
NVIDIA GB300 NVL72: 35-fach geringere Token-Kosten
Der neue Blackwell Ultra Chip zeigt in Benchmarks drastische Leistungssteigerungen bei der Inferenz von DeepSeek-R1.

NVIDIA präsentiert neue Leistungsdaten für sein GB300 NVL72 Rack-System. Die Blackwell Ultra Architektur liefert bei dem Reasoning-Modell DeepSeek-R1 bis zu 50-mal mehr Tokens pro Watt und senkt die Kosten im Vergleich zu älteren Hopper-GPUs um das 35-fache.
Fokus auf Agentic AI und Effizienz
NVIDIA richtet das neue System explizit auf komplexe KI-Aufgaben und Agentic AI aus. Diese modernen Anwendungen arbeiten zunehmend selbstständig und analysieren oft umfangreiche Code-Basen am Stück. Das erfordert extrem lange Kontextfenster und zieht eine hohe Rechenlast nach sich. Der GB300 NVL72 fängt diese Anforderungen hardwareseitig ab.
Das System vernetzt 72 Blackwell Ultra GPUs in einem einzigen flüssigkeitsgekühlten Rack. NVIDIA stattet jede GPU mit 288 Gigabyte schnellem HBM3e-Speicher aus.
Ein NVLink-Netzwerk mit einer Bandbreite von 130 Terabyte pro Sekunde verbindet die Chips untereinander. Der gesamte Verbund agiert dadurch bei großen Workloads als zusammenhängende Recheneinheit.
