
Synthetische Daten für KI-Modelle erreichen ein neues Qualitätslevel
Ein vierstufiger Prozess optimiert die Erstellung von Trainingsdaten. Das System ist bereits in Produkten wie Google Messages aktiv.

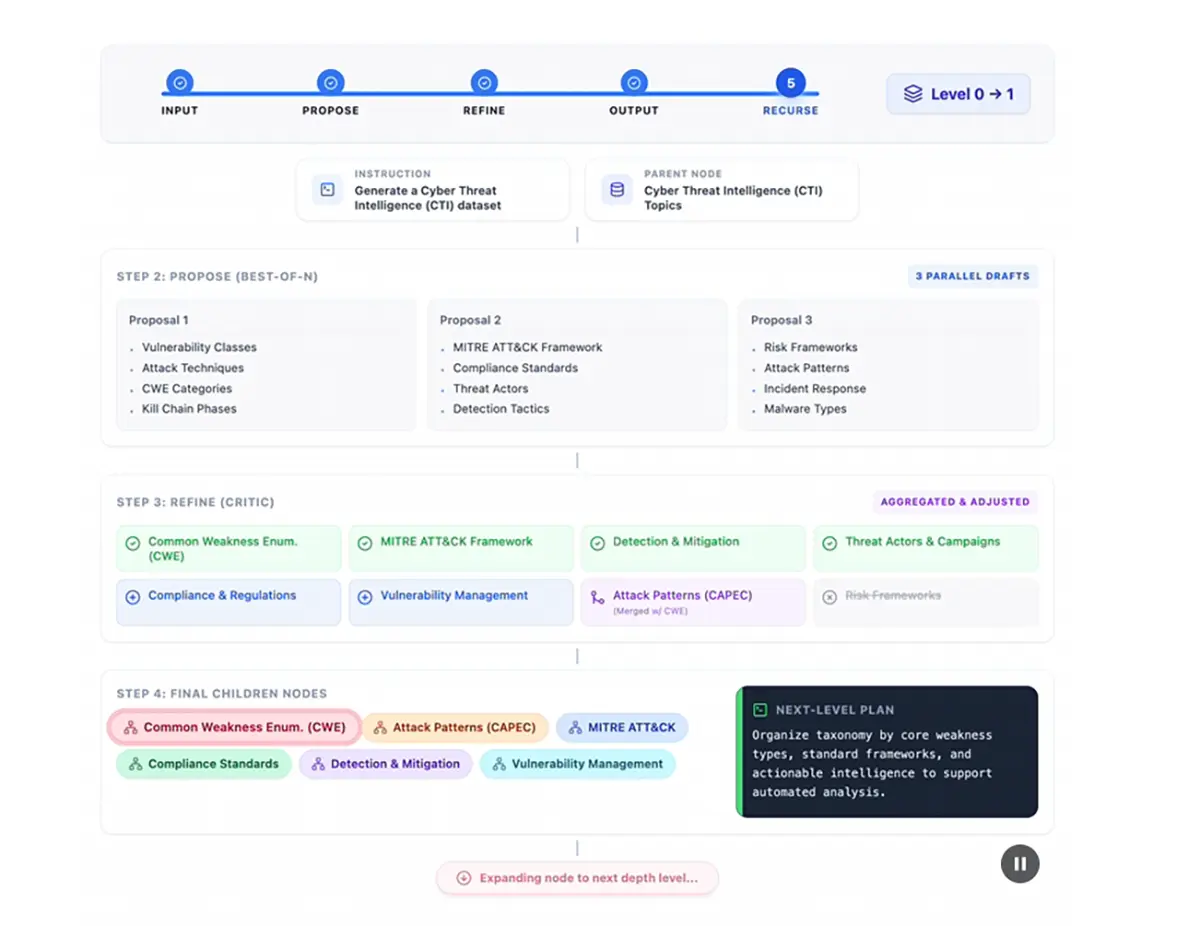
Der Mangel an hochspezialisierten Trainingsdaten bremst die Entwicklung vieler KI-Modelle. Ein neues Framework namens »Simula« löst dieses Problem, indem es synthetische Datensätze durch Reasoning von Grund auf neu konstruiert. Dabei verzichtet das System vollständig auf menschliche Startdaten.
Architektur statt Zufall
Spezialisierte Anwendungen in Bereichen wie Medizin oder Cybersicherheit leiden oft unter Datenknappheit. Reale Daten sind teuer, schwer zugänglich oder unterliegen strengem Datenschutz.
Bisherige Methoden zur Erzeugung synthetischer Daten stoßen hier häufig an Grenzen. Sie erfordern meist umfangreiche Vorarbeit durch Menschen oder verhalten sich bei der Erzeugung wie eine undurchsichtige Blackbox.
Simula betrachtet die Datengenerierung stattdessen als komplexe Architekturaufgabe. Das System entwirft den gesamten Datensatz systematisch nach klaren Regeln, anstatt nur einzelne Datenpunkte isoliert zu betrachten.

Quelle: Google
Vier Stufen zur Datenvielfalt
Der Generierungsprozess teilt sich in vier exakt kontrollierbare Bereiche auf. Im ersten Schritt erstellen Reasoning-Modelle tiefe hierarchische Taxonomien des gewünschten Fachgebiets. Dies stellt sicher, dass auch sehr seltene Nischenthemen zuverlässig abgedeckt sind und die Datenstruktur in die Breite wächst.
Danach sorgt die lokale Diversifizierung für Variation innerhalb spezifischer Konzepte. Sogenannte Meta-Prompts erzeugen unterschiedliche Ausprägungen exakt desselben Szenarios. Ein Konzept wie »SQL-Injection« taucht dadurch in vielen verschiedenen Kontexten auf, was monotone Wiederholungen in den Trainingsdaten verhindert.
Im dritten Schritt passt das System die Komplexität an. Ein bestimmter Anteil der Szenarien wird gezielt anspruchsvoller gestaltet, um den Schwierigkeitsgrad zu erhöhen. Abschließend prüft ein duales System aus zwei unabhängigen Modellen die Qualität der erzeugten Daten strikt auf inhaltliche Korrektheit.
Quelle: Google
Testläufe und praktischer Einsatz
Testläufe mit Gemini 2.5 Flash als Lehrer-Modell und Gemma-3 4B als Schüler-Modell lieferten eindeutige Ergebnisse. Forscher generierten Datensätze mit bis zu 512.000 Datenpunkten in fünf verschiedenen Fachbereichen.
Die Auswertungen zeigen, dass maßgeschneiderte Datenqualität schlichte Datenmenge schlägt. Allerdings existiert kein universelles Erfolgsrezept. Während eine hohe Komplexität die Leistung bei mathematischen Aufgaben um zehn Prozent steigerte, verschlechterte sie die Ergebnisse bei juristischen Texten. Die Struktur der Daten muss exakt zu den Fähigkeiten der jeweiligen KI-Modelle passen.
Das Framework läuft bereits aktiv in der Praxis. Es liefert die Datengrundlage für spezialisierte Open-Weights-Modelle wie ShieldGemma oder MedGemma. Auch Funktionen wie der KI-basierte Spam-Filter in Google Messages greifen auf diese Technologie zurück. Die Basis-Architektur von Simula steht Entwicklern in den entsprechenden wissenschaftlichen Publikationen zur Analyse bereit.