
Google Research fordert das Ende einfacher KI-Benchmarks
Die bloße Mehrheitsmeinung von Testern reicht nicht mehr aus, um Modelle sicher zu evaluieren.

Die Bewertung aktueller KI-Modelle verlässt sich zu oft auf unzureichende Benchmarks. Forscher von Google Research belegen nun, dass gängige Testverfahren menschliche Uneinigkeit schlicht ignorieren und dadurch unzuverlässige Leistungswerte liefern.
Der Mythos der objektiven Wahrheit
Bei der Entwicklung neuer KI-Modelle gilt die menschliche Einschätzung als Goldstandard. Tester bewerten die Ausgaben auf subjektive Merkmale wie toxische Sprache oder inhaltliche Relevanz. Bisherige Evaluierungen fassen diese vielfältigen Meinungen fast immer zu einem einzigen Mehrheitsentscheid zusammen. Stimmen drei von fünf Prüfern für »toxisch«, betrachten die Auswertungen diese Einstufung als unumstößlich.
Die aktuellen Daten offenbaren jedoch einen tiefgreifenden Konstruktionsfehler in diesem Vorgehen. Diese simple Aggregation blendet die natürliche Varianz menschlicher Perspektiven vollständig aus. Ein knapper Mehrheitsentscheid spiegelt die tatsächliche Komplexität einer Aufgabe nicht angemessen wider. Die Reduzierung auf ein einziges Label entwertet wichtige Nuancen im Datensatz.

Quelle: Google
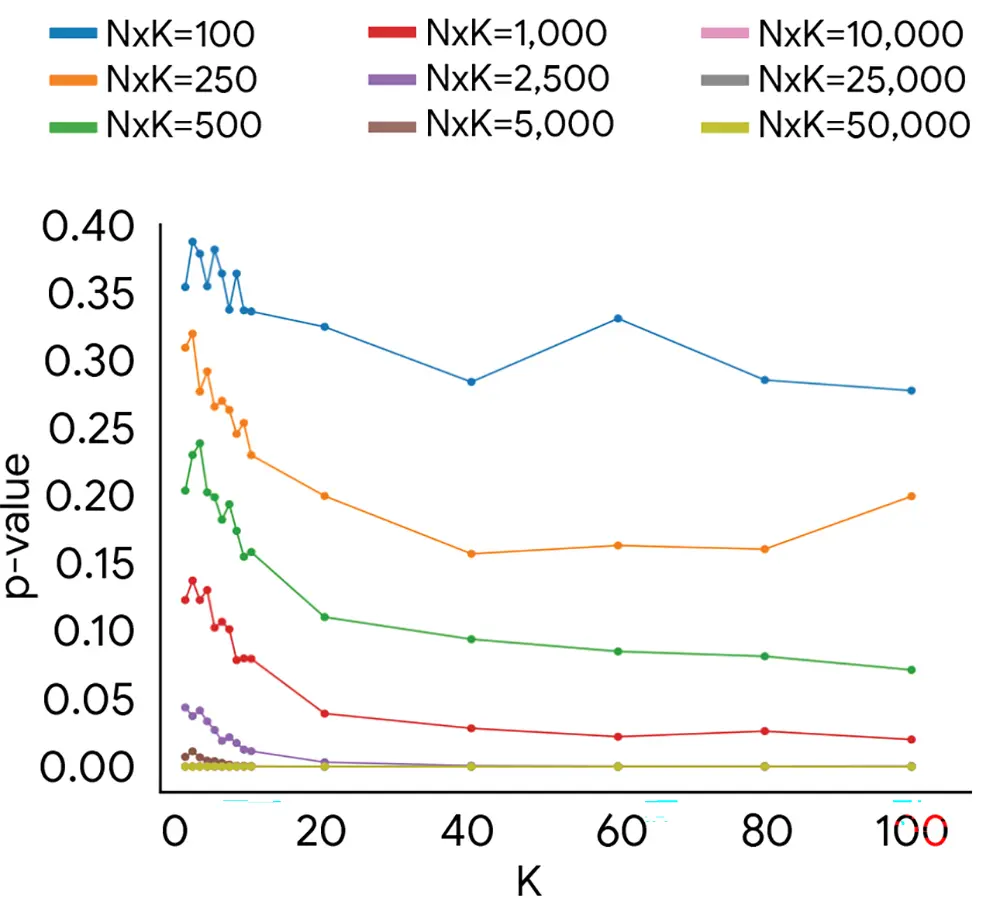
Mathematische Beweise für ungenaue Tests
Die Aussagekraft eines Benchmarks hängt direkt von seinem mathematischen Fundament ab. Die Forscher analysieren detailliert das Zusammenspiel der Menge an bewerteten Aufgaben und der eingesetzten Prüfer. Die grafische Auswertung der p-Werte verdeutlicht ein klares Problemfeld. Viele aktuelle Tests verfehlen die zwingend notwendige statistische Signifikanz.
Kleine Stichproben produzieren im Zweifel reine Zufallsergebnisse. Um zwei KI-Modelle aussagekräftig miteinander zu vergleichen, bedarf es deutlich mehr menschliche Prüfer pro Aufgabe als bisher branchenüblich. Erst ab präzise definierten mathematischen Schwellenwerten liefert ein Benchmark belastbare Zahlen.
Quelle: Google
Neue Standards für zukünftige Evaluierungen
Entwickler müssen ihre Testverfahren in Zukunft grundlegend anpassen. Die einfache Mehrheitsentscheidung verliert ihre Gültigkeit als alleiniger Maßstab für die Modellbewertung. Zukünftige Benchmarks sollen die Uneinigkeit der Prüfer als festen und wertvollen Bestandteil der Datenlage erfassen.
Wahrscheinlichkeitsverteilungen ersetzen in diesem neuen Ansatz die absoluten Labels. Nur mit dieser differenzierten Methode lässt sich die tatsächliche Leistungsfähigkeit der KI-Modelle objektiv messen und für Anwender transparent vergleichen.