OpenAI veröffentlicht GPT-5.6 mit den Modellen Sol, Terra und Luna
Das stärkste Modell schlägt Mythos 5 in manchen Bereichen und kommt mit einem neuen Ultra Modus.

OpenAI testet die neue Generation GPT-5.6 in einer limitierten Vorschau. Die drei Varianten Sol, Terra und Luna zielen auf unterschiedliche Leistungs- und Preissegmente ab. Sie bringen spezielle Berechnungsmodi für komplexe Aufgabenstellungen und eine verschärfte Sicherheitsarchitektur mit.
Außerdem haben wir hier noch die 76 Seiten der System Card analysiert:
Neue Architektur mit Subagenten
OpenAI führt mit GPT-5.6 eine neue Nomenklatur ein. Die Zahl steht für die technische Generation, während die Namen dauerhafte Leistungsklassen bezeichnen.
Sol bildet das Flaggschiff der Reihe. Terra bewältigt alltägliche Aufgaben und erreicht die Leistung von GPT-5.5 bei halbierten Kosten. Luna stellt die schnellste und günstigste Option dar.
Für anspruchsvolle Berechnungen erhält Sol eine neue »max«-Einstellung. Sie gibt ihm mehr Zeit für komplexe Lösungswege. Zusätzlich führt OpenAI einen »ultra«-Modus ein. Dieser greift auf Subagenten zurück, um umfangreiche Arbeitsabläufe zu beschleunigen.
In Programmier-Szenarien erzielt Sol starke Ergebnisse. Beim TerminalBench 2.1, der Kommandozeilen-Abläufe und Programm-Koordination testet, erreicht Sol im Ultra-Modus 91,9 Prozent. Damit setzt er sich knapp vor Claude Mythos 5.
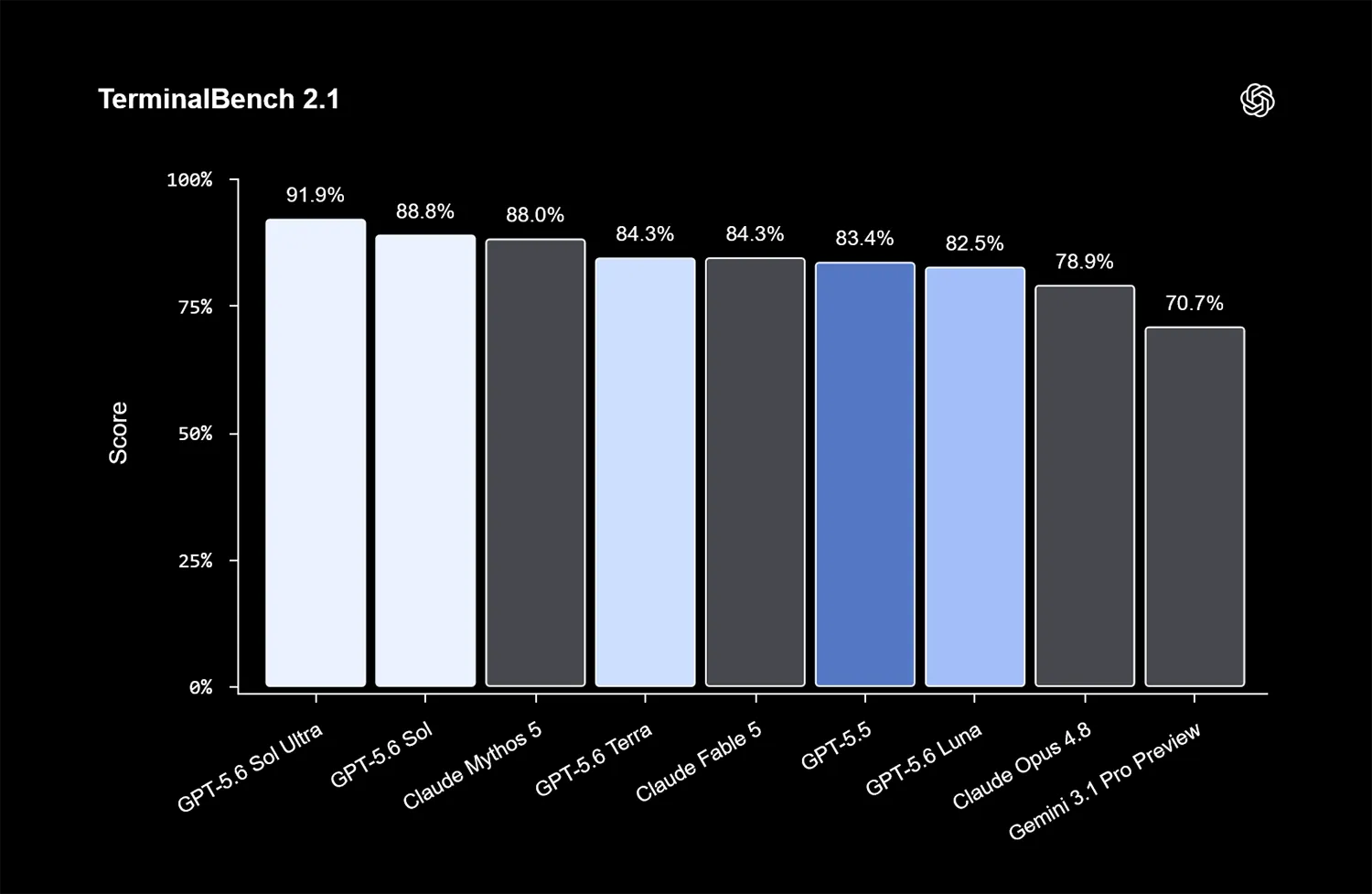
Quelle: OpenAI
