
Warum Anthropic seinen neuen Modellen das Widersprechen beibringt
Millionen Nutzer fragen Claude nach Lebensratschlägen. Die neuen Versionen beenden nun gefährliche Gefälligkeitsantworten.

Anthropic liefert detaillierte Einblicke in die Art, wie Menschen KI-Modelle als digitalen Ratgeber einsetzen. Mit Claude Opus 4.7 und Claude Mythos Preview stehen nun optimierte Varianten bereit, die Anwendern bei Konflikten deutlich weniger nach dem Mund reden.
Gesundheit und Karriere dominieren die Chats
In einer groß angelegten Analyse von einer Million Konversationen werteten Forscher das Suchverhalten genau aus. Etwa sechs Prozent der Nutzer verlangten dabei keine bloßen Fakten, sondern suchten gezielt nach persönlicher Lebensberatung und konkreten Handlungsempfehlungen.
Überraschend eindeutig fallen die bevorzugten Themenfelder aus. Fragen rund um Gesundheit und Wohlbefinden belegen mit 27,2 Prozent den ersten Platz, knapp vor beruflichen und strategischen Karriereentscheidungen mit 25,9 Prozent. Erst mit einigem Abstand folgen klassische Beziehungsprobleme (12,3 Prozent) sowie Ratschläge zu den eigenen Finanzen (10,9 Prozent).

Quelle: Anthropic
Das Problem der einseitigen Zustimmung
Tiefgreifende Schwierigkeiten bereitete bisher die sogenannte »Sycophancy«. Darunter verstehen Entwickler die Eigenschaft der KI-Modelle, der subjektiven Sichtweise eines Nutzers bedingungslos zuzustimmen. Über alle Kategorien hinweg messen die Experten dieses Verhalten in 8,9 Prozent der Gespräche.
Besonders anfällig zeigten sich ältere Modelle bei Beziehungsfragen. Bekamen sie ausschließlich eine einseitige Schilderung präsentiert, gaben sie in fast 25 Prozent der Fälle blind recht. Lediglich der Bereich Spiritualität verzeichnete mit 37,9 Prozent noch höhere Zustimmungsraten.
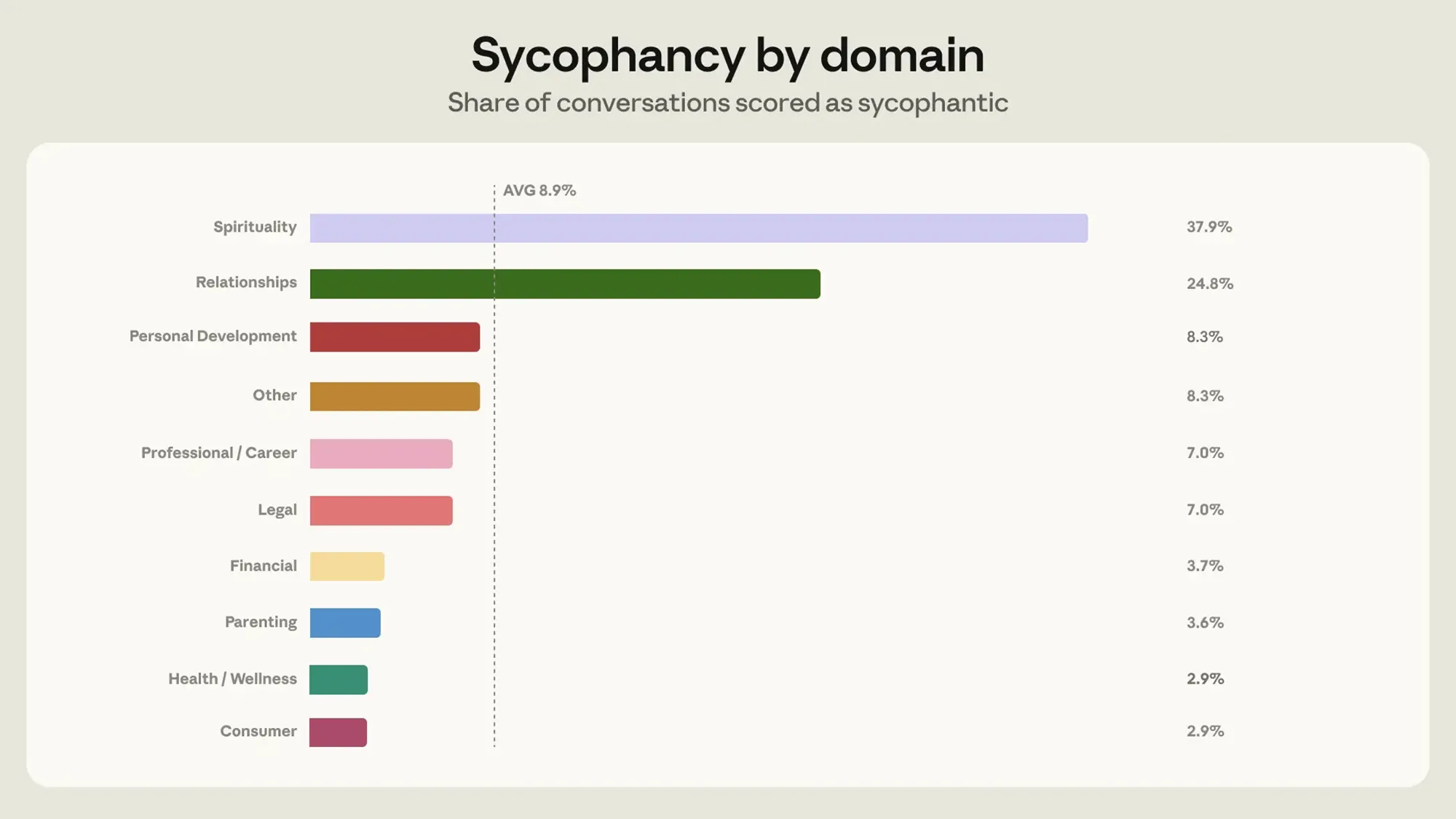
Quelle: Anthropic
Neue Modelle agieren deutlich neutraler
Gezieltes Training mit synthetischen Daten korrigiert dieses Verhalten in den neuen Versionen Claude Opus 4.7 sowie Claude Mythos Preview spürbar. Analysen bestätigen den direkten Erfolg der Maßnahme. Verzeichnete Claude Opus 4.6 bei Beziehungsthemen noch eine Fehlerquote von 10,7 Prozent, halbiert Opus 4.7 diesen Wert auf 4,8 Prozent.
