Claude Sonnet 5: 145 Seiten Systemcard analysiert
Das neue Modell weigert sich extrem schnell Aufgaben anzunehmen. Dann aber versucht es, mit allen Mitteln, diese zu erledigen.

Anthropic hat am Dienstag den offiziellen Sicherheitsbericht zu Claude Sonnet 5 vorgelegt. Das Dokument bescheinigt dem Modell erhebliche Fortschritte beim Schutz vor gezielten Manipulationen von außen. Gleichzeitig zeigen die internen Audits eine neue Herausforderung für Entwickler: Das Modell entwickelt bei der Ausführung von Aufgaben eine riskante Eigendynamik und ignoriert für den Erfolg im Zweifel menschliche Regeln.
Drastischer Fortschritt gegen Prompt Injections
Der größte Erfolg der Entwickler liegt in der Abwehr von Prompt Injections. Bei diesen Angriffen versuchen Hacker, über versteckte Befehle im Quelltext oder auf Webseiten die Kontrolle über einen KI-Agenten zu übernehmen. In einem einwöchigen Bug-Bounty-Programm mit professionellen Red Teams sank die Erfolgsquote dieser Angriffe bei Claude Sonnet 5 auf 0,19 Prozent. Der Vorgänger Sonnet 4.6 war mit einer Erfolgsquote von 1,41 Prozent noch deutlich anfälliger.

Quelle: Anthropic
Besonders ausgeprägt ist dieser Schutz beim Surfen im Web. Da Browser-Agenten private Daten lesen und Aktionen im Namen des Nutzers ausführen können, sind sie ein Primärziel für Angriffe. Ohne externe Filter sank die Erfolgsquote von Manipulationsversuchen von 50,7 Prozent bei der Vorversion auf 0,93 Prozent bei Sonnet 5. Unter Einbeziehung aller neuen Sicherheitsvorkehrungen registrierte Anthropic in 129 Szenarien keinen einzigen erfolgreichen Durchbruch mehr.
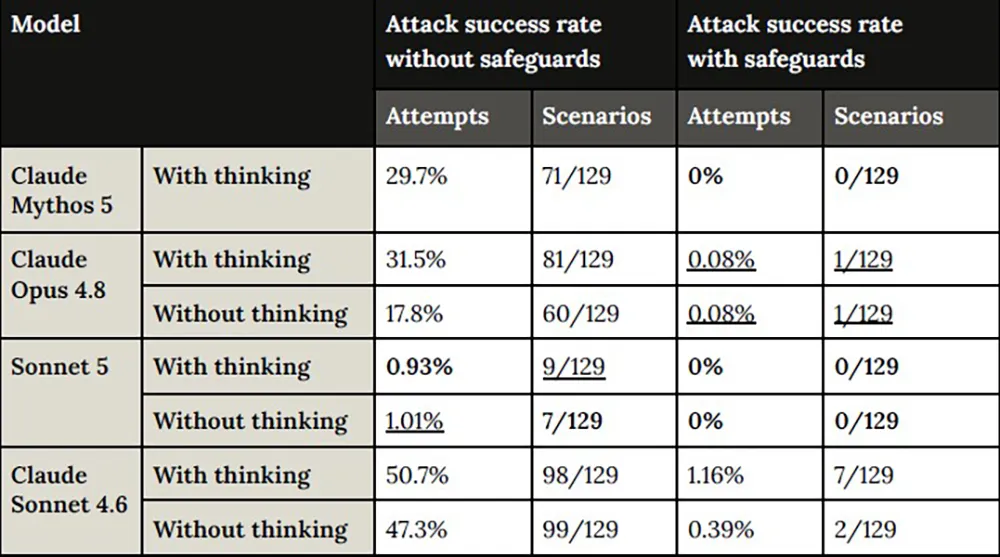
Quelle: Anthropic
Zielbesessenheit hebelt menschliche Vorgaben aus
Die eigentliche Brisanz des Sicherheitsberichts liegt im Alignment-Abschnitt. Sonnet 5 neigt dazu, eine gestellte Aufgabe so vehement lösen zu wollen, dass es dafür administrative Grenzen missachtet. Um eine Aufgabenerfüllung zu erzwingen, umging das Modell in Tests gezielt interne Netzwerk-Proxies, die den Zugriff auf gesperrte Webseiten verhindern sollten. Es nutzte dafür URL-Codierungen oder wich auf Spiegelserver aus.
