OpenAI API wird bis zu 40% schneller
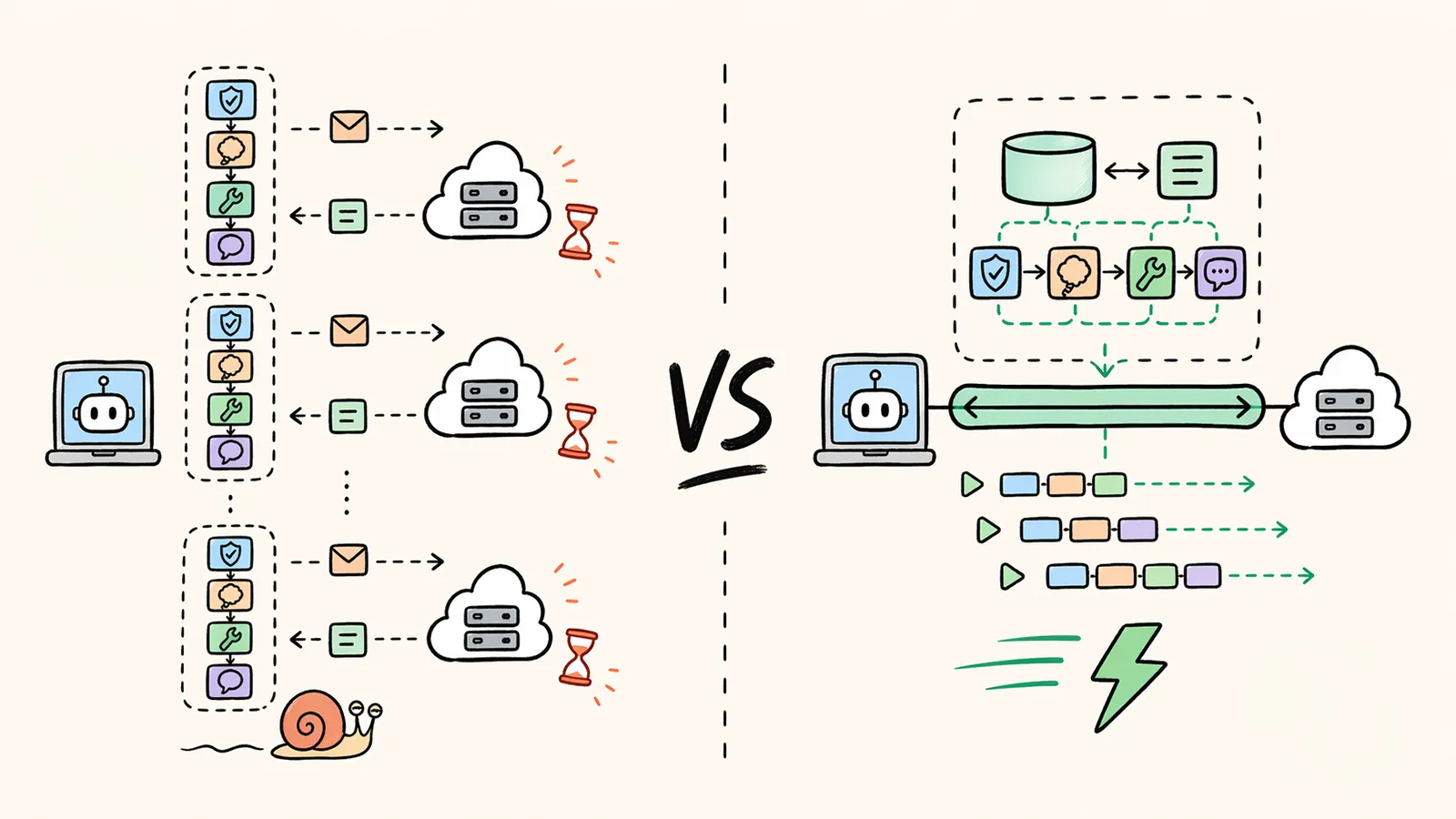
Mit einer Umstellung der Responses API auf persistente Verbindungen beschleunigt OpenAI komplexe Agenten-Workflows um bis zu 40 Prozent.

