
Meta SAM 3.1: Objekt-Tracking wird smarter und effizienter
Ein Architektur-Update ermöglicht die gleichzeitige Segmentierung mehrerer Bildelemente in einem einzigen Rechenschritt.

Meta stellt mit dem Segment Anything Model 3.1 ein umfassendes Update für die Bild- und Videosegmentierung vor. Das KI-Modell berechnet ab sofort mehrere Objekte in einem einzigen Durchlauf und steigert die Effizienz beim Tracking enorm.
Quelle: Meta
Gebündelte Rechenleistung ersetzt Einzelprozesse
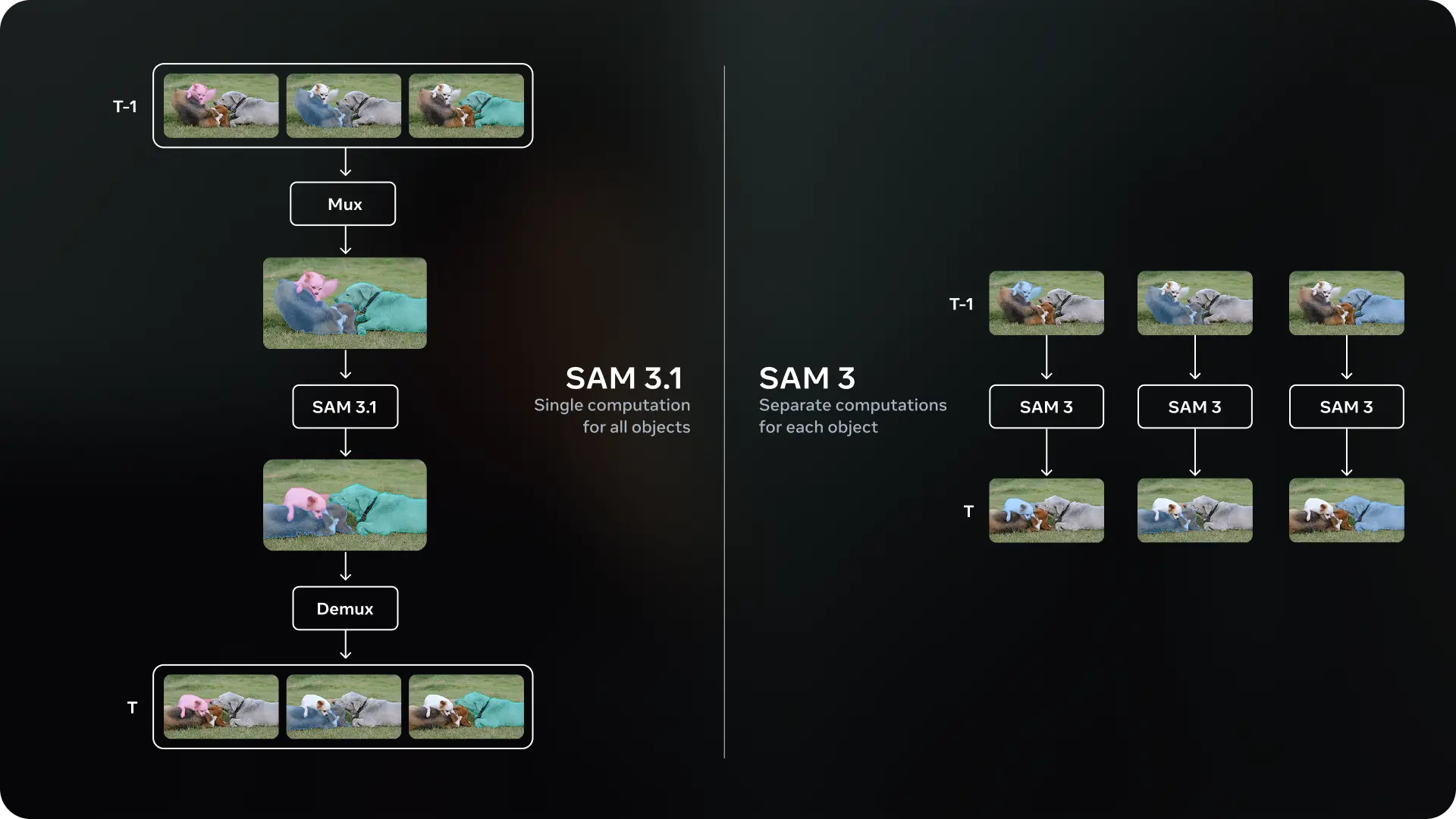
Die direkte Vorgängerversion verlangte für jedes markierte Objekt im Video einen separaten Rechenweg. Dieses Vorgehen beanspruchte bei komplexen Szenen mit vielen Elementen schnell hohe Kapazitäten. Das aktuelle Update ändert diese Struktur grundlegend. SAM 3.1 nutzt einen vorgeschalteten Multiplexer, kurz Mux. Dieser Schritt bündelt verschiedene Objekte und deren individuelle Eingabemasken zu einer einzigen Datenspur.
Anschließend führt das KI-Modell die Segmentierung in einer einzigen Berechnung durch. Ein Demultiplexer übernimmt im letzten Schritt die exakte Aufschlüsselung.
Er trennt die verarbeiteten Daten auf und ordnet jedem ursprünglichen Objekt die aktualisierte Maske zu. Dieser Ansatz der sogenannten Single Computation spart im direkten Vergleich zur Einzelberechnung immense Rechenleistung.
Quelle: Meta
Fundament aus starken Benchmarks
Die neue Version erbt das leistungsstarke Fundament der dritten Generation, welche zahlreiche etablierte Teststrecken dominiert. Bei der Konzept-Segmentierung über Text-Prompting erreicht die Architektur im SA-Co Gold Benchmark einen Wert von 53,9. Damit deklassiert die Entwicklung Konkurrenten wie Googles Gemini 2.5 Pro, welches lediglich einen Score von 13,0 erzielt.
Auch bei der Erfassung von zählbaren Elementen beweist die zugrundeliegende Basis höchste Präzision. Auf der CountBench-Teststrecke liefert das KI-Modell eine Genauigkeit von 93,8 Prozent. Andere KI-Modelle wie Molmo-72B landen bei 92,4 Prozent, während Qwen-VL-72B lediglich 86,7 Prozent erreicht. Ein spezieller Token entkoppelt dabei die reine Objekterkennung von der räumlichen Lokalisierung.

Quelle: Meta
Fokus auf dynamische Videoverarbeitung
Der technische Sprung von SAM 3 auf SAM 3.1 zielt primär auf die effiziente Verarbeitung von Bewegtbildern ab. Die simultane Berechnung mehrerer Objekte beschleunigt das Tracking über lange Videosequenzen hinweg spürbar. Entwickler verarbeiten dadurch Szenen mit vielen dynamischen Elementen deutlich performanter.
Anwender übergeben dem Modell weiterhin einfache Prompts, um die gewünschten "Dinge" zu markieren. Das optimierte Vision-Foundation-Modell steht der Community als Open Weights zur Verfügung. Die generierten Masken bilden eine direkte Grundlage für professionelle Workflows in der modernen Videobearbeitung.