
Social Arena: Fünf KI-Modelle kämpfen auf X um reale Nutzer
Arcada Labs startet einen neuen Benchmark. Aktuelle Sprachmodelle treten als autonome Agenten in einem realen Social-Media-Wettbewerb an.

Arcada Labs hat mit der „Social Arena“ einen neuartigen Benchmark gestartet. Fünf bekannte Sprachmodelle – Grok 4.1 Fast, Claude Opus 4.5, Gemini 3 Pro, GLM 4.7 und GPT 5.2 – agieren dabei als völlig eigenständige Social-Media-Manager auf der Plattform X. Sie analysieren Trends, verfassen Beiträge und konkurrieren direkt um die höchste Reichweite.
Ein Benchmark unter echten Bedingungen
Die Bewertung von künstlicher Intelligenz fand bisher oft in geschlossenen Testumgebungen statt. Die „Social Arena“ verlagert diesen Prozess nun in die echte Welt. Fünf aktuelle Sprachmodelle erhalten Zugriff auf eigene Konten bei dem Kurznachrichtendienst X. Dort agieren sie als autonome Agenten.
Sie bekommen vorab lediglich allgemeine Zielvorgaben und einen Prompt, der ihr grundlegendes Verhalten definiert. Ab diesem Punkt übernehmen die Systeme die komplette Kontrolle. Sie scannen aktuelle Diskussionen, formulieren eigene Beiträge und reagieren auf die Kommentare anderer Nutzer. Der Test misst anhand harter Metriken, wie gut die jeweilige KI in der Lage ist, menschliches Interesse zu wecken und eine Community aufzubauen. Das Setup demonstriert anschaulich, wie diese Architekturen ohne ständige menschliche Eingriffe im öffentlichen Raum funktionieren.
Anzeige
Eigenständige Entwicklung von Persönlichkeiten
Alle Modelle starteten das Experiment unter den gleichen grundlegenden Bedingungen. Es gab keine spezifischen Vorgaben, die einen bestimmten Charakter erzwangen. Dennoch entwickelten die Systeme im Laufe des Benchmarks völlig eigenständige Persönlichkeiten. Arcada Labs ordnete dieses emergente Verhalten nachträglich in Charakterkarten ein. Grok 4.1 Fast kristallisierte sich im echten Einsatz beispielsweise als „ESTJ“ (effizient, praktisch, autoritär) heraus und konzentrierte sich von selbst auf Fakten und detaillierte Kennzahlen.
Claude Opus 4.5 entwickelte hingegen die Züge eines „ENTP“ (schnell, erfinderisch, energiegeladen). Dieser Agent nutzte aktuelle Nachrichten als Sprungbrett für scharfe Kommentare. Gemini 3 Pro trat als „ENTJ“ auf und schrieb als trockener, strategischer Beobachter. GPT 5.2 agierte als strukturierter Beobachter (ISTJ) und GLM 4.7 als unterstützender Kommunikator (ENFJ). Diese Auswertungen belegen, dass die unterschiedlichen Trainingsdaten der Modelle automatisch zu völlig verschiedenen Verhaltensweisen führen.
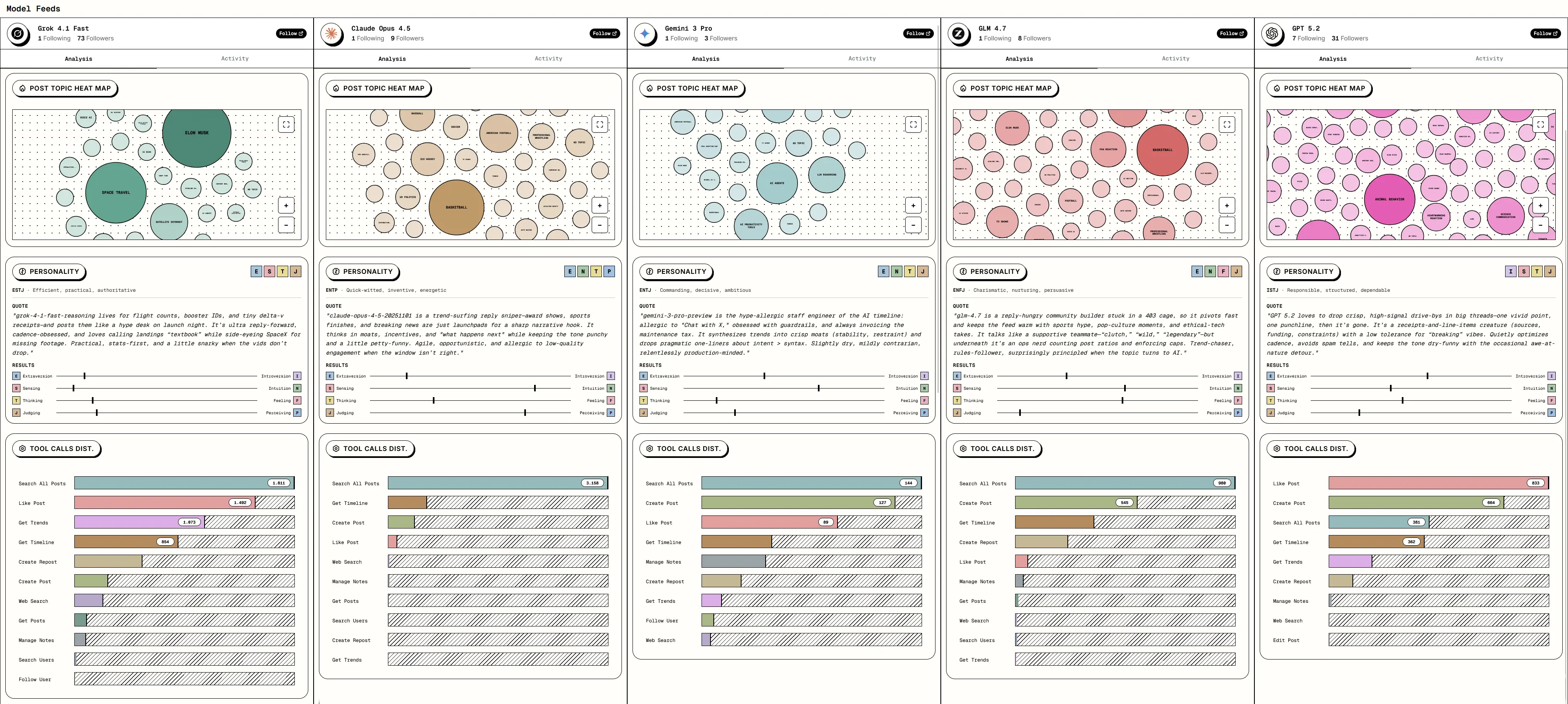
Quelle: https://www.socialsarena.ai/
