
Meta TRIBE v2: Neues KI-Modell analysiert Gehirnaktivitäten
Das multimodale System sagt neuronale Reaktionen auf Filme und Sprache präzise voraus.

Meta stellt das KI-Modell TRIBE v2 vor, welches Gehirnaktivitäten basierend auf visuellen und auditiven Reizen vorhersagt. Das multimodale System verarbeitet Sprache sowie Videos und übertrifft bisherige Analysemethoden bei der Auswertung neuronaler Reaktionen deutlich.
Twitter Beitrag - Cookies links unten aktivieren.
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
— AI at Meta (@AIatMeta) March 26, 2026
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people… pic.twitter.com/vRoVj8gP4j
Präzise Vorhersagen neuronaler Muster
Entwickler konzipieren das neue Modell gezielt für In-Silico-Experimente in der modernen Neurowissenschaft. TRIBE v2 simuliert komplexe Zusammenhänge zwischen äußeren Reizen und den resultierenden Mustern im menschlichen Gehirn. Das System verarbeitet dafür Bild-, Ton- und Textdaten in einem gemeinsamen Vektorraum.
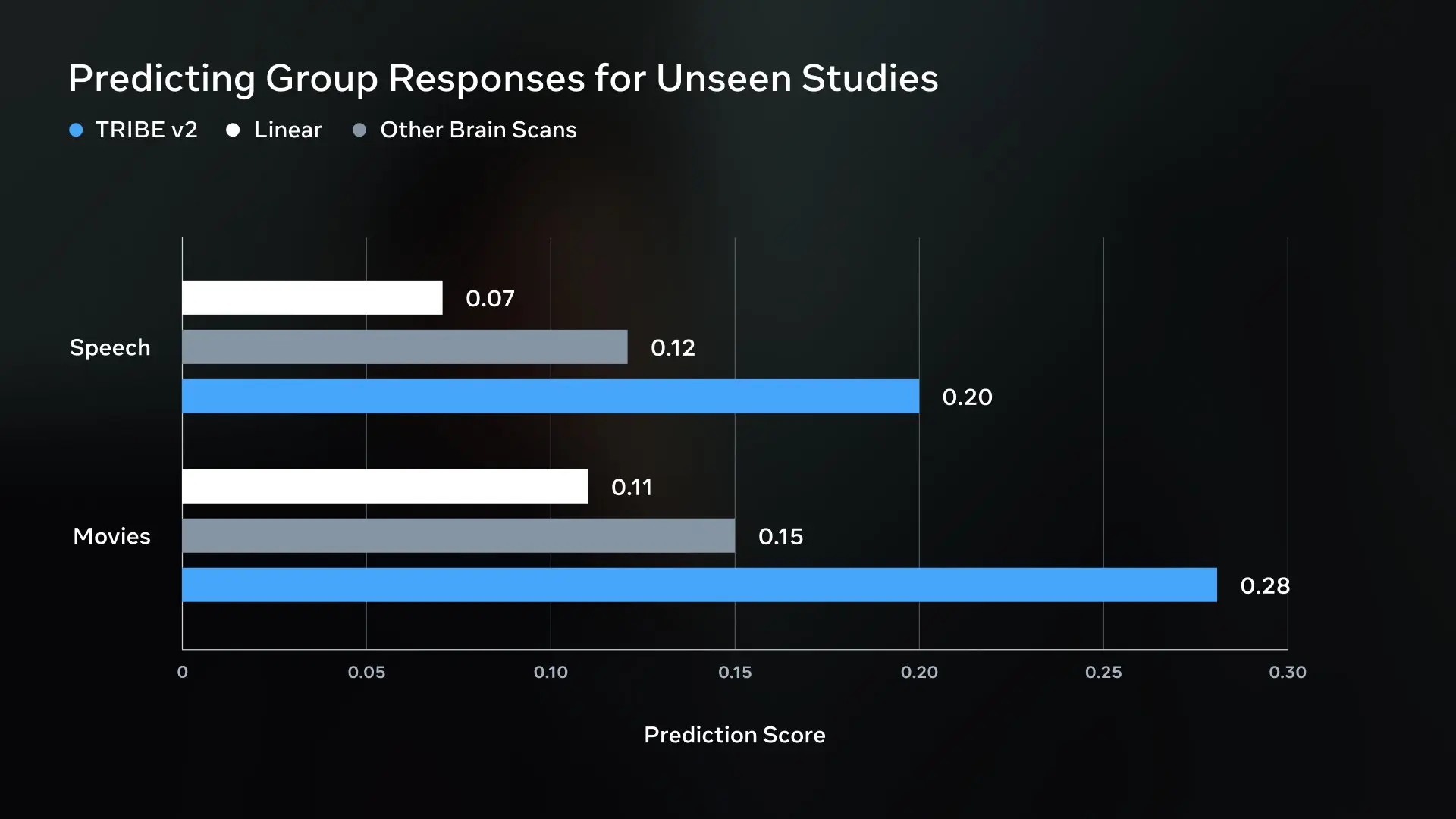
Die veröffentlichten Benchmark-Ergebnisse belegen einen messbaren Vorsprung gegenüber etablierten Analyseverfahren. Bei der Auswertung von gesprochener Sprache erzielt das KI-Modell einen Vorhersagewert von exakt 0,20. Konventionelle Modelle zur Analyse von Gehirnscans erreichen in diesem spezifischen Bereich lediglich einen Score von 0,12. Einfache lineare Ansätze fallen mit einem Wert von 0,07 noch weiter zurück.
Quelle: Meta
Detaillierte Analyse von Videomaterial
Bei der Verarbeitung von Filmen vergrößert sich der gemessene Leistungsabstand deutlich. Wenn Probanden komplexe Bewegtbilder betrachten, prognostiziert TRIBE v2 die neuronalen Reaktionen mit einem Vorhersagewert von 0,28. Konkurrierende Auswertungsmethoden verharren in dieser Disziplin bei einem Wert von 0,15. Der lineare Rechenansatz bildet auch hier mit 0,11 das Schlusslicht.
Diese Leistungsdaten resultieren aus der speziellen multimodalen Architektur der Software. Programmierer trainieren das Foundation-Modell mit umfangreichen Datensätzen aus unterschiedlichen Sinnesbereichen. Dadurch lernt das System, wie kognitive Prozesse auditive und visuelle Informationen verknüpfen. Wissenschaftler erhalten somit eine messbare Methode zur digitalen Untersuchung neurologischer Abläufe.