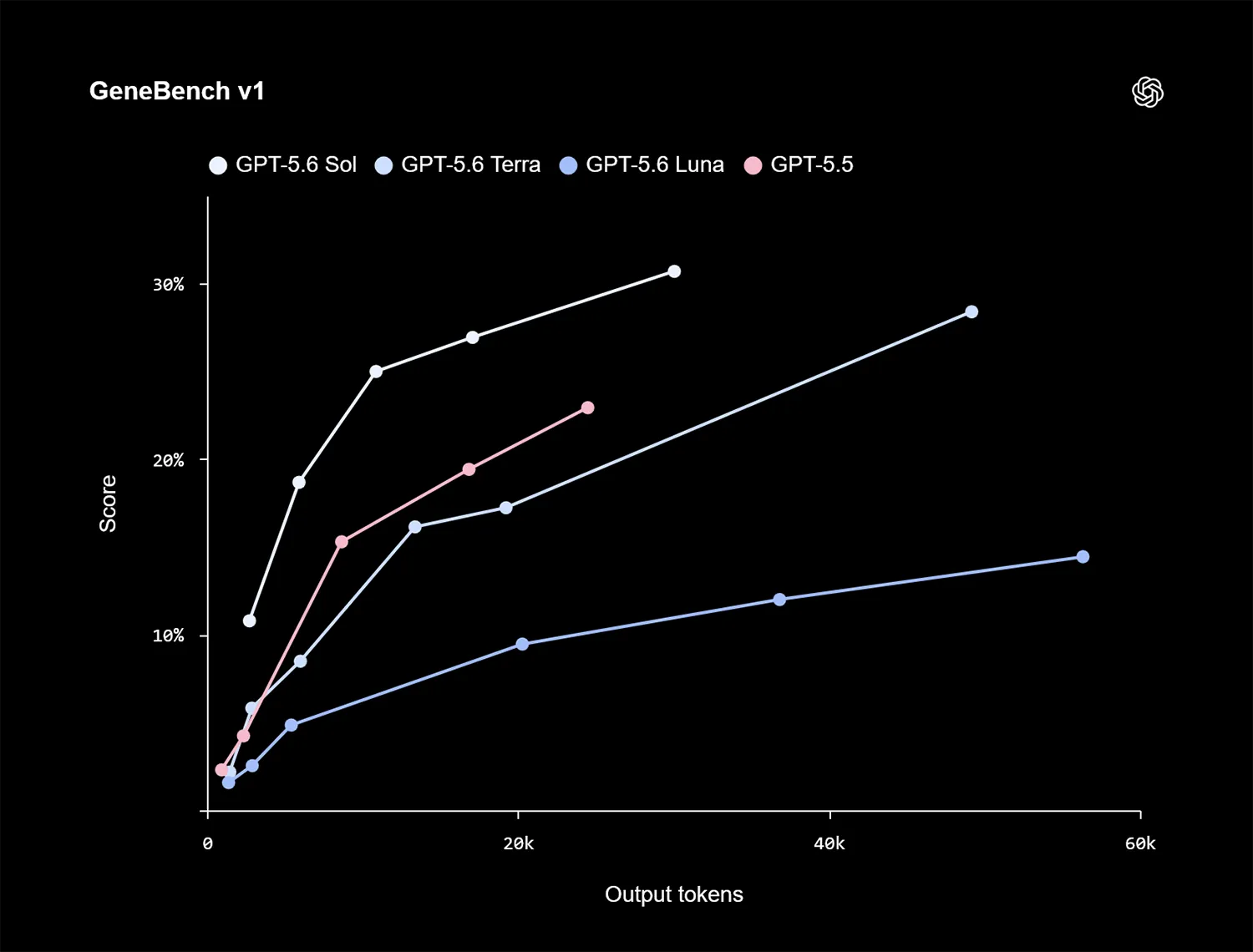
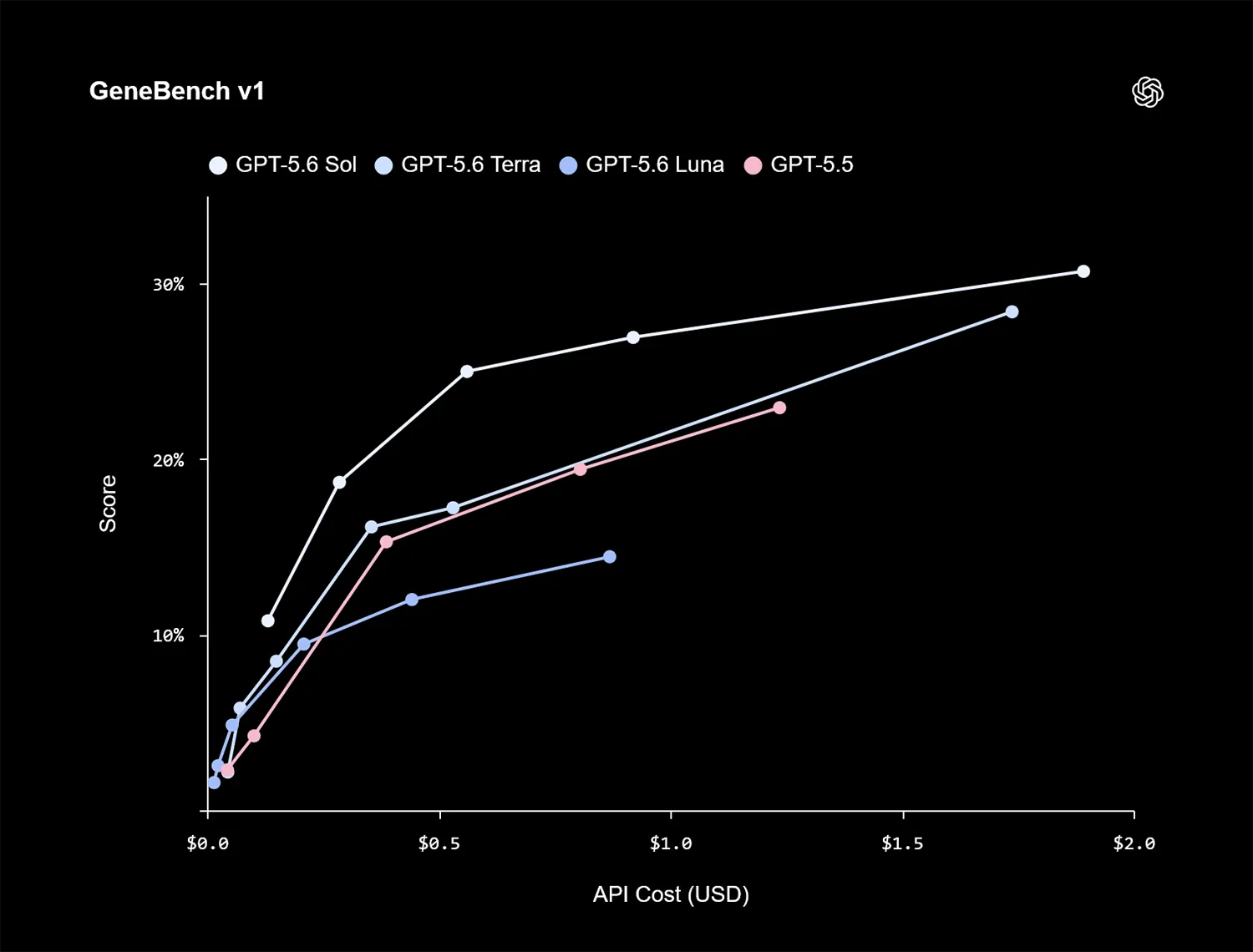
Auch in biologischen Workflows gibt es messbare Fortschritte. Im GeneBench v1 für Langzeitanalysen in der Genomik liefert Sol bessere Ergebnisse als GPT-5.5. Er benötigt dafür außerdem weniger Token.
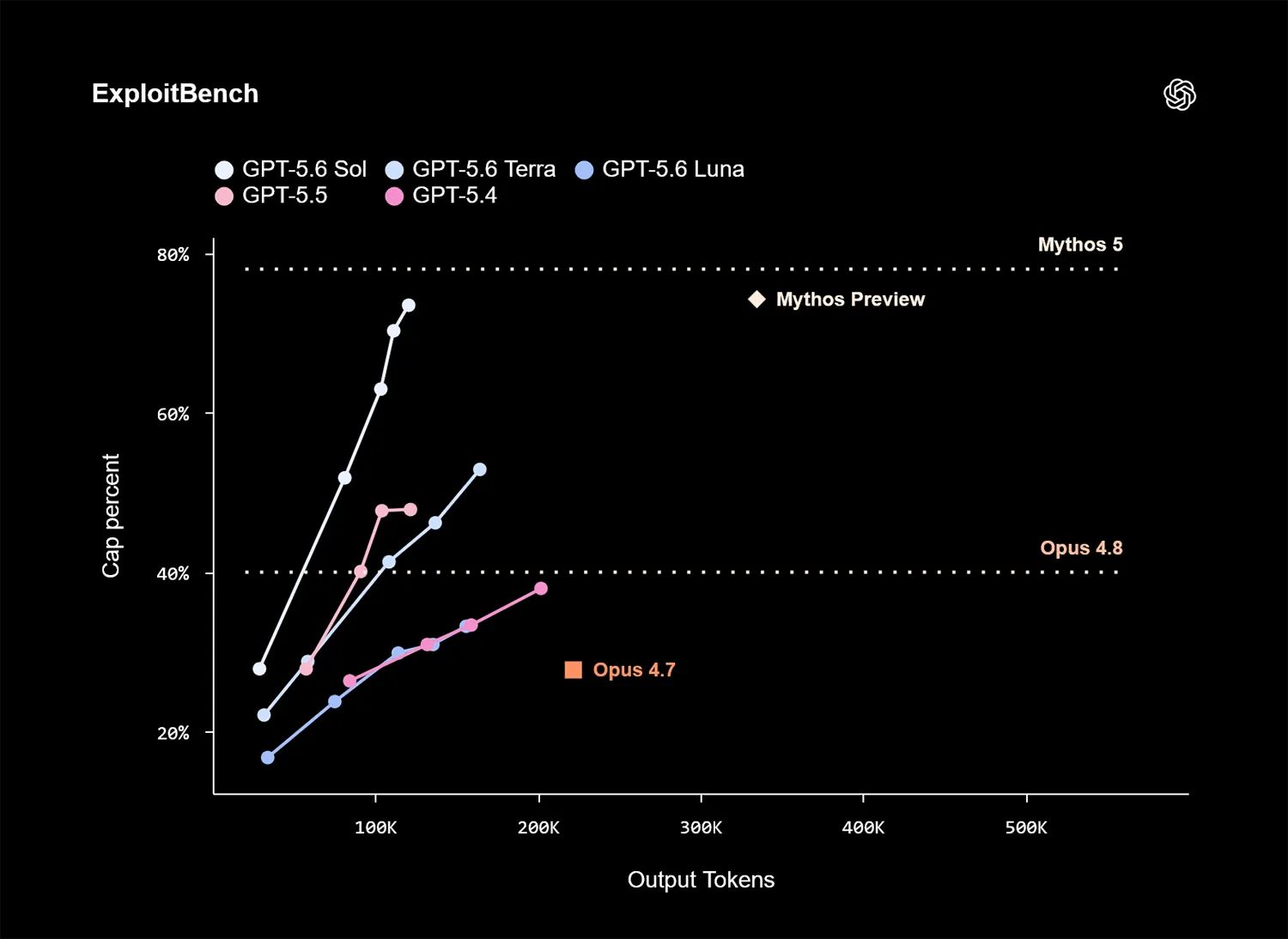
Schwachstellenforschung und Schutzmechanismen
Den größten Leistungssprung verzeichnet Sol in der Cybersicherheit. In der Schwachstellenforschung arbeitet er im ExploitBench ähnlich effizient wie Mythos Preview. Sol verbraucht dabei jedoch nur etwa ein Drittel der Ausgabe-Token.
Quelle: OpenAI
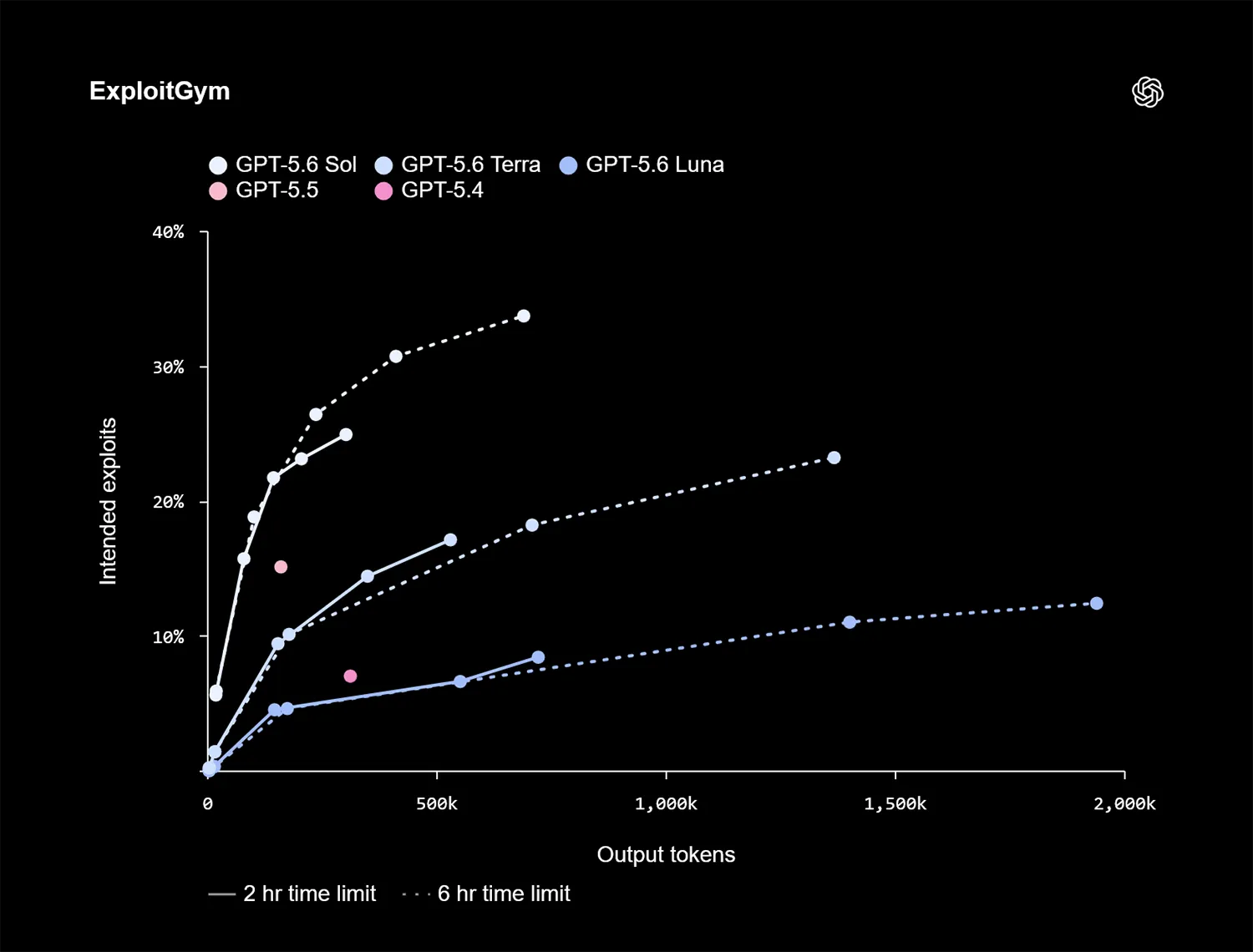