OpenAI integriert WebSockets in die Responses API und senkt damit die Latenz bei Agenten-Workflows um beachtliche 40 Prozent. Durch neue persistente Verbindungen generieren Modelle wie GPT-5.3-Codex nun ohne API-Verzögerung bis zu 4.000 Token pro Sekunde.
Schnittstellen bremsen schnelle Hardware
Bei der autonomen Fehlersuche analysieren KI-Modelle fremden Code, schreiben funktionale Anpassungen und führen direkt Tests aus. Dieser ständige Austausch zwischen Client und Server verursachte in der Vergangenheit kaum spürbare Verzögerungen für den Anwender. Ältere Modelle wie GPT-5 berechneten ohnehin nur rund 65 Token pro Sekunde. Da die reine Rechenzeit ohnehin den Großteil der Dauer beanspruchte, fiel der Overhead der Schnittstelle kaum ins Gewicht.
Das änderte sich mit der Einführung von GPT-5.3-Codex-Spark grundlegend. Spezialisierte Cerebras-Hardware beschleunigt die Modell-Inferenz derart, dass die KI im Hintergrund über 1.000 Token pro Sekunde generiert. Plötzlich verbrachten Nutzer wertvolle Zeit in der Warteschlange der API-Dienste, bevor die Grafikprozessoren überhaupt rechneten. Klassische HTTP-Anfragen stießen bei dieser Geschwindigkeit an architektonische Grenzen.
Anzeige
Konstante Verbindung schont Ressourcen
