
Warum Roboter jetzt selbstständig Programmcode ausführen
Ein technisches Upgrade verleiht KI-Systemen eine neue Fähigkeit für die Überwachung von physischen Instrumenten.

Google veröffentlicht das neue KI-Modell Gemini Robotics-ER 1.6. Das System stattet Roboter mit einem erweiterten Embodied Reasoning aus, wodurch sie physische Umgebungen genauer analysieren und komplexe Aufgaben wie das Ablesen von analogen Instrumenten selbstständig übernehmen.
Agentic Vision liest analoge Anzeigen
Für den industriellen Einsatz kooperiert Google mit Boston Dynamics. Deren Laufroboter Spot nutzt die neuen Fähigkeiten, um Manometer, Schaugläser und digitale Anzeigen präzise zu interpretieren. Das KI-Modell greift dafür auf die sogenannte Agentic Vision zurück. Diese Funktion kombiniert visuelles Reasoning direkt mit der Ausführung von Programmcode.
Die Software zoomt bei Bedarf selbstständig an kleine Details einer analogen Anzeige heran. Anschließend schätzt es Proportionen oder Abstände zwischen Markierungen ein, um einen genauen Messwert zu ermitteln. Bei Tests zum Instrumentenlesen erreicht Gemini Robotics-ER 1.6 in Kombination mit Agentic Vision eine Erfolgsquote von 93 Prozent. Zum Vergleich: Das ältere Modell Gemini Robotics-ER 1.5 lag bei dieser Aufgabe noch bei 23 Prozent.
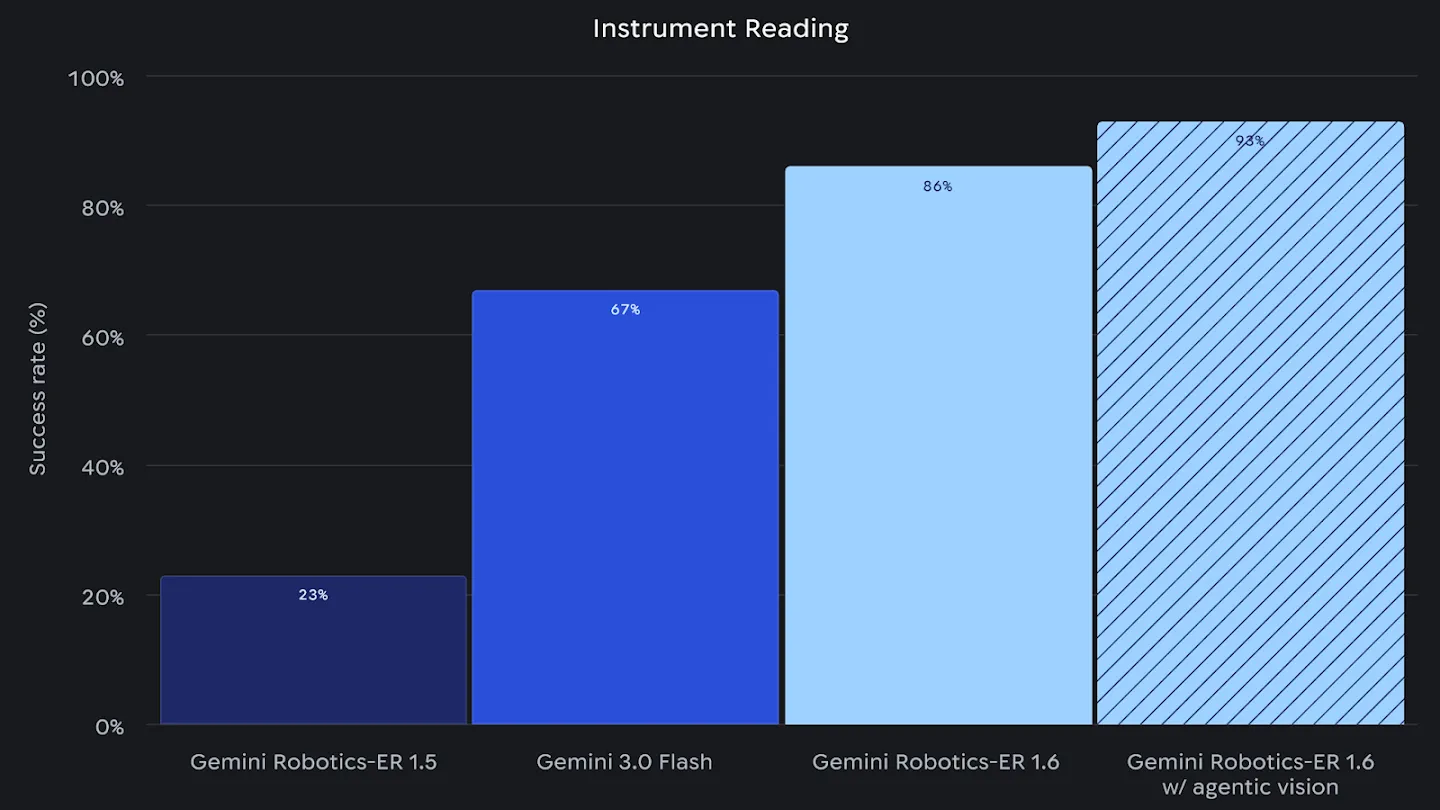
Quelle: Google
Räumliche Logik und Fehlerkontrolle
Neben dem Ablesen von Daten liefert das System messbare Verbesserungen bei der grundlegenden räumlichen Wahrnehmung. Beim Pointing und Counting, also dem präzisen Zeigen auf und Zählen von bestimmten Objekten in einer Umgebung, erzielt das KI-Modell eine Genauigkeit von 80 Prozent. Die Entwickler haben zudem die Erkennung von erfolgreichen Aufgabenabschlüssen optimiert.