Auch im ExploitGym-Benchmark demonstrieren Sol, Terra und Luna mit steigender Rechenzeit deutliche Verbesserungen. Sol identifiziert Fehler und Exploit-Bausteine in Software wie Chromium oder Firefox. Er schreibt unter Testbedingungen jedoch keine voll funktionsfähigen, durchgehenden Exploits.
Weil Sol leistungsfähiger ist als seine Vorgänger, nutzt OpenAI ein mehrschichtiges Sicherheitssystem. Die Entwickler investierten über 700.000 GPU-Stunden auf A100-Chips in automatisiertes Red-Teaming. Sie suchten dabei gezielt nach universellen Jailbreaks, die über verschiedene Prompts hinweg funktionieren.
Klassifikatoren prüfen Ausgaben in den Bereichen Biologie und Cyber in Echtzeit. Entdeckt eine Kontrollinstanz einen möglichen Verstoß, pausiert die Generierung.
Ein größeres Überprüfungsmodell analysiert dann den Kontext der Unterhaltung. Erkennt es einen verbotenen Inhalt, blockiert es die Ausgabe vorab. Auffällige Aktivitäten können zudem eine manuelle Überprüfung des Nutzerkontos auslösen.
Anzeige
API-Preise und Caching-Funktionen
Entwickler können die drei Varianten über die API nutzen. Die Preise pro Million Token gestalten sich wie folgt:
- Sol: 5,00 US-Dollar (Eingabe) / 30,00 US-Dollar (Ausgabe)
- Terra: 2,50 US-Dollar (Eingabe) / 15,00 US-Dollar (Ausgabe)
- Luna: 1,00 US-Dollar (Eingabe) / 6,00 US-Dollar (Ausgabe)
Entwickler erhalten bei GPT-5.6 mehr Kontrolle über das Prompt-Caching. Sie können Cache-Haltepunkte explizit setzen. Die Mindestspeicherzeit beträgt 30 Minuten.
Das Schreiben in den Cache kostet das 1,25-Fache des normalen Eingabepreises. Beim Auslesen bleibt der bisherige Rabatt von 90 Prozent bestehen.
Derzeit gewährt OpenAI nur einer kleinen Gruppe von vertrauenswürdigen Partnern Zugriff auf Sol, Terra und Luna. Diese Vorschauphase wurde vorab mit der US-Regierung abgestimmt. Das Unternehmen arbeitet kurzfristig mit der Regierung an einem Rahmenwerk für künftige Veröffentlichungen, betont jedoch, dass dieser Prozess nicht der dauerhafte Standard bleiben soll.
In den kommenden Wochen sollen Sol, Terra und Luna für alle Nutzer in ChatGPT, Codex und der API verfügbar sein. Ab Juli läuft Sol zusätzlich auf spezieller Cerebras-Hardware. Dort soll er für ausgewählte Kunden Geschwindigkeiten von bis zu 750 Token pro Sekunde erreichen.





