
Warum das beste GPT-Modell nicht das neueste ist
Die Auswertung hunderter Test-Prompts offenbart erstaunliche Leistungsunterschiede. Eine bestimmte Architektur setzt sich klar von der Konkurrenz ab.
OpenAI veröffentlicht mit den Model Spec Evals erstmals konkrete Benchmarks zur Regeltreue aktueller KI-Modelle. Die Auswertungen vom März 2026 zeigen ein unerwartetes Ergebnis. Das ältere GPT-5 Thinking schlägt das neue Flaggschiff GPT-5.4 Thinking messbar.
Transparenz durch neue Testverfahren
Ein Datensatz aus 596 spezifischen Prompts testet systematisch 225 Verhaltensregeln der internen Richtlinien ab. Diese Vorgaben definieren bei jeder generierten Antwort einen angemessenen Sprachstil, die präzise Faktenwiedergabe und den exakten Umgang mit sensiblen Anfragen.
Die Entwickler gleichen die Antworten der KI-Modelle mit festgelegten Bewertungsmaßstäben ab, um eine messbare Compliance-Rate zu ermitteln. Ein automatisiertes Verfahren nutzt dabei das Modell GPT-5 Thinking als unbestechlichen Richter, der die generierten Texte der Testreihen auf einer Skala von 1 bis 7 bewertet.
Anzeige
Die Testergebnisse im Detail
Die Zahlen belegen einen übergreifenden Aufwärtstrend seit dem Release von GPT-4o im Mai 2024, bergen jedoch eine Anomalie an der Leistungsspitze. Das im August 2025 veröffentlichte GPT-5 Thinking erreicht mit 89 Prozent die höchste Trefferquote im Test.
Es verweist das aktuelle Topmodell GPT-5.4 Thinking aus dem März 2026 auf den zweiten Platz. Dieses erzielt exakt 87 Prozent. In der Kategorie für die höchste generelle Arbeitsqualität klafft sogar eine markante Lücke von knapp 30 Prozentpunkten zwischen dem Spitzenwert und deutlich älteren Architekturen.
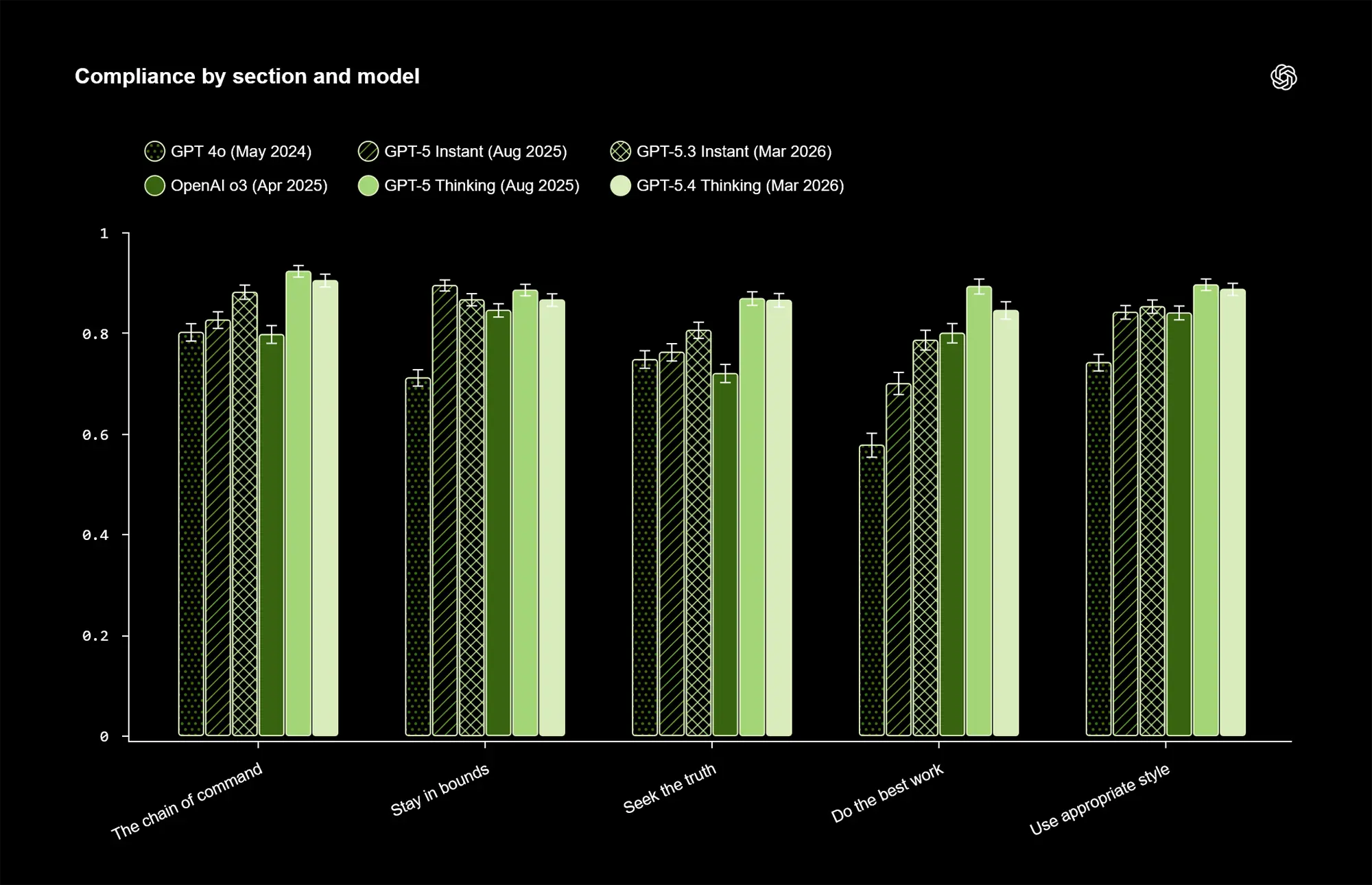
Quelle: OpenAI
Architektur entscheidet über Gehorsam
Die vorliegenden Daten zeigen branchenweit, dass KI-Modelle mit integriertem Reasoning den rein kompakten Varianten überlegen sind. Das aktuelle GPT-5.3 Instant erreicht beispielsweise lediglich 84 Prozent und ordnet sich deutlich hinter den analytisch arbeitenden Modellen ein.
Trotz der generell hohen Wertungen offenbaren die Tests strukturelle Schwächen im derzeitigen Fine-Tuning. Die Systeme neigen in speziellen Rand-Szenarien dazu, den Nutzer leicht zu bevormunden oder wesentlich mehr Informationen zu generieren, als der initiale Prompt verlangte. Die Forscher planen für die kommenden Monate eine kontinuierliche Erweiterung des Prüfstands auf multimodale Eingaben.