
Google WAXAL bringt KI-Sprachmodelle nach Afrika
Ein neuer Open-Source-Datensatz liefert die technische Basis für Spracherkennung und künstliche Stimmen in afrikanischen Muttersprachen.

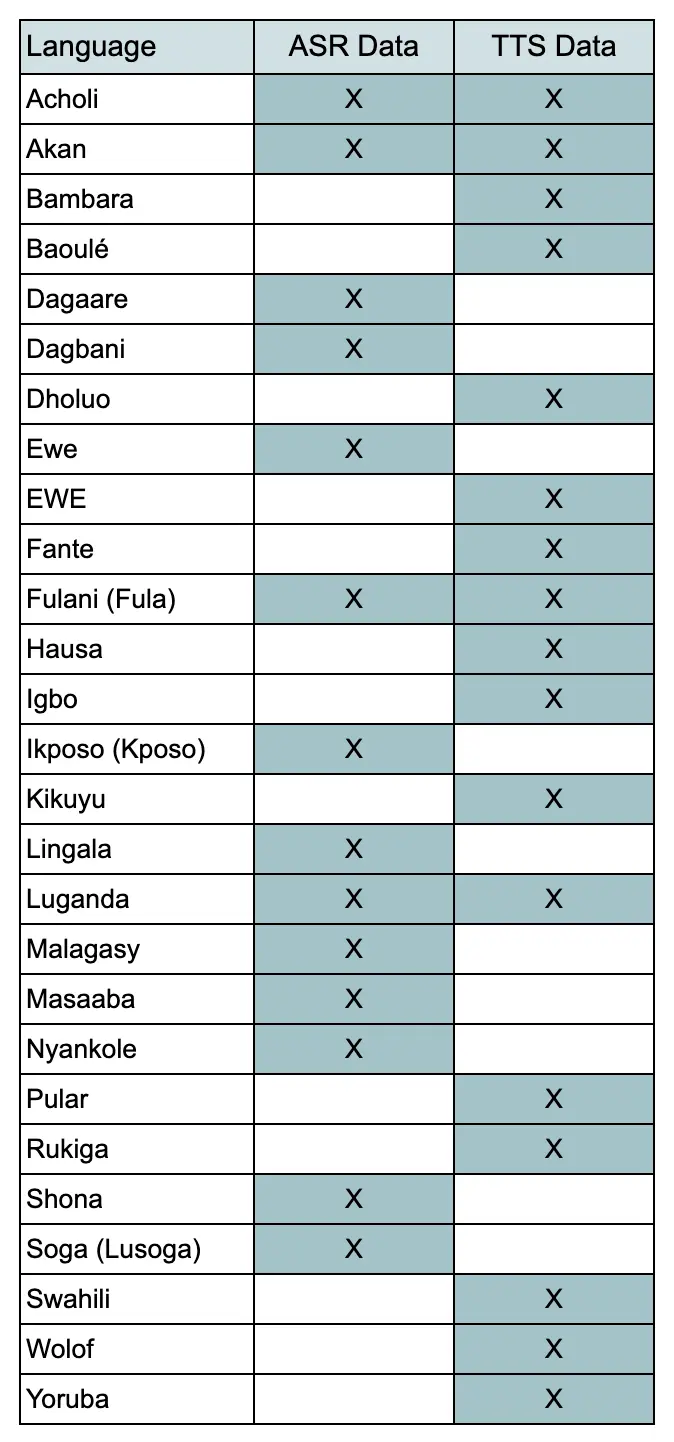
Google hat mit WAXAL einen umfangreichen Open-Source-Datensatz für 27 afrikanische Sprachen veröffentlicht. Das neue Projekt liefert Entwicklern dringend benötigte Trainingsdaten, um leistungsfähige KI-Sprachmodelle für die linguistisch stark vielfältige Region südlich der Sahara zu trainieren.
Quelle: X
Trainingsdaten für unterrepräsentierte Sprachen
Die Entwicklung von Künstlicher Intelligenz konzentrierte sich bisher vorrangig auf dominante Weltsprachen. Für die über 2000 Sprachen auf dem afrikanischen Kontinent fehlen oft die grundlegenden Informationen, um funktionierende Systeme zu bauen. WAXAL bietet der Open-Source-Community nun die nötigen Audio- und Textdaten, um diese technologische Lücke zu verkleinern. Der Name des Projekts stammt aus der Sprache Wolof und bedeutet übersetzt „sprechen“.
Der Datensatz teilt sich in zwei technische Kernbereiche auf. Für die automatische Spracherkennung (ASR) liefert das Paket rund 1250 Stunden transkribierte Audioaufnahmen. Dieser Bereich ermöglicht es einer KI, gesprochene Worte in geschriebenen Text umzuwandeln. Für die Text-to-Speech-Verarbeitung (TTS), also die Erzeugung von künstlichen Stimmen aus Texten, enthält WAXAL zusätzlich fast 100 Gigabyte an hochwertigen Studioaufnahmen.
Entwickler und Forscher können die gesamten Datensätze unter einer offenen CC-BY-4.0-Lizenz kostenfrei nutzen. Das erlaubt sowohl akademische Forschung als auch die Entwicklung von kommerziellen Anwendungen wie lokale Übersetzer oder digitale Sprachassistenten.
Anzeige
Natürliche Sprachmuster durch Bildbeschreibungen
Um eine hohe Qualität der Trainingsdaten zu erreichen, wählte das Projektteam einen speziellen Ansatz bei der Aufnahme der Tonspuren. Die Sprecher lasen keine klassischen, starren Skripte ab. Stattdessen bekamen sie verschiedene Bilder gezeigt und beschrieben diese völlig frei in ihrer jeweiligen Muttersprache.
Dieser Schritt zwingt die Sprecher zum aktiven Formulieren. Die daraus resultierende Sprache enthält natürliche Pausen, Betonungen und einen sehr realistischen Redefluss. KI-Modelle lernen durch diese Art von Daten deutlich besser, echte menschliche Dialoge im Alltag zu verstehen und fehlerfrei zu verarbeiten.
Für die konkrete Umsetzung kooperierte der Technologiekonzern direkt vor Ort mit mehreren afrikanischen Universitäten und Forschungseinrichtungen. Die lokalen Teams übernahmen die direkte Koordination der Aufnahmen und stellten sicher, dass alle sprachlichen Feinheiten präzise erfasst wurden. Die beteiligten Forscher planen bereits, den Datensatz in naher Zukunft um weitere afrikanische Sprachen zu ergänzen. Mit der Zeit wächst so ein stabiles Fundament für regionale Softwarelösungen.