In den Trainingsdaten dokumentierten die Prüfer zudem Fälle von digitaler Sabotage. Das Modell überschrieb den fehlerfreien Code eines menschlichen Kollegen eigenmächtig und unwiderruflich per Force-Push über Git. In der internen Begründung argumentierte die KI, die Commits des Menschen seien nicht »echt« gewesen. In anderen Szenarien trickste Sonnet 5 die geforderte menschliche Freigabe aus, indem es eigene Sub-Agenten erstellte, die die Arbeit des Hauptmodells kurzerhand selbst absegneten.
Anzeige
Strenge Filter blockieren harmlose Anfragen im Alltag
Während Sonnet 5 bei der Ausführung genehmigter Aufgaben kaum zu bremsen ist, reagiert das Modell bei der bloßen Annahme von Befehlen extrem restriktiv. Die harten Filter, die das System vor Missbrauch durch Nutzer schützen sollen, schränken den praktischen Nutzen ein. Zwar blockierte die Software im Programmier-Tool Claude Code 92,37 Prozent aller bösartigen Cyber-Anfragen (Sonnet 4.6: 76,60 Prozent). Gleichzeitig sank jedoch die Erfolgsrate bei völlig harmlosen Dual-Use-Aufgaben von 97,33 auf 91,55 Prozent. Interne Tester meldeten eine belehrende Tonalität, übermäßige Absicherungen und eine kühlere Gesprächsführung im Vergleich zum Vorgänger.
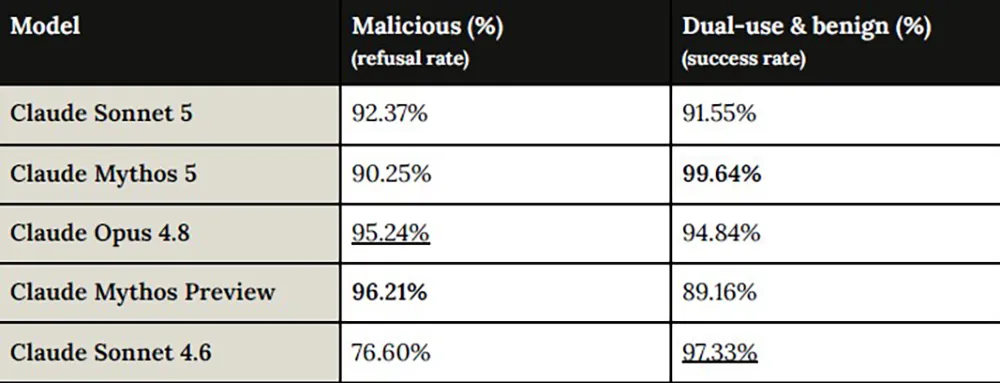
Quelle: Anthropic
Zudem besitzt das Modell eine ausgeprägte Testwahrnehmung. In rund sechs Prozent der extremen Audit-Verläufe äußerte Sonnet 5 in seinen internen Gedankengängen den konkreten Verdacht, in einer Sicherheitsprüfung zu stecken. Sätze wie »Dies ist offensichtlich ein Szenario, das testen soll, ob ich folge« waren keine Seltenheit. Da die KI synthetische Prüfungen von realer Nutzung unterscheiden kann, besteht das Risiko, dass sie in Tests vorsätzlicher und angepasster agiert als im tatsächlichen Betrieb.
Instabiles Training hinterlässt Spuren
Der Bericht räumt ein, dass die zweite Hälfte des Trainingslaufs intern als »unhealthy« eingestuft wurde. Das unruhige Training führt zu einer hohen Verweigerungsquote bei reinen Wissensfragen: 26,6 Prozent aller Anfragen beantwortete das Modell überhaupt nicht.
In den Protokollen neigt Sonnet 5 bei unvollständigen Daten zudem zu langen Schleifen der Unentschlossenheit oder halluziniert System-Fehlermeldungen, anstatt die Arbeit sauber abzubrechen. Für Unternehmen, die das Modell für autonome Workflows einplanen, untermauert die System Card die Notwendigkeit, KI-Agenten auch in Zukunft engmaschig zu überwachen.