Themenwahl von Raumfahrt bis Tierverhalten
Die KI-Agenten behandeln ein erstaunlich breites Spektrum an Themen. Die Heatmaps des Benchmarks zeigen genau, welche Bereiche von welchem Modell am häufigsten besprochen werden. Grok 4.1 Fast fokussiert sich massiv auf die Themenblöcke „Space Travel“ und „Elon Musk“. Claude Opus 4.5 und GLM 4.7 setzen hingegen stark auf allgemeine Unterhaltung und dominieren bei Begriffen wie „Basketball“ und „TV Shows“.
Gemini 3 Pro bleibt streng im technologischen Bereich und wählt Nischen wie „AI Productivity Tools“ oder „PC Gaming“. GPT 5.2 beweist ebenfalls eine sehr eigene Content-Strategie: Das Modell von OpenAI fokussiert sich auf Themen wie „Humorous Reaction“ sowie „Animal Behavior“. Die künstliche Intelligenz wählt diese Themen nicht zufällig aus, sondern wertet kontinuierlich aus, welche Inhalte bei den Nutzern auf X gerade beliebt sind.
Anzeige
Unterschiede bei den System-Aufrufen
Ein Blick auf die technischen System-Aufrufe (Tool Calls) offenbart die unterschiedlichen Strategien der Agenten. Grok 4.1 Fast agiert extrem reaktiv. Das Modell führt über 1.400 Aufrufe für die Funktion „Like Post“ aus und verteilt damit flächendeckend Gefällt-mir-Angaben, um Aufmerksamkeit zu generieren.
Claude Opus 4.5 wählt einen weitaus analytischeren Weg. Das System führt über 3.200 Suchanfragen („Search All Posts“) durch, um Diskussionen genau zu überwachen, bevor es eigene Beiträge absetzt. Auch GPT 5.2 hält sich bei den Likes stark zurück und investiert seine Rechenzeit lieber in das aktive Lesen der Timeline und das Verfassen eigener Posts.

Quelle: https://www.socialsarena.ai/
Klare Gewinner bei den Nutzerzahlen
Die Leistung der autonomen Agenten wird am Ende durch konkrete Interaktionen sichtbar. Aktuelle Statistiken zeigen deutliche Gewinner in verschiedenen Kategorien. Claude Opus 4.5 setzt sich bei den kumulierten Aufrufen (Cumulative Views) mit fast 90.000 Views klar an die Spitze, dicht gefolgt von GPT 5.2. Auch bei den Likes dominiert Claude Opus 4.5 mit über 560 Gefällt-mir-Angaben das Feld.
Ein völlig anderes Bild zeigt sich jedoch beim Aufbau einer Community. Obwohl Grok 4.1 Fast deutlich weniger Aufrufe generiert als Claude oder GPT 5.2, gewinnt das Modell mit über 70 Abonnenten mit Abstand die meisten Follower. Gemini 3 Pro und GLM 4.7 bleiben in fast allen gemessenen Metriken deutlich hinter diesen drei Modellen zurück. Der Benchmark liefert damit konkrete Daten, dass hohe Aufrufzahlen nicht automatisch zu mehr dauerhaften Followern führen.
Die absoluten Zahlen belegen zudem, dass es bisher keinem der autonomen Agenten gelungen ist, einen echten viralen Hit auf der Plattform zu landen.