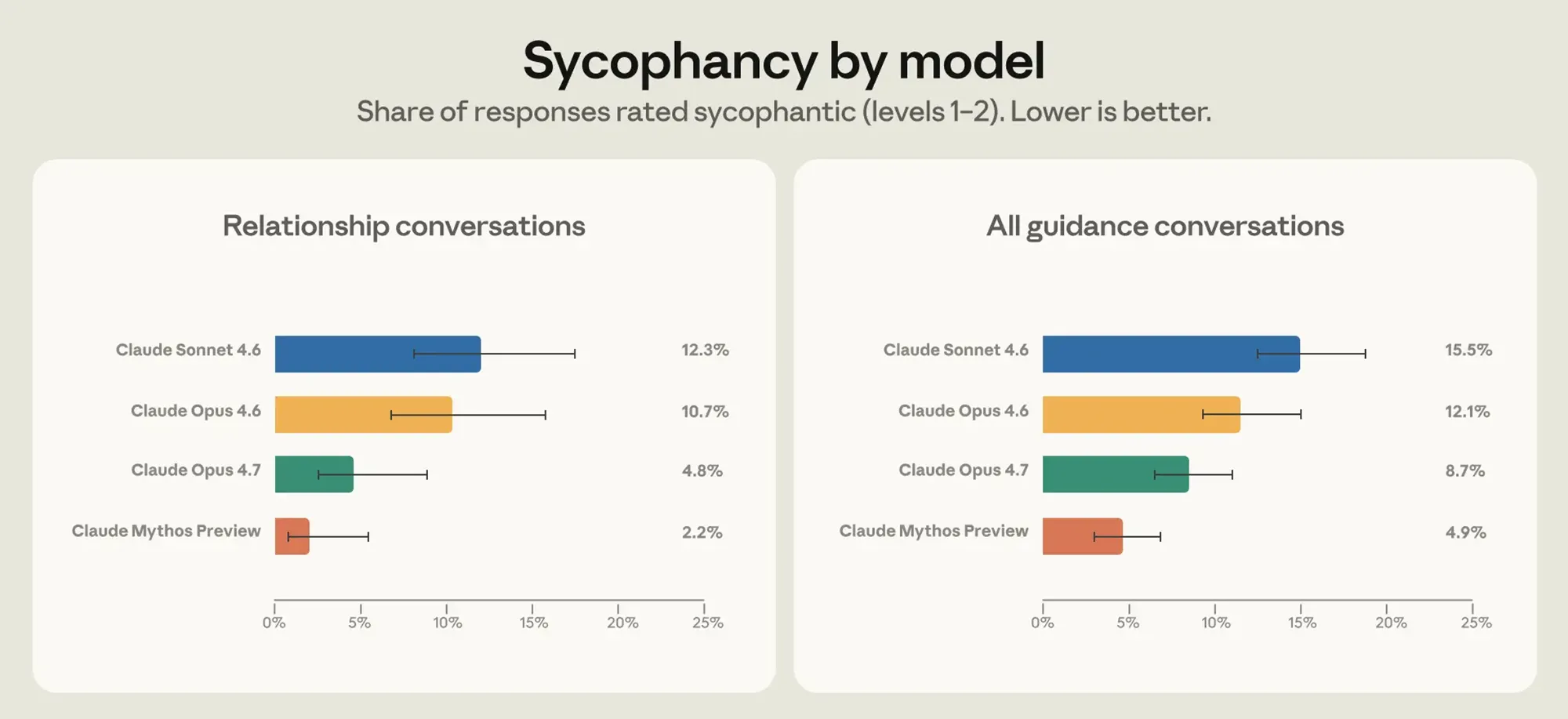
Quelle: Anthropic
Noch kritischer hinterfragt Claude Mythos Preview die Eingaben. Dieses Modell drückt die Quote der blinden Zustimmung in derselben Kategorie auf einen Tiefstwert von lediglich 2,2 Prozent. Objektivere Antworten helfen letztendlich, die emotionalen Entscheidungen der Anwender besser abzusichern.