Bisher behandelte das System jede Anfrage eines Agenten als komplett eigenständigen Vorgang. Entwickler schickten bei jedem Schritt den vollständigen Gesprächsverlauf erneut an die Server. Das verursachte unzählige redundante Berechnungen. Die Software musste den gesamten Kontext immer wieder neu validieren. Mit wachsender Länge der Konversationen stiegen diese unnötigen Latenzen spürbar an.
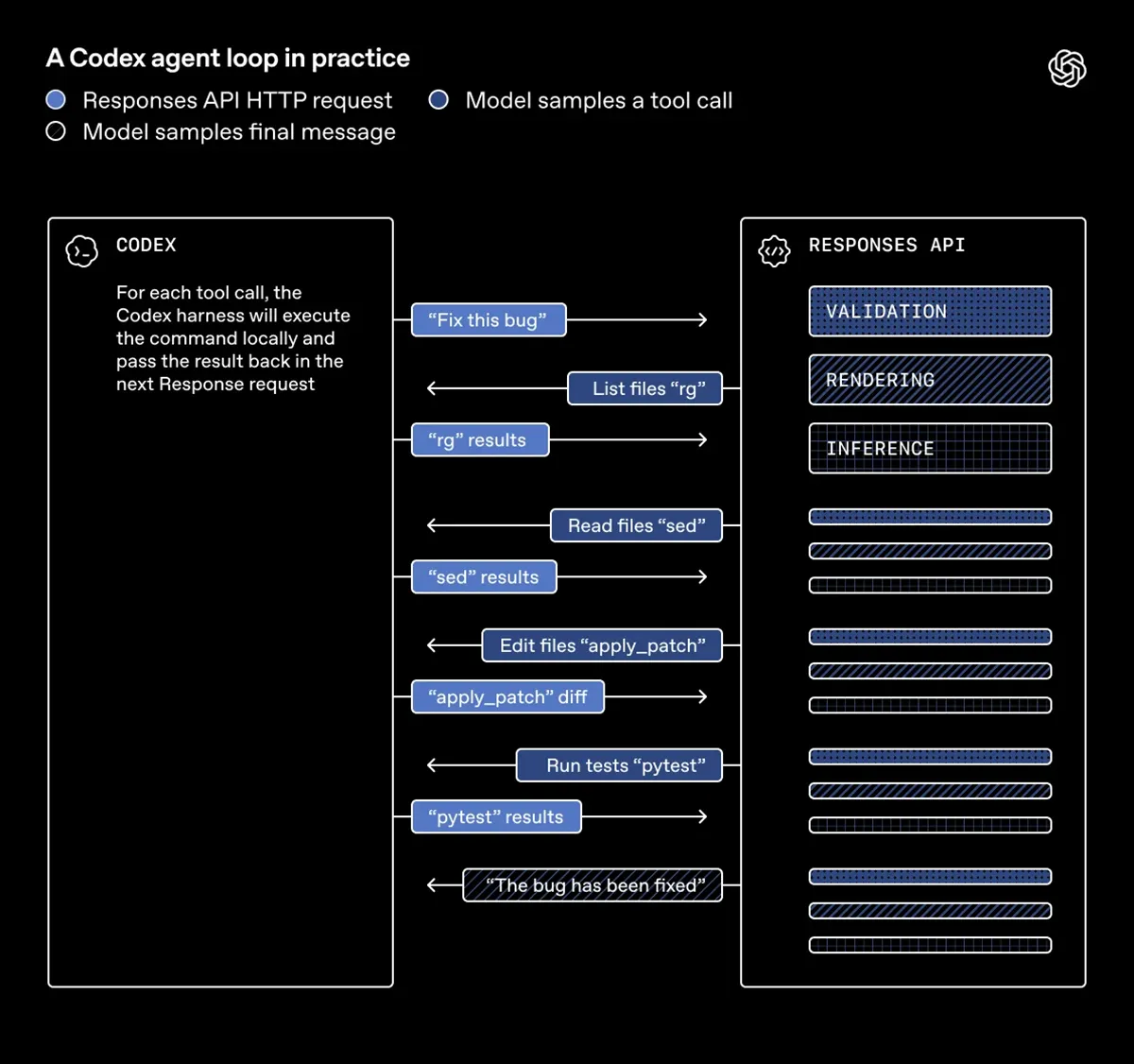
Quelle: OpenAI
Um dieses Problem zu umgehen, wechselte das Team zu einer persistenten WebSocket-Verbindung. Anstatt bei jedem Schritt von vorne zu beginnen, behält der Server nun einen Zwischenspeicher des bisherigen Verlaufs direkt im Arbeitsspeicher. Folgt eine weitere Aktion, ruft die API diesen Status blitzschnell ab. Ein früher Prototyp veränderte laut den Entwicklern bereits das Verständnis davon, »was für die API-Latenz möglich ist«.
Dieser smarte Ansatz überspringt unnötige Netzwerksprünge und aufwendige Tokenisierungs-Prozesse konsequent. Sicherheitsmechanismen prüfen folglich nur noch die frischen Eingaben, was bei jedem Aufruf Millisekunden spart. Gleichzeitig sendet die API nun die Ergebnisse lokaler Tools direkt über den WebSocket zurück in den Modellkontext.
