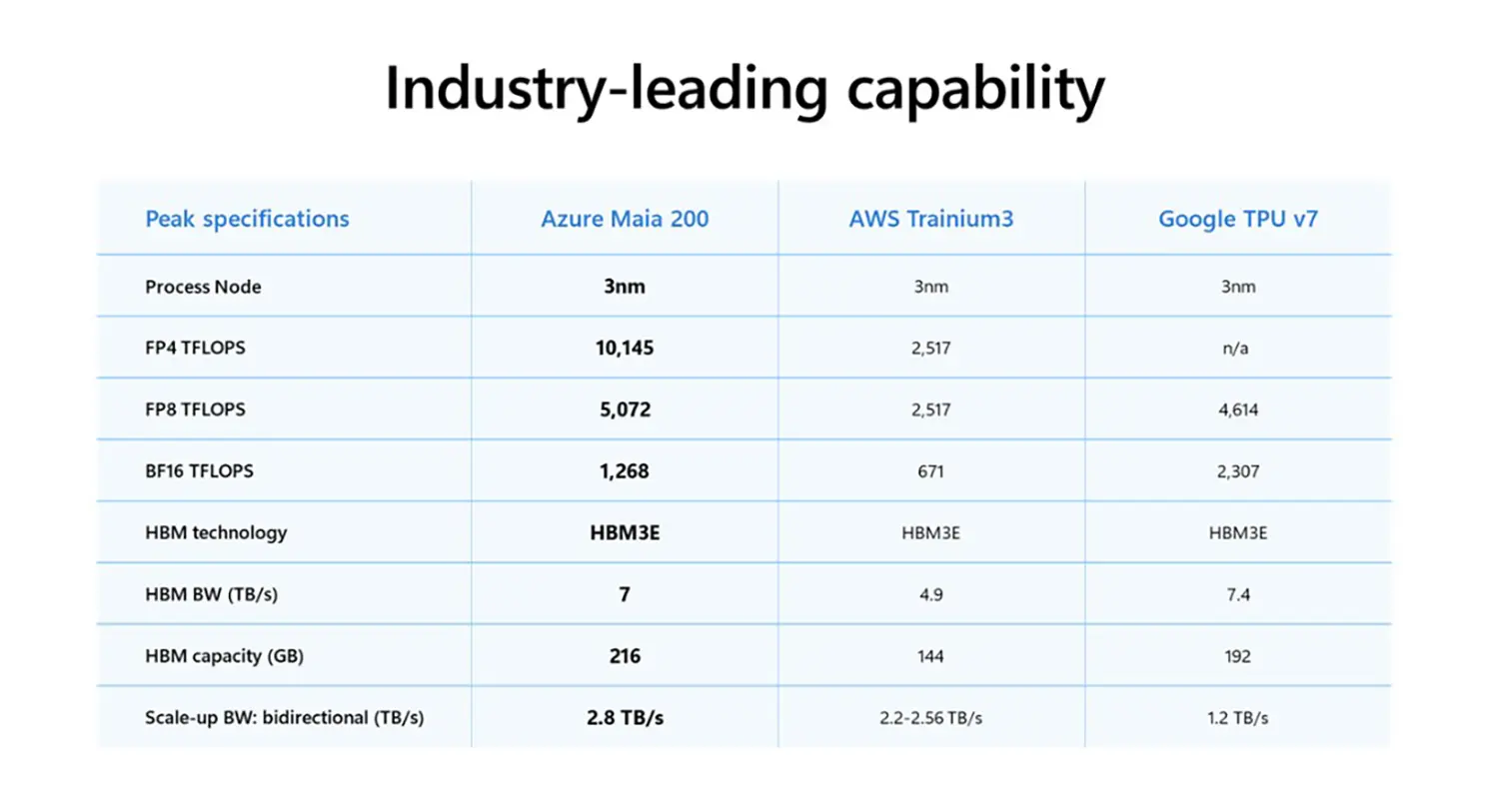
Redmond nimmt mit dem neuen Chip direkt die etablierten Platzhirsche ins Visier. Laut internen Benchmarks übertrifft der Maia 200 die Leistung vergleichbarer Chips von Amazon Web Services (AWS) um das Dreifache. Auch gegenüber Googles TPU v7 soll der Beschleuniger in spezifischen Szenarien Vorteile bieten, insbesondere bei der Verarbeitung komplexer Transformer-Modelle.
Die Architektur des Maia 200 setzt auf eine signifikant erhöhte Speicherbandbreite, um den Datenhunger moderner LLMs (Large Language Models) zu stillen. Microsoft integriert die Hardware tief in den eigenen Software-Stack, was Reibungsverluste minimiert und die Effizienz steigert.
- Fertigung im fortschrittlichen 3-Nanometer-Verfahren.
- Spezialisierte Recheneinheiten für Transformer-basierte Inferenz.
- Integration in Microsofts „Sidekick“-Flüssigkeitskühlungssysteme.
Quelle: Microsoft
Anzeige
Ein Signal an den Markt für Custom-Silicon
Für Azure-Kunden bedeutet die Einführung potenziell sinkende Kosten bei der Nutzung komplexer KI-Modelle, da Microsoft die Margen nicht mehr an Dritthersteller abtreten muss. Die Integration in die Rechenzentren erfolgt über speziell angepasste Server-Racks, die eine höhere Packdichte der Chips ohne thermische Drosselung erlauben.
Der Markt für maßgeschneiderte Chips (Custom-Silicon) wächst rasant. Cloud-Provider investieren Milliarden, um ihre Infrastruktur genau auf ihre Software abzustimmen. Mit dem Maia 200 festigt Microsoft seine Position als Full-Stack-Anbieter und setzt die Konkurrenz unter Zugzwang, ihre eigenen Inferenz-Lösungen schneller zu iterieren.