Ein zentraler Baustein für den Leistungssprung ist die Nutzung des NVFP4-Datenformats. Es quantisiert die Parameter der Modelle effizient und beschleunigt die reine Rechengeschwindigkeit bei der Inferenz spürbar. NVIDIA kombiniert diese Hardware-Basis mit tiefgehenden Software-Optimierungen im eigenen Stack.
Anzeige
Die Benchmarks im Detail
Die aktuellen Leistungstests konzentrieren sich stark auf das Open Source Modell DeepSeek-R1. Die veröffentlichten Diagramme zeigen hier deutliche Sprünge. Gegenüber einem älteren H200-System sinken die Kosten pro Million Tokens bei einem Standard-Kontext (1k/1k) um den Faktor 35.
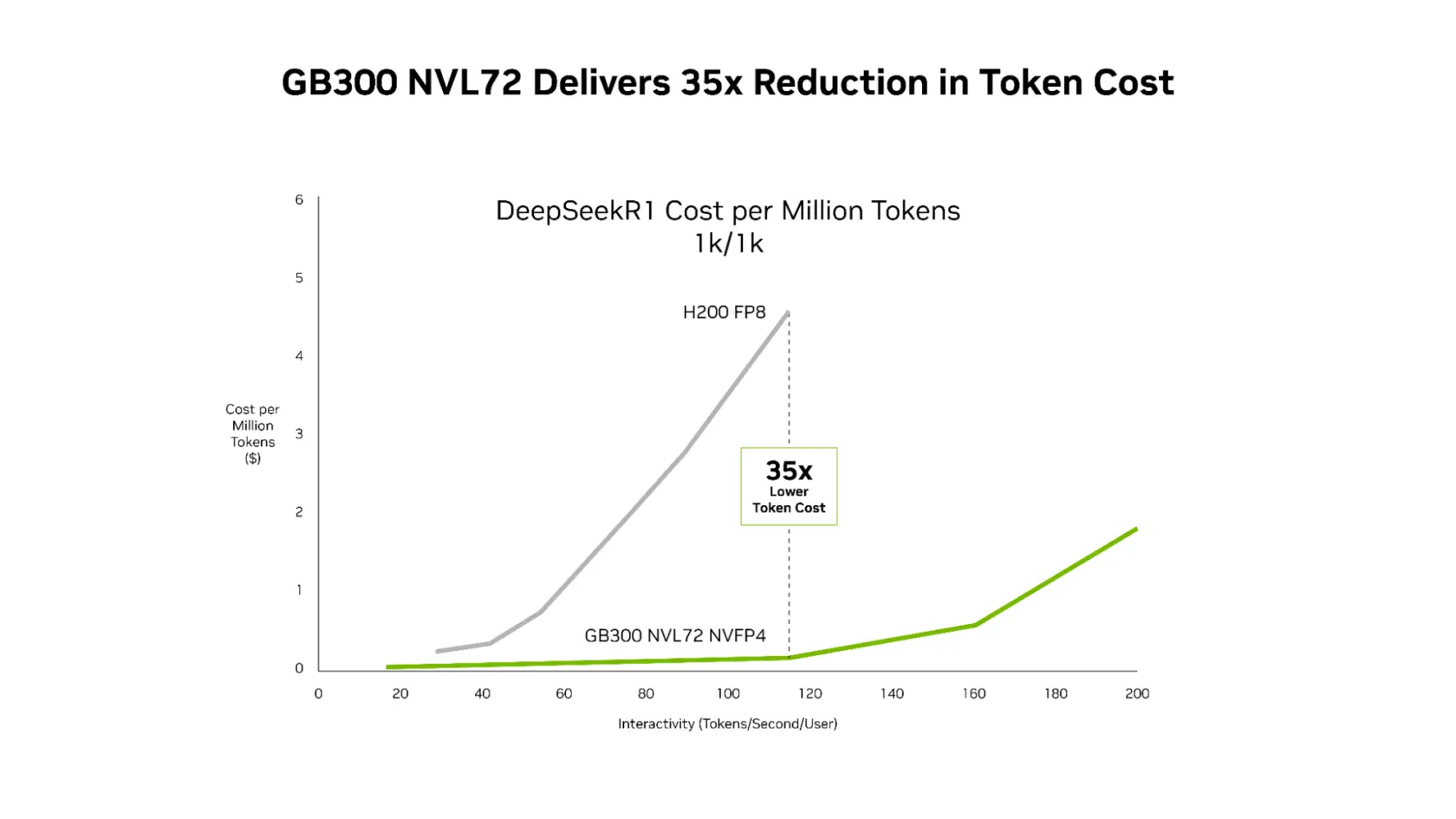
Quelle: Nvidia
Gleichzeitig steigt die Energieeffizienz stark an. Der Blackwell Ultra Cluster generiert 50-mal mehr Tokens pro Watt als die Hopper-Generation.
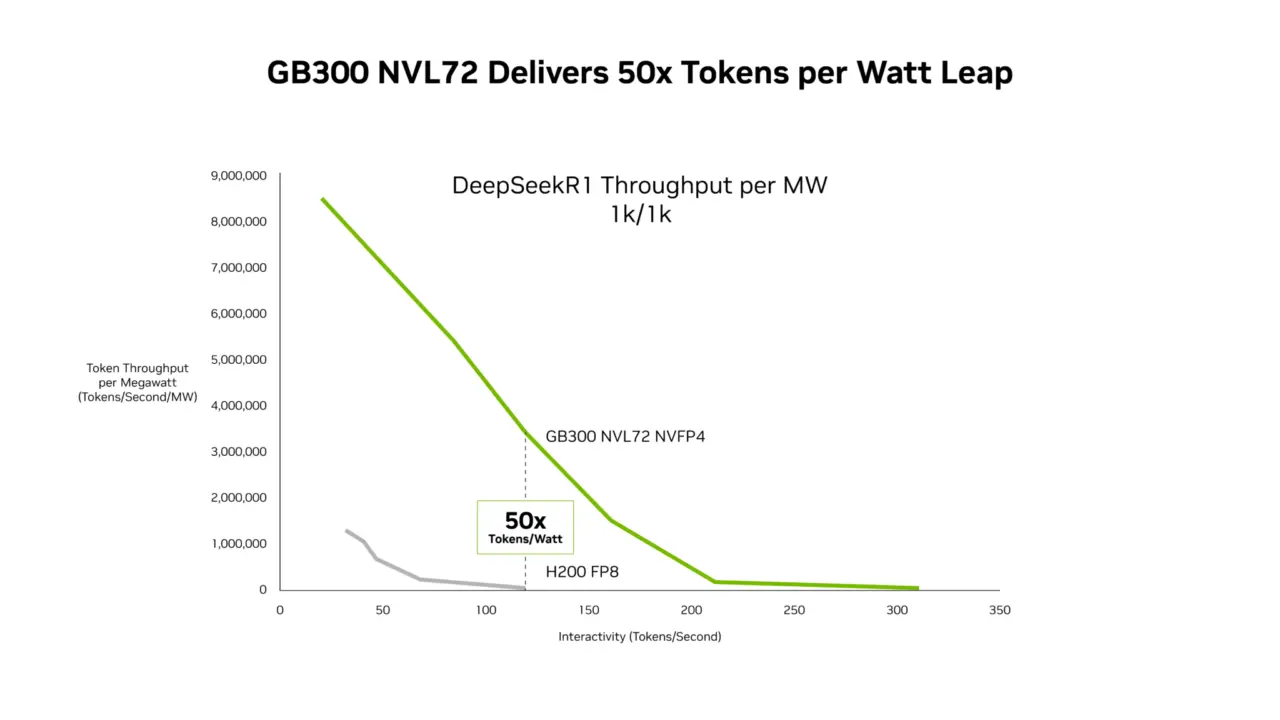
Quelle: Nvidia
Auch der interne Generationsvergleich verdeutlicht den Fortschritt. Gegenüber dem Vorgänger, dem GB200 NVL72, sinken die Token-Kosten bei sehr langen Kontexten (128k/8k) noch einmal um das 1,5-fache.