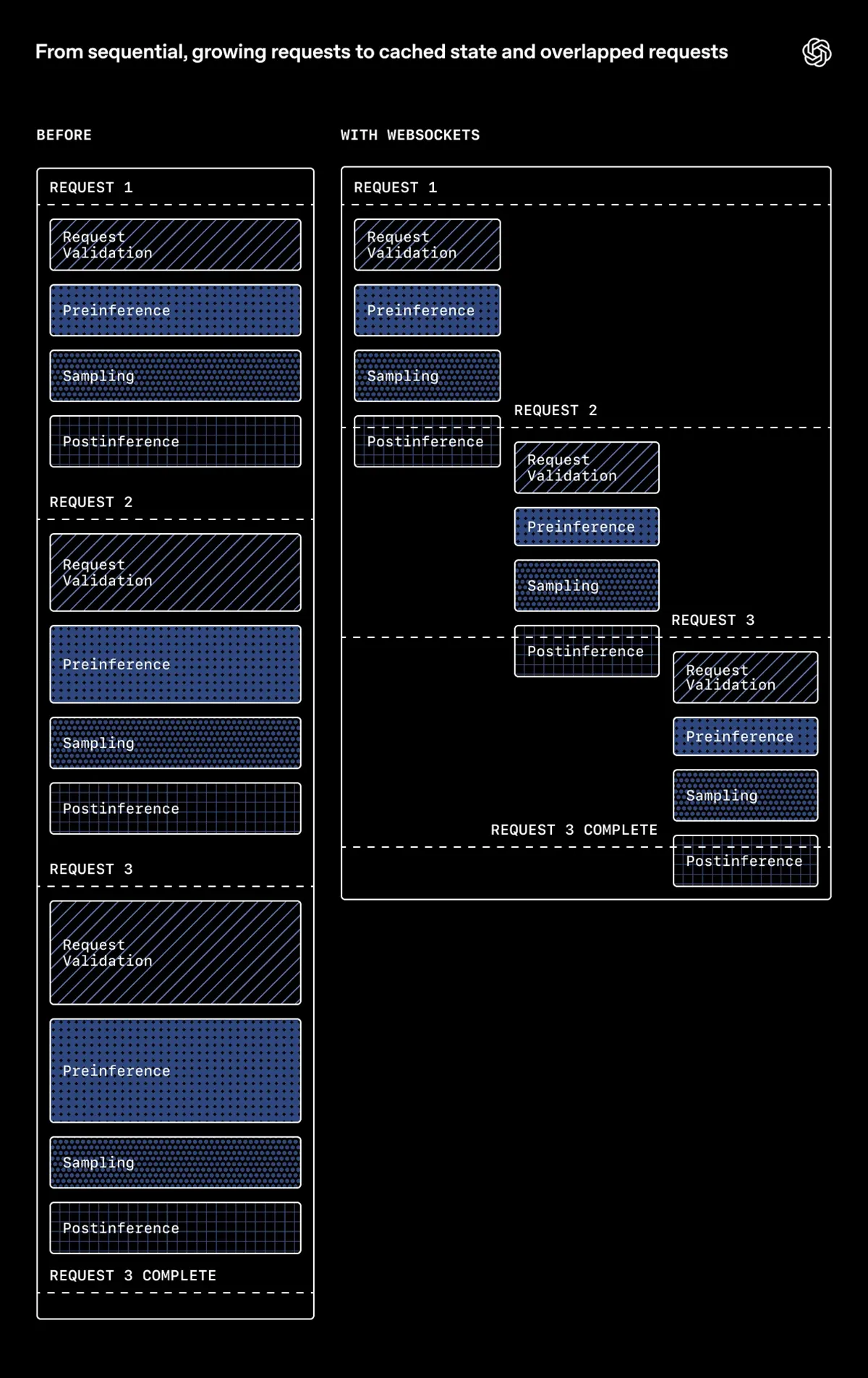
Quelle: OpenAI
Spürbare Effekte für Drittanbieter
Erste Praxistests dokumentieren handfeste Verbesserungen der finalen Reaktionszeiten. Die Modelle erreichen mühelos das Ziel von 1.000 generierten Token pro Sekunde und verzeichnen in Spitzenzeiten sogar bis zu 4.000 Token. Davon profitieren aktuell insbesondere Nutzer der Modellgenerationen GPT-5.3-Codex und GPT-5.4.
Zahlreiche Drittanbieter verzeichnen nach der Umstellung ebenfalls messbare Leistungssprünge in ihren eigenen Diensten. Der Code-Assistent Cursor arbeitet nun bis zu 30 Prozent schneller. Vercel meldet nach der Integration in das hauseigene AI SDK einen Latenzrückgang von satten 40 Prozent. Auch die komplexen Workflows des Dienstes Cline schließen anstehende Aufgaben 39 Prozent zügiger ab. Dieser technische Umbau eliminiert den strukturellen Flaschenhals der alten Schnittstelle. Zukünftige Leistungsreserven der Hardware kommen somit wieder direkt beim Anwender an.