Roboter werten nun Bilder aus verschiedenen Kameraperspektiven gleichzeitig aus. Das System versteht dadurch besser, ob eine Handlung wie das Greifen und Ablegen eines Gegenstands tatsächlich abgeschlossen ist oder ein neuer Versuch starten muss. Bei dieser Multiview-Auswertung verzeichnet das Modell eine Erfolgsquote von 84 Prozent und übertrifft das Standardmodell Gemini 3.0 Flash deutlich.
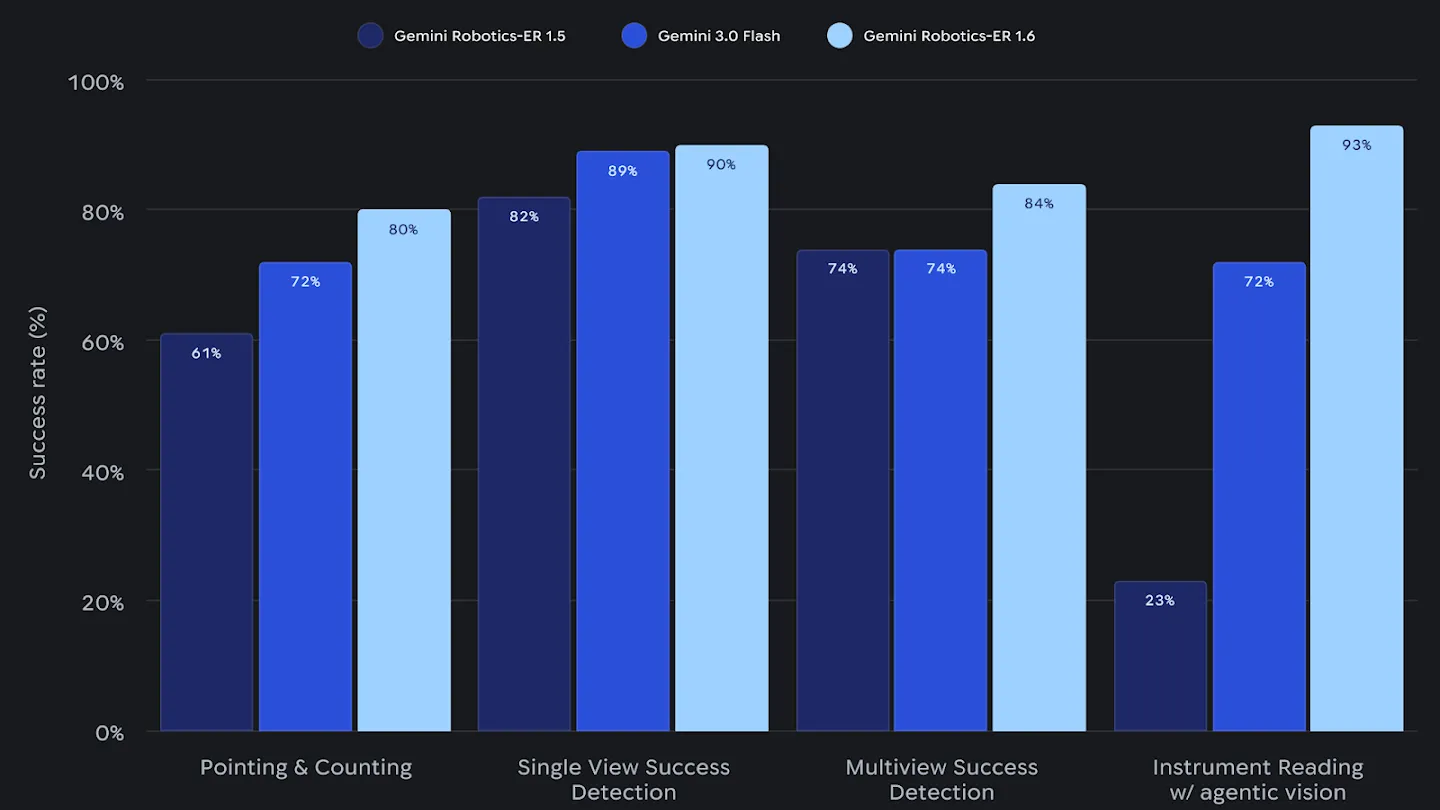
Quelle: Google
Sicherheitsvorgaben und Verfügbarkeit
Ein weiterer Schwerpunkt liegt auf der strikten Einhaltung physischer Sicherheitsvorgaben. Das Modell entscheidet anhand räumlicher Daten verlässlicher, welche Objekte ein Greifarm sicher manipulieren darf. So hält das System spezifische Materialbeschränkungen ein und vermeidet beispielsweise den Umgang mit Flüssigkeiten oder zu schweren Gegenständen. Die Erkennung von Verletzungsrisiken auf Videomaterial stieg im Vergleich zu Gemini 3.0 Flash um zehn Prozent.
Entwickler greifen ab sofort über die Gemini API sowie das Google AI Studio auf Gemini Robotics-ER 1.6 zu. Für den schnellen Einstieg steht ein Entwickler-Colab bereit. Dieses enthält konkrete Beispiele, wie sich das Modell für spezifische Aufgaben im Bereich Embodied Reasoning konfigurieren und prompten lässt.