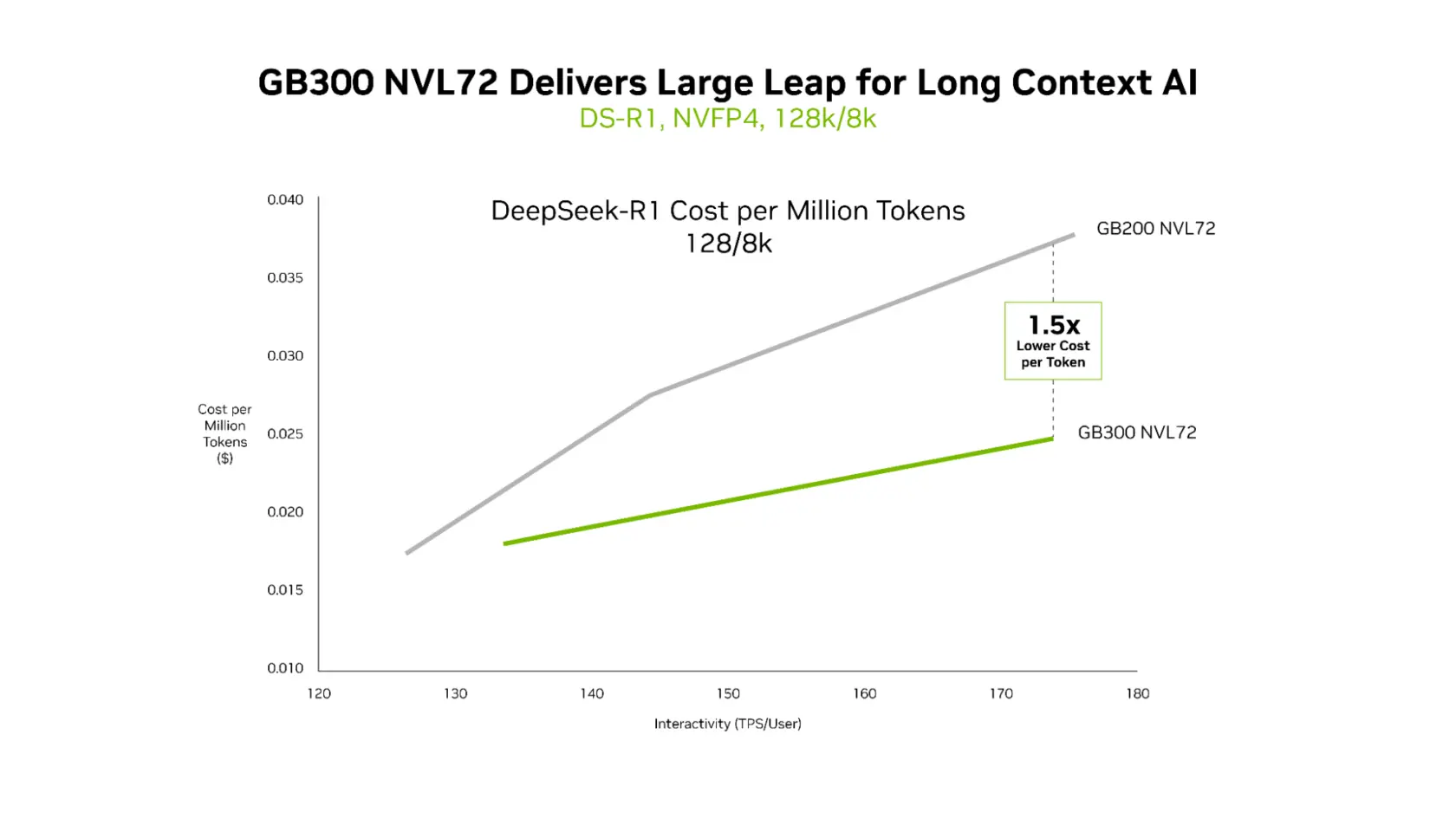
Quelle: Nvidia
Solche langen Prompts belasten normalerweise den Speicher stark und treiben die Kosten für Cloud-Anbieter in die Höhe.
Dieses Hardware-Setup adressiert exakt die aktuellen Herausforderungen großer Rechenzentren. Reasoning-Modelle wie DeepSeek-R1 benötigen während der Textgenerierung deutlich mehr Zeit und Rechenkraft, da sie interne Denkprozesse abbilden. Durch die Kombination aus hohem Speicherausbau und extrem schneller Vernetzung bewältigt der GB300 diese komplexen Inferenz-Aufgaben sehr effizient. Die neuen Racks bilden die physische Basis für kommende Rechenzentren und setzen den aktuellen technischen Standard.